今日の論文2023/06/03:Brain-inspired learning in artificial neural networks: a review
Brain-inspired learning in artificial neural networks: a review
Schmidgall, Samuel, Jascha Achterberg, Thomas Miconi, Louis Kirsch, Rojin Ziaei, S. Hajiseyedrazi, and Jason Eshraghian. "Brain-inspired learning in artificial neural networks: a review." arXiv preprint arXiv:2305.11252 (2023).
©2023 The Authors
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容の一部を私が翻訳したものです。以下の図は、そこから引用しています。
This article is my translation of a portion of the contents of the original publication. The following figures are taken from it.
要点まとめ
人工ニューラルネットワーク(ANN)は、機械学習の必須ツールとして登場し、画像や音声の生成、ゲームプレイ、ロボット工学など、さまざまな領域で目覚ましい成果を上げている。しかし、ANNの動作メカニズムと生物学的な脳の動作メカニズムとの間には、特に学習プロセスに関して根本的な違いがある。本稿では、人工ニューラルネットワークにおける脳を用いた学習表現について包括的にレビューし、シナプス可塑性など、より生物学的に妥当なメカニズムの統合による人工ニューラルネットワークの機能強化について検討する。 さらに、このアプローチに伴う潜在的な利点と課題を掘り下げる。そして、知能の本質の解明に近づくために、この急速に進展している分野における今後の研究の有望な道筋を明らかにするものである。
序論
記憶と学習のダイナミックな相互関係は、知的な生物システムの基本的な特徴であり、生物は新しい知識を吸収するだけでなく、既存の能力に絶えず磨きをかけ、変化する環境条件に巧みに対応することができる。生物は、新しい知識を吸収するだけでなく、既存の能力を継続的に向上させ、変化する環境条件に巧みに対応することができる。この適応特性は、長期的な学習と短期的な可塑性メカニズムによる急速な短期学習の両方を含むさまざまな時間スケールで関連し、生物神経系の複雑さと適応性を際立たせている。脳からハイレベルで階層的なインスピレーションを得る人工システムの開発は、数十年にわたる長年の科学的課題であった。しかし、最近の人工知能(AI)アルゴリズムは、多くの困難な課題において、大きなブレークスルーを達成している。このようなタスクには、人間が提供したプロンプトから画像やテキストを生成すること、複雑なロボットシステムの制御、ChessやGoなどの戦略ゲームの習得、これらのマルチモーダルな融合が含まれているが、これらに限定されない。
ANNは様々な分野で大きな進歩を遂げてきたが、生物の脳のように継続的に学習し適応する能力には、まだ大きな限界が残っている。現在の機械知能のモデルとは異なり、動物は寿命を通じて学習することができ、これは変化する環境に安定して適応するために不可欠である。この能力は生涯学習(lifelong learning)として知られているが、固定されたラベル付きデータセットからなる問題を主に最適化する人工知能にとっては大きな課題であり、新しいタスクへの生成や繰り返し学習する際の情報保持に苦労する原因となっている。この課題への取り組みは活発な研究分野であり、生涯学習能力を持つAIを開発することの潜在的な意味は、複数の領域にわたって広範囲な影響を及ぼす可能性がある。
本稿では、現在の人工知能アルゴリズムに影響を与えた脳のメカニズムを特定しようとするユニークなレビューを提供する。自然知能の基礎となる生物学的プロセスをよりよく理解するために、第1章では、シナプス可塑性から、神経活動を形成するローカルおよびグローバルダイナミクスの役割まで、神経調節を形作る低レベルの構成要素を探求する。 第3章では、ANNと生物学的な神経システムを比較・対照することで、ANNに話を戻す。これにより、現在の人工モデルの継承を超えて、脳がAIに提供できるものがあることを正当化しようとする論理的根拠を得ることができる。 続いて、AIシステムの能力を向上させるために、これらのプロセスをエミュレートする人工学習のアルゴリズムについて掘り下げる。 最後に、これらのAI技術の実世界での様々な応用例を取り上げ、ロボット工学、生涯学習、ニューロモルフィックコンピューティングなどの分野への潜在的な影響を強調する。これにより、生物学的な脳の学習メカニズムと人工知能の相互作用について包括的に理解し、この相乗的な関係から生じる潜在的な利益を強調することを目的としている。私たちは、私たちの発見が、脳から着想を得た新世代の学習アルゴリズムを後押しすることを期待している。
脳内で学習をサポートするプロセス
ニューロサイエンスにおける壮大な努力は、脳における学習の根源的なプロセスを明らかにすることを目的としている。シナプスから集団レベルの活動まで、さまざまな粒度で学習の生物学的基盤を説明するために、いくつかの仕組みが提案されてきた。しかし、生物学的に妥当な学習モデルの大半は、局所的な事象と大域的な事象の相互作用から生じる可塑性を特徴としている。以下では、様々な形の可塑性 を紹介し、これらのプロセスがどのように相互作用するかを詳しく説明する。
シナプス可塑性:脳の可塑性とは、経験によって神経回路の機能を変化させる能力のことで、特にシナプスの可塑性は、活動に基づいてシナプス伝達の強さを変化させることを指し、脳が新しい情報に適応するメカニズムとして、現在最も広く研究されている。シナプス可塑性には、短期可塑性と長期可塑性という2つの分類がある。短期可塑性は、数十ミリ秒から数分のスケールで作用し、感覚刺激に対する短期的な適応や短期間の記憶形成に重要な役割を果たす。 長期可塑性は、数分から数十分のスケールで作用し、長期的な行動変化や記憶の保存の基礎となる主要なプロセスの一つであると考えられている。
神経調節:シナプスの可塑性に加えて、脳が新しい情報に適応するもう一つの重要なメカニズムは、神経調節である。神経調節とは、神経伝達物質やホルモンと呼ばれる化学的なシグナル伝達分子によって、神経活動を制御することである。これらのシグナル伝達分子は、神経回路の興奮性やシナプスの強さを変化させ、神経機能に短期的および長期的な影響を与えることができる。神経調節には、アセチルコリン、ドーパミン、セロトニンなどさまざまな種類があり、これらは、注意力、学習、感情などさまざまな機能に関連していることが確認されている。また、神経調節は、短期・長期の可塑性を含む様々な形態の可塑性に関与していることが示唆されている。
メタ弾力性:神経細胞が活動に基づいてその機能と構造を変化させる能力は、シナプス可塑性を特徴づけるものである。シナプスで起こるこれらの変化は、適切な時間に適切な量の変化が起こるように、正確に組織化されなければならない。この可塑性の調節は、メタ可塑性、あるいは「シナプス可塑性の可塑性」と呼ばれ、絶えず変化する脳をそれ自体の飽和から守るために重要な役割を果たしている。基本的に、メタ可塑性は、ニューロンやシナプスの生理的な状態の変化を引き起こすことによってシナプスの可塑性を生み出す能力を変える。メタ可塑性は、記憶の安定性、学習、神経興奮性の制御における基本的なメカニズムとして提唱されている。メタ可塑性は、シナプスが変化する過程でメタ可塑性イベントと神経調節イベントが時間的に重なることが多く、類似しているが、神経調節と区別することができる。
神経新生:新しく形成された神経細胞が既存の神経回路に統合される過程を神経新生という。神経新生は胚発生期に最も活発に行われるが、成体になってからも、特に側脳室下帯、扁桃体、海馬形成の変性回で起こることが知られている。成体マウスでは、標準的な実験室での生活と比較して、豊かな環境での生活で神経新生が増加することが証明されている。また、運動やストレスなどの多くの環境因子が、ネズミの海馬における神経新生の速度を変化させることが実証されている。全体として、学習における神経新生の役割は十分に解明されていないが、脳における学習のサポートにおいて重要な役割を果たすと考えられている。
グリア細胞:グリア細胞(神経膠細胞)は、神経伝達物質が放出・受容される神経細胞間の小さな隙間であるシナプスでの神経伝達物質シグナルを調節することによって、学習と記憶の維持に重要な役割を果たしている。グリア細胞の一種であるアストロサイトは、神経伝達物質を放出・再吸収し、代謝・解毒することができる。これにより、脳内の神経伝達物質のバランスと利用可能性が調整され、正常な脳機能と学習に不可欠なものとなっている。また、グリア細胞の一種であるミクログリアは、神経伝達物質のシグナル伝達を調節し、学習と記憶にとって重要な損傷組織の修復と再生に関与することができる。シナプス強度の構造的変化には、修復と調節に加えて、さまざまなタイプのグリア細胞の関与が必要であり、最も大きな影響を与えるのはアストロサイトである。しかし、グリア細胞は非常に重要な役割を担っているにもかかわらず、その役割についてはまだ十分に理解されていない。 グリア細胞がシナプスでの学習をサポートするメカニズムを理解することは、今後の重要な研究分野である。

ディープニューラルネットワークと可塑性
人工・スパイク神経回路網:人工ニューラルネットワークは、過去数十年にわたり機械学習において重要な役割を担ってきた。これらのネットワークは、さまざまな難題の解決に向けて、驚異的な進歩を遂げてきた。 AIにおける最も印象的な成果の多くは、膨大な量のデータに基づいて学習された大規模なANNを使用することで実現されてきた。技術的な進歩もさることながら、AIにおける多くの成果は、大規模なGPUアクセラレーターやデータへのアクセスといったコンピューティング技術の革新によって説明することができる。 大規模なANNの応用は大きなイノベーションをもたらしたが、一方で多くの課題が存在する。ANNの実用的な限界として、消費電力の面で効率が悪いこと、動的でノイズの多いデータの処理が苦手なことが挙げられる。また、ANNは学習期間を超えて学習することができない。学習期間中のデータは、時間経過とともに独立かつ同一分布(IID)形式となり、時間的・空間的な相関が高い物理的現実を反映していない。また、ロボットやウェアラブルデバイスなどのエッジコンピューティングデバイスへの統合に向けた課題もある。
その解決策として神経科学に注目し、研究者はANNの代替となるスパイクニューラルネットワーク(SNN)を研究している。SNNはANNの一種で、生物学的ニューロンの挙動により近くなるように設計されている。 ANNとSNNの主な違いは、SNNがタイミングという概念をコミュニケーションに組み込んでいる点である。スパイキングニューロンは、接続された(シナプス前の)ニューロン(またはセンサーの入力を経由)から、膜電位という形で時間経過とともに情報を蓄積していく。ニューロンの膜電位がある閾値を超えると、そのニューロンは、すべての発信側(シナプス後)接続に対して2値の「スパイク」を発射する。スパイクは、2値で時間的に疎であるにもかかわらず、(ANNSのような)速度ベースの情報表現よりも多くの情報を含むことが理論的に実証されている。さらに、モデリング研究により、SNNの利点として、エネルギー効率の向上、ノイズや動的データの処理能力、より堅牢で耐障害性の高いコンピューティングが可能であることなどが示されている。これらの利点は、生物学的な妥当性の向上だけでなく、従来の人工ニューラルネットワークとは異なるスパイクニューラルネットワークのユニークな特性にも起因している。 以下に、リーキーインテグレートアンドファイヤーニューロンの簡単な動作モデルを説明する:

ここで、は時刻
の膜電位、
は膜時定数、
は静止電位、
は膜抵抗、
は注入電流、
は閾値電位、
はリセット電位。膜電位が閾値電位に達するとニューロンがスパイクし膜電位がリセットされる。
このような利点があるにもかかわらず、SNNはまだ開発の初期段階にあり、より広く使われるようになるにはいくつかの課題がある。最も差し迫った課題の1つは、シナプス重みをどのように最適化するかということで、ANNの従来のバックプロパゲーションに基づく方法は、離散的で疎な非線形性のために失敗する。このような難題があるにもかかわらず、現代のスパイクネットワークで可能だと考えられていたことの限界を超えるような研究が存在する。例えば、大規模なスパイクベースのトランスフォーマーモデルである。スパイクモデルは、多くの脳を刺激する学習アルゴリズムの基礎を形成しているため、このレビューにおいて非常に重要である。
ヘビアンとスパイクタイミングに依存する可塑性:ヘビアンとスパイクタイミング依存性可塑性(STDP)は、神経回路や行動の形成に重要な役割を果たすシナプス可塑性の2大モデルである。 ヘビアン学習則は、19494年にDonald Hebbが提唱したもので、あるニューロンの活性化が別のニューロンの活性化を引き起こすというように、ニューロン間のシナプスが共働的に強化されると仮定している。 一方、STDPは最近提唱されたシナプス可塑性のモデルで、シナプス前後のスパイクの正確なタイミングを考慮し、シナプスの強化・弱化を決定する。 STDPは、発達中の神経回路の形成と改良、および経験に対する回路の継続的な適応に重要な役割を果たすと広く信じられている。 以下では、Hebb学習とSTDPの基本原理について概説する。
ヘビアン学習:ヘビアン学習は、2つの神経細胞が同時に活動すればシナプス強度は増加し、活動しなければ減少するという考えに基づいている。 ヘブは、このシナプス強度の増加は、ある細胞が他の細胞に「繰り返し、あるいは持続的に影響を与える」ときに起こるはずだと示唆した(因果関係の意味もある)。 しかし、この原理はしばしば相関的に表現され、有名な比喩として"cell that fire together, wire together"(Siegrid LöwelやCarla Shatzによる様々な表現)がある。
ヘビアン学習は、教師なし学習アルゴリズムとしてよく使われるが、その目的は入力データのパターンを明示的にフィードバックせずに識別することにある。このプロセスの例として、ホップフィールドネットワークがある。このネットワークでは、(対称的な)重みにヘビアンルールを適用することで、大きな2値パターンが全結合リカレントネットワークに簡単に格納される。また、教師あり学習アルゴリズムに応用することも可能で、その場合は、ネットワークの望ましい出力を考慮してルールを変更する。 この場合、ヘビアン学習則は、与えられた入力に対する正しい出力を示す教示信号と組み合わされる。
単純なヘビアン学習則は、数学的に式で記述することができる:
ここではニューロン
とニューロン
の間の重みの変化、
は学習率、
はニューロン
の「活動」(しばしばニューロンの発火率と考えられる)である。 この法則は、2つのニューロンが同時に活性化された場合、その結合が強化されるべきであるとするものである。
基本的なヘビアン学習則の欠点として考えられるのは、その安定性の低さである。例えば、と
が最初は弱い正の相関がある場合、このルールは2つの間の重みを増加させ、その結果、相関が強化され、さらに大きな重みの増加につながる、などである。したがって、何らかの形でスタビライゼーションが必要である。 これは、単純に重みを制限することによって行うこともできるし、シナプス前後の活動の履歴やネットワーク内の他のニューロンの影響などの追加要因を考慮したより複雑なルールによって行うこともできる(多くのそのようなルールの実用的なレビューについては、文献を参照のこと)。
3要素ルール:ヘビアン強化学習:報酬に関する情報を取り入れることで、ヘビアンの学習は強化学習にも利用することができる。Hebbianの更新に直接報酬を乗せるという、一見簡単そうなアイデアもあり、以下のようであり、Rは報酬(この時間ステップまたはエピソード全体)である。:
残念ながら、この考え方は信頼性の高い強化学習ができない。これは、がすでに最適な値にある場合、上記のルールは正味の変化をもたらし、
を最適な値から遠ざけることに気づくことで、直感的に理解できる。
より正式には、Fremauxらが指摘したように、入力、出力、報酬の間の実際の共分散を正確に追跡するには、積の項の少なくとも1つが中心化されていなければならない、つまり、その期待値周辺のゼロ平均ゆらぎで置換されていなければならない。1つの可能な解決策は、
からベースラインを引くことによって、報酬をセンタリングすることである(一般に、この試行におけるRの期待値に等しい)。
より効果的な解決策は、出力から平均値を取り除くことである。これは、神経活動に、適当なゼロ中心分布からとったランダムな摂動
を時々与え、生のシナプス後活動
ではなく、摂動
を3因子積に使うことで簡単に行える:
これはFieteとSeungが提案した、いわゆる「ノード摂動」ルールである。直感的には、インクリメントの効果は、将来の
応答(同じ
入力をカウントする場合)を摂動方向に押し出すことであることに気づく。このシフトに
を掛けると、将来の反応が、
が正の場合は摂動の方向に、負の場合は摂動から遠ざかるようになる。
がゼロ平均でない場合でも、分散は大きくなるものの、(期待値として)正味の効果はRが高くなる方向に向かうことに変わりはない。
このルールは、REINFORCEアルゴリズム(Williamsの原著論文56は、確率的スパイクニューロンに対するノード摂動を正確に再現するアルゴリズムを提案している)を実装していることがわかり、に対する
の理論的勾配を推定することができる。また、生物学的にもっともらしい方法で実装し、リカレントネットワークが疎な遅延報酬から自明でない認知タスクや運動タスクを学習できるようにすることもできる。
スパイクタイミングに依存する可塑性:スパイクタイミング依存性可塑性(STDP)は、シナプス可塑性の理論モデルであり、ニューロン間の結合強度をスパイクの相対的タイミングに基づいて変更することができる。STDPは、シナプス前後のニューロンの同時活性化に依存するヘビアン学習則とは異なり、シナプス前後のスパイクの正確なタイミングを考慮したモデルである。具体的には、シナプス前ニューロンがシナプス後ニューロンの直前に発火した場合、両者の結合は強化されると考える。 逆に、シナプス後神経細胞がシナプス前神経細胞の直前に発火した場合、接続は弱くなるはずである。
STDPは、大脳新皮質、海馬、小脳など、さまざまな生体系で観察されている。 この法則は、学習や記憶などの神経回路の発達や可塑性に重要な役割を果たすことが示されている。STDPは、脳の構造と機能を模倣した人工神経回路網の開発にも利用されている。
STDPの数式は、ヘビアン学習則よりも複雑で、特定の実装によって変化することがある。しかし、一般的な定式化は以下の通りである。

ここで、はニューロン
とニューロン
間の重みの変化、
はシナプス前後のスパイクの時間差、
と
はそれぞれ増強と抑制の振幅、
と
はそれぞれ増強と抑制の時定数である。この法則は、2つのニューロンのスパイクのタイミングによって、2つのニューロン間の接続の強さが増減することを意味している。

人工神経回路網の学習を支えるプロセス
人工ニューラルネットワークにおける重みの最適化には、誤差駆動型のグローバル学習と、脳からヒントを得たローカル学習の2つのアプローチがある。 最初のアプローチでは、大域的な誤差を最小値に近づけることで、ネットワークの重みを変更する。 これは、誤差を各重量に委譲し、各重量間の修正を同期させることで実現される。一方、脳を用いた局所学習アルゴリズムは、局所的に利用可能な情報を用いて力学方程式から重みを修正することにより、より生物学的に妥当な方法で学習することを目的としている。どちらの最適化手法も、独自の利点と欠点がある。 以下では、エラー駆動型グローバル学習として最も利用されているバックプロパゲーションについて説明し、その後、脳から着想を得たローカルアルゴリズムについて詳しく説明する予定である。 この2つのアプローチは相互に排他的なものではなく、それぞれの長所を補完するために統合されることが多いということを述べておく。
バックプロパゲーション:バックプロパゲーションは強力なエラー駆動型グローバル学習法であり、ニューラルネットワークのニューロン間の結合の重みを変化させ、望ましい目標行動を生成する。 これは、感覚情報(視覚入力、書かれたテキスト、ロボットの関節位置など)が与えられたときの行動の質を表す定量的なメトリック(目的関数)を使用することで達成される。バックプロパゲーションアルゴリズムは、フォワードパスとバックワードパスの2つのフェーズで構成されている。 フォワードパスでは、入力がネットワークに伝搬され、出力が計算される。バックワードパスでは、予測出力と「真の」出力との誤差が計算され、誤差をネットワークを通して後方に伝播させることにより、ネットワークの重みに対する損失関数の勾配が計算される。この勾配を利用して、確率的勾配降下法などの最適化アルゴリズムにより、ネットワークの重みを調整する。 このプロセスは、損失関数を最小化する値の集合に重みが収束するまで、何度も繰り返される。
バックプロパゲーションについて、数学的に簡単に説明しよう。 まず、ネットワークの出力と真値の関数である損失関数を定義する。:

ここで、は真の出力、
はネットワークの出力である。 この場合、二乗誤差を最小化しているが、滑らかで微分可能な損失関数であれば十分に最適化できる。次に、チェインルールを使って、ネットワークの重みに対する損失の勾配を計算する。ここで、
を層
のニューロン
と層
のニューロン
間の重みとし、
を層
のニューロン
の活動として、重みに対する損失の勾配は次のように与えられる:
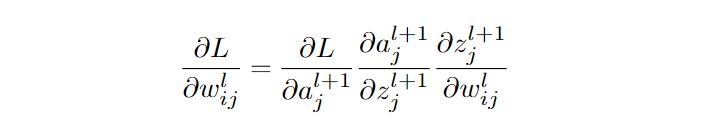
ここで、はニューロン
の層
への入力の加重和である。 そして、これらの勾配を利用して、勾配降下法を用いてネットワークの重みを更新することができる:

ここで、は学習率である。 勾配を計算し、重みを更新することを繰り返すことで、ネットワークは徐々に損失関数を最小化することを学習し、より正確な予測を行うことができる。 実際には、勾配降下法は勾配推定に運動量を取り入れるアプローチと組み合わされることが多く、これにより汎化が大幅に改善されることが示されている。
バックプロパゲーションの素晴らしい成果を受けて、神経科学者たちは、バックプロパゲーションが脳における学習をよりよく理解できるかどうかを研究している。バックプロパゲーションの変形が脳内で起こりうるかどうかについてはまだ議論があるが、現在のバックプロパゲーションが生物学的にありえないことは明らかである。別の説では、複雑なフィードバック回路や、局所活性とトップダウン信号の相互作用(「第3因子」)が、バックプロパゲーションに似た学習形態をサポートする可能性があると考えられている。
しかし、バックプロパゲーションを繰り返し適用することで、アルゴリズムに根本的な問題が生じることがある。その一つが、「壊滅的忘却」と呼ばれる現象で、ニューラルネットが新しいデータで学習する際に、以前に学習した情報を忘れてしまうというものである。この現象は、ネットワークが新しいデータで微調整されたときや、ネットワークが前のタスクから学んだ知識を保持せずに一連のタスクで訓練されたときに発生することがある。壊滅的な忘却は、多様で変化する環境から継続的に学習できるニューラルネットワークを開発するための重要なハードルである。また、バックプロパゲーションでは、ネットワークの全レイヤーを通して情報をバックプロパゲートする必要があり、特に非常に深いネットワークの場合、計算コストと時間がかかるという課題もある。このため、深層学習アルゴリズムのスケーラビリティが制限され、限られた計算資源で大規模なモデルを学習することが難しくなる。 しかし、バックプロパゲーションは、人工ニューラルネットワークを使用するアプリケーションにおいて、最も広く使用され、成功を収めているアルゴリズムであり続けている。
進化的アルゴリズムと遺伝的アルゴリズム:これらのアルゴリズムは、自然淘汰のプロセスに着想を得ており、ANNの文脈では、進化のプロセスを模倣することによってニューラルネットワークのウェイトを最適化することを目的としている。遺伝的アルゴリズムでは、ニューラルネットワークの集団をランダムな重みで初期化し、各ネットワークを特定のタスクや問題で評価する。このプロセスは数世代にわたって繰り返され、最も優れたネットワークが再生産に使用されるため、世代を超えてより高い確率で動作するようになる。進化的アルゴリズムは遺伝的アルゴリズムと同様に動作するが、確率的勾配を近似することで異なるアプローチを使用する。これは、重みを摂動させ、ネットワークの目的関数のパフォーマンスを組み合わせてパラメータを更新することで実現される。この結果、バックプロパゲーションのような局所的な探索方法と比較して、よりグローバルに重み空間を探索し、最適な解を効率的に見つけることができる。
これらのアルゴリズムの利点は、広大なパラメータ空間を効率的に探索できることであり、パラメータ数が多い問題や複雑な探索空間に適している。 また、差分可能な目的関数を必要としないため、目的関数の定義や計算が困難な場合(例:スパイキングニューラルネットワーク)に有効である。 しかし、これらのアルゴリズムにはいくつかの欠点もある。 一つは、大規模なネットワーク集団を評価し、進化させるために必要な計算コストが高いということである。 また、アルゴリズムが局所最適にはまり込んだり、収束が早すぎたりして、最適な解が得られない可能性があることも課題である。 さらに、ランダムな変異を使用することで、学習プロセスの不安定性や予測不可能性を招く可能性がある。
しかし、進化的アルゴリズムや遺伝的アルゴリズムは、特に微分不可能で自明でないパラメータ空間を最適化する際に、様々なアプリケーションで有望な結果を示している。 現在、これらのアルゴリズムの効率とスケーラビリティを向上させるとともに、勾配降下法ではなく、これらのアプローチをいつ、どこで使用することが理にかなっているかを発見することに焦点を当てた研究が行われている。
人工ニューラルネットワークの学習に関する脳に触発された表現
局所学習アルゴリズム:バックプロパゲーションのような、ネットワーク全体に情報を伝播させる必要があるグローバル学習アルゴリズムとは異なり、局所学習アルゴリズムは、近接またはシナプス接続されたニューロンからの局所情報に基づいてシナプスの重みを更新することに焦点を当てる。 後述するように、局所学習アルゴリズムを活用することで、ANNはより効率的に学習し、変化する入力分布に適応できるようになり、実世界での応用に適している。本節では、脳から着想を得た局所学習アルゴリズムの最近の進歩と、ANNの性能とロバスト性を向上させる可能性について概説する。
バックプロパゲーション由来の局所学習:バックプロパゲーション由来の局所学習アルゴリズムは、バックプロパゲーションの数学的特性を模倣しようとする局所学習アルゴリズムの一種である。従来のバックプロパゲーションアルゴリズム(誤差信号をネットワーク全体に伝搬させる)とは異なり、バックプロパゲーション由来の局所学習アルゴリズムは、バックプロパゲーションを用いて計算された局所誤差勾配に基づいてシナプスの重みを更新する。この方法は計算効率が良く、オンライン学習が可能であるため、学習データが継続的に到着するアプリケーションに適している。バックプロパゲーション由来の局所学習アルゴリズムの顕著な例として、フィードバックアライメント(FA)アルゴリズムがある。このアルゴリズムは、バックプロパゲーションで用いられる重み輸送行列を固定ランダム行列に置き換え、エラー信号を直接接続から伝搬させることにより、エラー信号のバックプロパゲーションの必要性をなくした。フィードバックアライメントを数学的に簡単に説明すると、ネットワークの最終層と出力を結ぶ重み行列をとし、入力と第1層を結ぶ重み行列を
としたとき、以下のようになる。 フィードバックアライメントでは、エラー信号は
の転置ではなく、固定ランダム行列
を使用して出力から入力に伝搬される。その後、入力とエラー信号の積
を用いて重み更新が計算され、
は入力、
は学習率、
はネットワークを通して後方に伝搬されるエラー信号で、従来の逆伝播と似ている。
Direct Feedback Alignment(DFA)は、出力層の誤差を各隠れ層に直接接続することで、FAと比較して重み伝達の連鎖を単純化する。 Sign-Symmetry(SS)アルゴリズムは、フィードバック重みが符号を対称に共有する以外はFAと同様である。 FAはMNISTやCIFARのような小規模なデータセットでは優れた結果を示しているが、ImageNetのような大規模なデータセットではその性能はしばしば最適とは言えない。一方、最近の研究では、SSアルゴリズムが、大規模データセットでもバックプロパゲーションと同等の性能を達成できることが示されている。
資格伝播(Eligibility propagation: e-prop)は、従来のエラーバックプロパゲーションとスパイクタイミング依存性可塑性(STDP)などの生物学的に妥当な学習ルールの両方の利点を組み合わせて、スパイク神経回路のフィードバックアライメントの考えを拡張したものである。各シナプスに対して、e-prop アルゴリズムは資格痕跡(eligibility trace)を計算・保持する。資格痕跡は、過去のすべての入力を考慮した上で、ニューロンの現在の出力に対するこのシナプスの総貢献度を測定するものである。これは、バックワードパスを使用せず、純粋なフォワード方式で計算および更新することができる。この適格性トレースに、ニューロンの出力に対する誤差の勾配の推定値
を掛け、実際の重み勾配
を求めることができる。
自体は、出力ニューロンの誤差から計算され、対称フィードバック重みを使用するか、フィードバックアラインメントのように固定フィードバック重みを使用する。e-propの欠点は、各時点でリアルタイムの誤差信号
を必要とすることである。なぜなら、e-propは過去の事象のみを考慮し、将来の誤差については盲目だからである。 特に、REINFORCEやノード摂動のような方法とは対照的に、個々のニューロン・ニューロンの時間スケールを超える遅延エラー信号(短期適応を含む)から学ぶことはできない。
参考文献[75][76]では、神経細胞の信号アーキテクチャに関する最近の遺伝学的知見に基づき、シナプス学習の規範となる理論が示されている。そして、ニューロンタイプの多様性とニューロンタイプに特化した局所的なニューロンモジュレーションが、生物学的な単位付与のパズルの重要なピースとなる可能性を提唱している。 本研究では、この理論を探求するために、資格伝播に基づく簡略化された計算モデルを確立し、ドーパミン様の時間的差異と神経ペプチド様の局所調節シグナルの両方を含むこのモデルが、e-propやフィードバックアライメントなどの従来の方法よりも改善することを示す。
一般化特性:ディープラーニングの技術は、学習アルゴリズムの汎化を理解するために大きな進歩を遂げた。特に有用な発見は、平坦な極小値がより良い汎化につながる傾向があることだった78。この意味は、パラメータ空間(シナプス重みの値)に摂動があった場合、より有意な性能低下が狭い極小値の周辺で観察されるということである。 最近の研究では、(脳にヒントを得た)バックプロパゲーション由来の局所学習ルール79が発揮する汎化特性について検討されている。 バックプロパゲーションに由来する局所学習ルールは、バックプロパゲーションに由来する局所学習ルールと比較して、勾配近似が真の勾配とうまく整合しないため、ステップサイズを拡大しても改善されない、より悪い、より可変な汎化を示している。 漸化式の局所的な近似が完全なものよりも汎化特性が悪くなるのは当然かもしれないが、この研究は、脳から着想を得た学習アルゴリズムを設計するための最善のアプローチとは何かという新たな問いを投げかける扉を開くことになる。結論として、バックプロパゲーション由来の局所学習ルールは、脳から着想を得た学習アルゴリズムを設計するための有望なアプローチである一方、対処すべき制限を伴っていることになる。 これらのアルゴリズムの汎化性の低さは、その性能を向上させ、代替的な脳内学習ルールを探求するための更なる研究の必要性を強調している。 また、バックプロパゲーションに由来する局所学習ルールは、基本的に劣悪な汎化性を示すことを考えると、研究する価値があるのかどうかという疑問も出てくる。
メタ的に最適化された可塑性ルール:メタ最適化された可塑性ルールは、エラー駆動型のグローバル学習と、脳から着想を得たローカル学習の効果的なバランスを提供する。メタ学習とは、学習アルゴリズム自体の探索を自動化することであり、学習アルゴリズムを記述するために人に頼るのではなく、そのアルゴリズムを見つけるための探索プロセスを採用することであると定義できる。メタラーニングの考え方は、当然、脳から着想を得た学習アルゴリズムにも及び、脳から着想を得た学習メカニズム自体を最適化することで、手動でルールを調整することなく、より効率的な学習を発見することが可能となる。以下では、この研究の様々な側面について、微分的に最適化されたシナプス可塑性ルールから説明する。
微分可能な可塑性:この原理を応用した文献として、微分可塑性というものがある。これは、ニューラルネットワークのシナプス可塑性ルールを勾配降下によって最適化することに焦点を当てたフレームワークである。これらのルールでは、可塑性ルールはそのダイナミクスを支配するパラメータが微分可能であるように記述され、可塑性ルールのパラメータ(例えば、単純なヘビアンルールの項やSTDPルールの
項)のメタ最適化にバックプロパゲーションを用いることができる。 これにより、重みのダイナミクスは、実行中に重みを最適化する必要がある課題を正確に解決できるようになり、寿命内学習と呼ばれる。
微分可塑性ルールは、神経調節ダイナミクスの微分最適化も可能である。このフレームワークには、ネットワーク出力に依存するグローバルパラメータによって重みの変化の方向と大きさを制御するグローバル神経調整と、過去の活動の影響を短い時間ウィンドウ内でドーパミン様信号によって変調するレトロアクティブ神経調整という2種類の神経調整の主なバリエーションがある。これは、どのシナプスが最近の活動に貢献したかを追跡するために使用される資格痕跡を使用し、ドーパミン信号がこれらのトレースを実際の可塑的変化へと変換することで可能となる。
微分可塑性を含む方法は、連続連想タスク、親しみ検出、ロボットノイズ適応などの幅広いアプリケーションで改良が見られる。また、この方法は、強化学習や時間的教師付き学習問題で性能向上を示す短期可塑性ルールの最適化にも使用されている。これらの方法は有望であるが、バックプロパゲーションを用いて各シナプスの複数個のパラメータを時間的に最適化するため、分化可塑性アプローチには膨大な量のメモリが必要である。これらの方法を実用化するには、パラメータ共有か、よりメモリ効率の良いバックプロパゲーションが必要になるだろう。
スパイクニューロンによる可塑性:最近、スパイキングニューロンの非微分化部分を代理勾配でバックプロパゲートする技術が進歩し、スパイク型ニューラルネットワークの可塑性ルールを最適化するために微分化可塑性を使用することができるようになった。 文献[61]では、この最適化パラダイムの能力を、スパイクタイミングに依存する差動可塑性ルールを用いて、オンラインワンショット継続学習問題とオンラインワンショット画像クラス認識問題で「学習する学習」を可能にしたことを示した。 また、同様の手法で、可塑性ルールのe-propの勾配近似を用いた第3因子信号の最適化を行い、e-propのメタ最適化形式を導入している。進化によって調整されたリカレントニューラルネットワークもまた、メタ最適化された学習ルールに使用することができる。Evolvable Neural Units(ENUs)は、入力の処理、保存、動的パラメーターの更新方法を制御するゲート構造を導入している。 本研究では、神経細胞の個々の体細胞およびシナプス区画モデルの進化を示し、ENUのネットワークがスパイクダイナミクスと強化型学習ルールを独立して発見し、T迷路環境課題を解くために学習できることを示す。
RNNとトランスフォーマーにおける可塑性:更新規則を用いた可塑性学習を目指す研究とは別に、トランスフォーマーは最近、優れた生涯内学習者であることが示されている。文脈内学習のプロセスは、シナプスの重みを更新することなく、純粋にネットワークの活性化の中で機能する。 トランスフォーマーのように、このプロセスはリカレントニューラルネットワークでも起こりうる。文脈内学習はシナプス可塑性とは異なるメカニズムのように見えるが、これらのプロセスは強い関係を示すことが実証されている。この文献で議論されているエキサイティングなつながりは、メタ学習器のパラメータ共有が、しばしば活性化を重みとして解釈することにつながるという認識である。これは、これらのモデルが固定的な重みを持つかもしれないが、可塑的な重みを持つモデルと同じ学習能力を示すことを示すものである。もう一つの関連は、トランスフォーマーのセルフアテンションは外積と内積を含み、学習された重みの更新としてキャストでき、勾配降下を実施することもできることである。
進化的・遺伝的メタ最適化:微分可塑性と同様に、進化的・遺伝的アルゴリズムは、ロボットシステムにおける手足の損傷への適応など、さまざまなアプリケーションにおいて可塑性ルールのパラメータを最適化するために使用されてきた。 また、最近の研究では、直交遺伝的プログラミングを用いて、可塑性係数と可塑性ルール方程式の最適化が可能となり、解決すべき特定の課題に基づいて生物学的に妥当な可塑性ルールを発見するための自動化アプローチが提示された。これらの方法では、遺伝的または進化的な最適化プロセスは、アウターループプロセスで可塑性パラメータを最適化し、可塑性ルールはインナーループプロセスで報酬を最適化するというように、微分可能プロセスと同様の働きをする。 この方法は、微分可能な方法と比較して、時間経過による誤差の逆伝播が不要なため、メモリフットプリントが非常に小さく、魅力的な方法である。しかし、メモリ効率は良いものの、勾配ベースの手法と同等の性能を得るためには、膨大な量のデータを必要とすることが多い。
自己言及的なメタラーニング:シナプス可塑性では、メタ学習者と発見された学習則の2つの学習階層があるが、自己言及的メタ学習ではこの階層が逆転している。可塑性アプローチでは、ネットワークパラメータのサブセット(シナプス結合の重みなど)のみが更新され、メタ学習された更新ルールはメタ最適化の後、固定されたままである。自己言及的なアーキテクチャは、ニューラルネットワークが再帰的にすべてのパラメータを変更することを可能にする。したがって、学習者はメタ学習者をも修正することができる。これは原理的に、任意のレベルの学習、メタ学習、メタメタ学習などを可能にする。 いくつかの手法は、このようなシステムのパラメータ初期化をメタ学習している。この初期化を見つけるには、やはりハードワイヤーなメタ学習者を必要とする。また、ネットワークが自己修正することで、このメタ学習者すら不要になるものもある。発見される学習則が構造的な探索空間の制約を持ち、自己改良を単純化する場合もあり、その場合、勾配ベースオプティマイザが自己発見、進化アルゴリズムが自己最適化することができる。シナプス可塑性と自己言及的アプローチは、その違いにもかかわらず、ニューラルネットワークの自己改善と適応を達成することを目的としている。
メタ最適化学習則の一般化:特に、バックプロパゲーションのような人手による汎用的な学習ルールに取って代わるべきはいつなのか。 これらの手法の課題として、探索空間が大きく、学習メカニズムにほとんど制約がない場合、汎化が難しくなることが示されている。しかし、これを改善するために、可変型共有メタ学習では、柔軟な学習ルールを、局所的に情報を交換するパラメータ共有型リカレントニューラルネットワークによってパラメータ化し、メタ最適化時には見られなかった分類問題に対して汎化する学習アルゴリズムを実現した。同様の結果は、強化学習アルゴリズムの発見でも示されている。

脳を使った学習法の応用
ニューロモーフィック・コンピューティング:ニューロモーフィックコンピューティングは、生物学的な脳の構造と機能を模倣したハードウェアを開発することを目的とした、コンピューティングシステムの設計におけるパラダイムシフトを象徴するものである。このアプローチでは、脳の学習機能だけでなく、エネルギー効率や固有の並列性をも再現した人工ニューラルネットワークを開発することを目指している。ニューロモーフィックコンピューティングシステムは、脳から着想を得た学習アルゴリズムの効率的な実行を可能にするため、ニューロモーフィックチップやメモリスティックデバイスなどの特殊なハードウェアを組み込んでいることが多い。これらのシステムは、特に先端コンピューティングやリアルタイム処理の場面で、機械学習アプリケーションの性能を飛躍的に向上させる可能性を秘めている。
ニューロモーフィック・コンピューティングの重要な側面は、生物学的なニューロンの情報処理メカニズムにより近いスパイク型ニューラルネットワークの実装を容易にする特殊なハードウェア・アーキテクチャの開発にある。ニューロモーフィック・システムは、脳から着想を得た局所学習の原理に基づいて動作するため、実世界のアプリケーションに不可欠な高いエネルギー効率、低レイテンシー処理、ノイズに対する堅牢性を実現することができる。この技術の成功には、脳から着想を得た学習技術とニューロモルフィック・ハードウェアの統合が欠かせない。
近年、ニューロモルフィックコンピューティングの進歩により、Intel社のLoihi、IBM社のTrueNorth、SpiNNakerなど、SNNやブレインインスパイアード学習アルゴリズムを実装するための専用ハードウェアアーキテクチャを備えたさまざまなプラットフォームが開発されている。これらのプラットフォームは、ニューロモーフィック・コンピューティング・システムをさらに探求するための基盤となり、研究者は新しいニューラルネットワークのアーキテクチャや学習ルールを設計、シミュレーション、評価することができる。ニューロモーフィック・コンピューティングが進歩し続けるにつれ、人工知能の発展において極めて重要な役割を果たすことが期待され、イノベーションを促進し、より効率的で汎用性の高い、生物学的に実現可能な学習システムを開発することができる。
ロボットの学習:ニューラルネットワークにおける脳を使った学習は、ロボットがより柔軟な方法で学習し、環境に適応できるようにすることで、ロボット工学の分野に存在する現在の課題の多くを克服する可能性を秘めている。従来のロボティクスシステムは、あらかじめプログラムされた動作に依存しており、状況の変化に適応する能力には限界があった。これに対して、本レビューで示したように、ニューラルネットワークは、受け取ったデータに基づいて内部パラメータを調整することで、状況に適応するように訓練することができる。
ロボット工学との自然な関係から、脳から着想を得た学習アルゴリズムは、ロボット工学において長い歴史を持つ。このため、シナプス可塑性ルールは、モーターゲインや悪路などのドメインシフトにロボット動作を適応させるために導入されており、障害物回避、多関節(アーム)コントロールにも導入されている。脳から着想を得た学習ルールは、ロボットシステムを具現化した媒体として、昆虫の脳でどのように学習が行われるかを探るためにも使われている。
深層強化学習(DRL)は、脳から着想を得た学習アルゴリズムの重要な成功例で、ニューラルネットワークの長所と脳の強化学習の理論を組み合わせて、環境との相互作用を通じて複雑な行動を学習できる自律型エージェントを作り出す。DRLアルゴリズムは、分類や回帰誤差の最小化ではなく、ドーパミンニューロンの活動を模した報酬駆動型の学習プロセスを利用することで、非常にダイナミックで不確実な環境であっても、ロボットが目標を達成するための最適な戦略を学習するよう導く。 この強力なアプローチは、器用な操作、ロボット運動、マルチエージェント協調など、様々なロボットアプリケーションで実証されている。
生涯学習・オンライン学習:生涯学習やオンライン学習は、変化する環境に適応し、新しいスキルや知識を継続的に習得することを可能にするため、人工知能における脳から着想を得た学習の重要なアプリケーションである。これに対し、従来の機械学習は、固定されたデータセットで学習するため、新しい情報や環境の変化に適応する能力が欠けていた。成熟した脳は、生涯にわたって学習し続けることができる素晴らしいメディアである。このレビューでは、脳と同じような脳に着想を得た学習メカニズムを持つニューラルネットワークは、継続的に学習・適応するように訓練することができ、時間の経過とともにその性能を向上させることができることを示した。
この能力を人工システムに発揮させる脳着想学習アルゴリズムの開発は、その性能と能力を大幅に向上させる可能性を秘めており、さまざまな用途に幅広い影響を与える。 このようなアプリケーションは、ロボティクスや自律システムのように、データの収集が困難であったり高価であったりする状況において特に有用であり、学習が起こる前に大量のデータを収集し処理する必要がなく、リアルタイムでシステムが学習し適応できるようになる。
破局的忘却とは、ANNが新しいデータを学習する際に、それまで学習した情報を突然忘れてしまう傾向のことである。これは、新しい学習に合わせて、それまで最適化されていたネットワークの重みが大幅に変更され、以前の情報が消去または上書きされてしまうために起こる。 これは、バックプロパゲーションのアルゴリズムが、新しい学習を容易にする一方で、以前に獲得した情報を保存する必要性を本質的に考慮していないためである。 この問題を解決することは、何十年もの間、AIの重要なハードルとして残っている。私たちは、脳の動的な学習メカニズムを模倣した、脳に着想を得た学習アルゴリズムを採用することで、生物に固有の熟練した問題解決戦略を活用できる可能性があると考える。
脳の解明に向けて:人工知能と神経科学の世界は、互いに大きな恩恵を受けている。特定のタスクのために特別に調整されたディープニューラルネットワークは、空間情報や視覚情報の扱い方において人間の脳と著しい類似性を示している。この重複は、人工ニューラルネットワーク(ANN)が、脳の複雑なメカニズムをよりよく理解するための努力において有用なモデルであるという可能性を示唆している。ニューロコネクショニスト研究プログラムと呼ばれる新しい動きは、この複合的なアプローチを体現しており、ANNを計算言語として使用し、脳の計算方法に関するアイデアを形成し検証している。バックプロパゲーションやバックプロパゲーションに似た局所学習ルールを使って大規模なニューラルネットワークを訓練することは、脳機能をモデル化するための良い出発点になるかもしれない。脳内でバックプロパゲーションと同様の動作をするプロセスは何かということについて、多くの生産的な研究が行われており、神経科学における新しい視点や理論に繋がっている。
このレビューでは、脳の機能を模倣するさまざまなアルゴリズムを紹介したが、脳内で実際に学習がどのように行われているかを完全に把握するためには、まだかなりの量の作業が必要である。バックプロパゲーションやバックプロパゲーションに似た局所学習ルールを使って大規模なニューラルネットワークを訓練することは、脳機能をモデル化するための良い出発点になるかもしれない。脳内でバックプロパゲーションと同様の動作をするプロセスは何かということについて、多くの生産的研究が行われており、神経科学における新しい視点や理論に繋がっている。現在の形式でのバックプロパゲーションは脳では起こらないかもしれないが、学習のメカニズムがこれほど異なるにもかかわらず、脳がANNと同様の内部表現を開発するかもしれないという考えは、脳とAIをより深く理解することにつながるかもしれない、刺激的な未解決問題である。
現在では、静的なネットワーク名だけでなく、脳のように時間の関数として解き明かされるネットワークまで探求が進んでいる。不断の学習や生涯学習のアルゴリズムの開発が進むにつれ、私たちのモデルは、自然界で観察される学習メカニズムをより忠実に反映する必要があることが明らかになるかもしれない。このような観点から、ANNに局所的な学習ルール、つまり脳独自の方法を反映させることが求められている。
我々は、ANNに生物学的に正しい学習ルールを採用することは、前述のようなメリットをもたらすだけでなく、神経科学の研究者に正しい方向を示すことにもつながると確信している。つまり、エンジニアリングのイノベーションを活性化させるだけでなく、脳内の複雑なプロセスの解明に近づくという、二重のメリットを持つ戦略なのである。より現実的なモデルによって、人工知能という新しい視点から、脳の計算の複雑さをより深く追求することができるのである。
結論
このレビューでは、より生物学的に妥当な学習メカニズムをANNに統合することを検討した。 このような統合は、神経科学と人工知能の双方にとって重要な一歩となる。 特に、人工知能の分野では、大規模な言語モデルや埋め込みシステムが大きな進歩を遂げており、学習と実行のためのエネルギー効率の高いアプローチが切実に求められている中で、このことは重要である。さらに、ANNはこれらの用途で大きな進歩を遂げているが、生物の脳のように適応する能力にはまだ大きな限界があり、これは脳から着想を得た学習メカニズムの主要な応用と考えられる。
神経科学とAIが将来、より詳細な脳に着想を得た学習アルゴリズムに向けて協力するための戦略を立てるとき、神経科学がAIに与えた過去の影響について、既成の解決策をそのまま問題解決に適用することはほとんどなかったことを認めることが重要である。むしろ神経科学は、動物の学習や知能の側面について興味深いアルゴリズムレベルの疑問を投げかけ、AI再研究者を刺激してきた。神経科学は、学習をサポートする重要なメカニズムについて、予備的な指針を与えている。同様に、AIで脳のような学習アルゴリズムを使った実験を行うことで、神経科学に対する理解を加速させることができる。