COMET: Commonsense Transformers for Automatic Knowledge Graph Construction
©2022 Association for Computational Linguistics
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容に基づき筆者が要約または翻訳したものです。以下の図は、そこから引用しています。
This article is my summary or translation based on the content of the original publication. The following figures are taken from it.
要点まとめ
我々は、2つの普及しているコモンセンス知識グラフ、すなわち ATOMIC (Sap et al., 2019)とConceptNet (Speer et al., 2017)に対する自動知識ベース構築に関する最初の包括的な研究を発表する。正規のテンプレートで知識を格納する多くの従来のKBとは逆に、コモンセンスKBは知識の緩く構造化されたオープンテキスト記述のみを格納する。我々は、コモンセンスの自動補完に向けた重要なステップは、コモンセンス知識の生成モデルの開発であると仮定し、自然言語で豊かで多様なコモンセンス記述を生成することを学習するCOMmonsEnse Transformers (COMET)を提案する。コモンセンスモデリングの課題にもかかわらず、我々の調査では、事前に訓練された深い言語モデルからの暗黙知をコモンセンス知識グラフの明示的な知識を生成するために転送した場合、有望な結果が得られることが明らかにした。COMETは、人間が高品質と評価する新規知識を生成できることが実証され、トップ1では最大77.5%(ATOMIC)、91.7%(ConceptNet)の精度で、これらのリソースの人間のパフォーマンスに近づいた。この結果は、コモンセンスKBの自動補完に生成コモンセンスモデルを用いることが、抽出的な手法に代わる有力な選択肢となる可能性を示唆している。
1 序論
人間は文章を読むとき、提示された物語を理解するために、常識的な推論を行う。機械がこのような能力を獲得するためには、制限のない状況において、適切かつ正しい常識を獲得することができなければならない。 この研究では、常識の獲得を知識ベース構築として捉え、大規模言語モデルが常識的な知識ベース(KB)を自動的に構築するために必要な知識を生成することを効果的に学習できるかどうかを調査する。
自動KB構築は、高精度のキュレーションKBで高い概念網羅性を達成することが困難なため、人工知能研究の長年の目標である(Lenat, 1995; Miller, 1995)。これまでの研究では、半構造化テキスト(Suchanek et al., 2007; Hoffart et al., 2013; Aueret al., 2007; Bollacker et al., 2008) や非構造化テキスト (Dong et al., 2014; Carlson et al., 2010; Nakashole et al., 2011, 2012; Niu, 2012) を読み取り、ダウンストリームアプリケーションに照会できるリラショナルスキーマとして抽出できるモデルの開発が行われてきた。しかし、これらのアプローチに共通するのは、百科事典的な知識に焦点を当てることであり、これはモデル化できる実体と関係のよく定義された空間に適している。
しかし、コモンセンスな知識は、2つのエンティティと既知の関係を比較するスキーマに明確に適合しないため、現在のアプローチは、「エンティティ」を自然言語のフレーズ、関係をそれらを結びつけることのできる任意の概念としてモデル化することになる(Li et al., 2016; Sap et al., 2019)。OpenIEのアプローチは、オープンテキストのエンティティと関係というこの特性を示すが(Etzioni et al., 2011; Fader et al.,2011; Mausam et al., 2012)、抽出的であるため、テキストで明示的に言及された知識しか捕捉できず、しばしば暗黙的である常識知識の取得に対する適用性が限られている(Gordon and Van Durme, 2013)。
一方、深層文脈化言語モデルのトレーニングにおける最近の進歩(Peters et al.2018; Radford et al., 2018; Devlin et al., 2018)は、コモンセンスKB構築のための道として、外付けの方法を超えて探求する機会を提供します。これらの大規模言語モデルは、その基礎となる表現が最終的なタスクを解決するために調整されたときに素晴らしい性能を発揮し、さまざまな複雑な問題でSoTAの結果を達成している。この研究ではCOMMon sEnse Transformer(COMET)を定義し、既存のタプルを知識のシードセットとして使用することでコモンセンスKBを構築し、その知識を訓練する。このシードセットを用いて、事前に訓練された言語モデルは、学習された表現を知識生成に適応させることを学習し、高品質な新規タプルを生成する。

この研究における我々の貢献を以下のように要約する。まず、知識ベース構築のための生成的アプローチを開発する。モデルは、既存のシードフレーズと関係タイプを首尾よく補完するフレーズを生成することによって、新しいノードを生成し、既存のノード間のエッジを識別するように学習する必要がある。次に、大規模な変換言語モデルを用いて、常識的な知識句を生成することを学習する枠組みを開発する。最後に、ATOMICとConceptNetの2つのドメインについて、本アプローチが生成する常識的な知識の質、新規性、多様性に関する実証研究と、効果的な知識モデルを学習するために必要なシードタプルの数に関する効率化研究を実施する。その結果、ATOMICイベントに対する生成タプルの77.5%、ConceptNetリラプションに対する生成タプルの91.7%が人間の判定によって正しいことが判明したことから、COMETは高品質のタプル生成に成功したことがわかった。
2 コモンセンスを生成するための学習
COMETは、知識タプルのシードセットに対して言語モデルを学習させることにより、言語モデルからコモンセンス知識ベースを構築する適応フレームワークである。これらのタプルは、学習すべき知識ベースの構造と関係をCOMETに提供し、COMETは、事前学習で学習した言語モデル表現を適応させて、新しいノードとエッジをシード知識グラフに追加することを学習する。
2.1 タスク
より具体的には、この問題はCOMETに形式の自然言語タプルの学習知識ベースが与えられ、
がタプルのフレーズ主語、
がタプルの関係、
がタプルのフレーズ目的語であると仮定する。例えば、"taking a nap "に関連するConceptNetタプルは、次のようになる:s="take a nap", r=Causes, o="have energy"。タスクは与えられた
と
に対して
を生成することである。
表記法:を関係の主語を構成するトークン、
をタプルの関係を構成するトークン、
をタプルのオブジェクトを構成するトークンとして定義する。任意の単語
に対する埋め込みを
とする。
2.2 Transformer言語モデル
COMETは初期化される言語モデルに依存しないが、本研究では、Radfordら(2018)(GPT)で紹介されたTransformer言語モデルアーキテクチャを使用する。GPTは、マルチヘッドスケールドドットアテンションと完全連結層の複数のTransformerブロックを使用して入力テキストをエンコードする(Vaswani et al, 2017)。図2は、GPTアーキテクチャのさまざまなコンポーネントを示しており、以下、各コンポーネントをより深く定義している。

Transformer Block:図2(b)に示すように、各Transformerは、アーキテクチャ的に同一のTransformerブロック(ただし、ユニークなパラメータを持つ)を含み、そのブロックへの入力に以下の変換を適用する。

ここで、MULTIATTNはマルチヘッドのセルフアテンション機構(以下に定義)、FFNは2層のフィードフォワードネットワーク、LAYERNORMはセルフアテンションとフィードフォワードネットワークの出力に適用される層正規化(Ba et al., 2016)操作を表す。LAYERNORM操作の入力には、前の操作の出力と入力を合計した残差接続を含むことに注意すること。
マルチヘッドアテンション:図2(a)に示す各Transformerブロックのマルチヘッドアテンションモジュールは、Vaswaniら(2017)によって元々定義されたものと同じである。アテンション機能は、クエリQ、キーK、およびバリューVの3つの入力を受け取る。アテンションは、QとKを用いたVに対するユニークなスケールドットプロダクトアテンション分布を計算する複数のヘッドで構成されている:

ここで、はクエリ、キー、バリューを表す入力ベクトルの次元数である。各ヘッドについて、Q、K、Vはアテンションが計算される前に一意的に投影される:
![]()
ここで、は1つの注目ヘッドの出力、
、
、
はそれぞれQ、K、Vに対するヘッド固有のプロジェクションである。 そして、アテンションヘッド
の出力は連結される:

ここで、はアテンションヘッドの連結出力の出力投影である。図2(c)に示すように、我々はRadfordら(2018)に従い、前の層のトランスフォーマーブロックの出力を、次のブロックのマルチヘッドアテンションのクエリ入力として使用する。キーとバリューは、すべての先行する時間ステップの前のレイヤーのブロックの出力である:

ここで、は、
以前の時間ステップの前のトランスフォーマーブロック出力の集合である。
エンコーダ入力:モデルの入力として、知識タプルを、タプルの各項目の単語を連結したシーケンスとして表現しています:
![]()
Transformer(セルフアテンションモデル)にはトークンの順序の概念がないため、シーケンスの絶対位置ごとに位置埋め込みが初期化される(Vaswani et al, 2017)。 任意の入力単語
に対して、入力の我々のエンコーディングは、シーケンス
内の絶対位置をエンコードする位置エンベッディングと、その単語エンベッディング
の合計である:
ここで、は時間ステップ
の位置埋め込み、
は最初のトランスフォーマーレイヤーへの入力である。
3 COMETの学習
COMETは、知識タプルのフレーズサブジェクトと関係
が与えられたときに、そのフレーズオブジェクト
を生成するように学習する。より具体的には、
と
:
]のトークンの連結が入力として与えられた場合、モデルは
のトークンを生成するように学習しなければならない(これらの変数の定義については§2.1参照)。
損失関数:この目標を達成するために、COMETはフレーズオブジェクトのトークンを予測する条件付き対数尤度を最大化するように学習する:

ここで、、
、
はそれぞれ主語句、関係句、目的語句のトークンの数である。図3は、異なる学習タスクのための
、
、
中のトークンがどのように構成されているかを概説している。

データセット:COMETは、既存のKBから知識エッジタプルのシードセットを使用して、コモンセンス知識の生成を学習する。この研究では、知識シードセットとしてATOMICとConceptNetを使っているが、COMETはドメインを問わず、他のコモンセンス知識再ソースも使用できた。
初期化:パラメタはRadfordら(2018)の最終言語モデル重みに初期化されている。微調整のために語彙に追加される特別なトークン(例えば、ATOMICのReactやConceptNetのISAなどの関係詞)は、標準正規分布からサンプリングして初期化する。
ハイパーパラメータ:Radfordら(2018)のGPTモデルの設計に従って、COMETに12層、768次元隠れ状態、12のアテンションヘッドを初期化する。ドロップアウト率は0.1、活性化関数としてGeLU(Hendrycks and Gimpel, 2016)ユニットを使用する。訓練中のバッチサイズは64である。その他のデータセット固有のハイパーパラメータは付録 A.1 に記載されている。
4 ATOMIC実験
Sapら(2019)が公開したATOMIC datasetは、特定のイベントプロンプト(例えば、「Xは店に行く」)周辺の様々な社会的コモンセンス知識をカバーする877Kタプルを含む。具体的には、ATOMICは、イベントの原因(例えば、「Xはそこに車で行く必要がある」)、エージェントへの影響(例えば、「食べ物を得る」)、他の直接(または暗示)参加者への影響(例えば、「他の人は食べ物を得る」)を網羅し、二次元でそのコモンセンスを蒸留しています。実験では、ATOMICイベント(例:「Xが店に行く」)はフレーズ主語、、次元(例:xIntent)はフレーズ関係、
、原因/結果(例:「食べ物を得る」)はフレーズ対象、
とする。 Sapら(2019)のトレーニングスプリットを使用し、それぞれ710kトレーニング、80k開発、87kテストタプルになる。
4.1 セットアップ
指標:Sapら(2019)に従い、自動評価指標としてBLEU-2を用いて本手法を評価する。 また、ゴールド応答におけるモデルのperplexityも報告する。表1の残りの自動評価指標は、トレーニングセットにない生成タプルと生成オブジェクトの比率を測定する。生成されたタプルのうち、新規のもの(% N/Tsro)と新規のオブジェクトを持つものの割合(% N/To) を報告する。これらの新規オブジェクトが多様であることを示すために(すなわち、同じ新規オブジェクトが唯一生成されるわけではない)、新規オブジェクトの数を、すべてのテストセットイベントに対して生成されたユニークなオブジェクトのセットの関数として報告します(% N/Uo)。

最後に、Amazon Mechanical Turk (AMT)のワーカーを使った人間評価を行う。ワーカーは、ATOMIC commonsenseのモデル生成が、フレーズ主語、関係詞、フレーズ目的語のもっともらしいタプルを適切に補完しているかどうかを確認するよう求められる。Sapetら(2019)の設定に従い、テストセットからランダムに選択した100のイベントを評価する。 各イベントと関係性のタイプについて、beamsearchを用いて10個の候補が生成され、5人の異なる作業者によってフルビームが評価される。全体として、1つの関係につきの評価が生成される(100イベント×5ワーカー×10候補)。表2のAvgは、これらのスコアの平均値であり、各モデルの総評価数は
である。統計的有意性の検定には、100k個の順列を用いたPitmanの検定(Noreen, 1989)を用いる。50の異なる仮説が検証されるため(9つの関係+合計)、有意性の閾値を補正するためにホルム-ボンフェローニ法(Holm, 1979)が使用される。 開発セットからのイベント例とその生成されたフレーズオブジェクトは表5にある。

ベースライン:Sap et al.(2019) で学習された、LSTM sequence-to-sequenceモデル (Sutskever et al., 2014) を用いて入力のサブジェクトと関係を符号化して出力オブジェクトを生成するモデルに対する我々の手法の性能を報告する。
アブレーション:また、大規模なコーパスでの事前学習がモデルの知識生産学習にどのように役立つかを評価するため、事前学習済みの重みを初期化しないバージョンのCOMET(COMET(-pretrain))を訓練する。 最後に、本手法の最終目標は高品質で多様な知識ベース構築を可能にすることであるため、様々なデコーディング方法が候補となる知識タプルの品質にどのような影響を与えるかを調査する。具体的には、argmax greedy decoding、ビームサイズb=2, 5, 10のbeamsearch、k=5, 10のtop-ksam-plingの3つの復号化方式について、その効果を検証する。 各復号化方法について、各方法で生成された最終候補の数について、人間による評価を行った。
4.2 結果
総合性能:表1のBLEU-2の結果から、COMETはすべてのベースラインの性能を上回り、Sapら(2019)のトップパフォーマンスモデルに対して51%の相対的な改善を達成したことがわかる。しかし、より興味深いのは、人間による評価の結果であり、COMETは、トップのベースラインであるEvent2IN(VOLUN)に対して18%の統計的に有意な相対Avgパフォーマンスの増加を報告した。この性能向上は、すべての関係タイプにおいて一貫しており、改善が確認されている。また、表1には、品質向上に加えて、COMETがベースラインよりも多くの新規タプルオブジェクトを生成していることが示されている。

言語からの知識の学習Radfordら(2018)のGPTモデルから事前に訓練したパラメータで重みを初期化したモデルの性能とランダム初期化から訓練した同じアーキテクチャのモデル間で有意差も観察された。この14%の相対的な改善により、GPTモデルで学習した言語表現が自然言語のコモンセンス知識の生成に転用可能であることが確認された。
デコードアルゴリズムの効果:表3では、異なる生成ポリシーが知識の質に与える影響を示している。最も興味深い結果は、知識エッジタプルを生成するために貪欲なデコードを使用すると、ATOMICテストセットの人間による評価と比較して、相対的に10%のパフォーマンスギャップしか生じないことであり、モデルが生成する知識は人間のパフォーマンスに近づいていることを示している。より多くの候補を作成すると全体的なパフォーマンスは低下するが、ビームサイズが10の場合、品質評価は55%程度で推移している。この結果は、生成されたタプルの正しさを確認するために人間の評価者がループ内にいることで、COMETが効果的であることを示唆している。

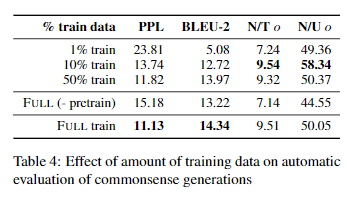
シードタプルからの学習の効率化:すべてのドメインに、訓練に利用できる大規模なコモンセンスKBがあるとは限らないため、学習に利用できる訓練データの量を変えることで、生成する知識の品質と新規性にどのように影響するかを調査した。 表4の結果から、利用可能な訓練データが10%しかない場合でも、モデルは首尾一貫した、適切で、新規性のある世代を生成できることがわかった。1%の訓練データしか使用しない場合、生成される応答品質は著しく低下し、品質と新規性の両方の指標において、観測された結果は著しく低くなった。 興味深いことに、事前に訓練した重みを用いないモデルの訓練は、シードタプルの10%を用いた訓練に匹敵する性能を示し、事前に訓練した言語表現を用いることの影響を定量的に示している。
5 ConceptNet実験
Liら(2016)が提供するConceptNetデータセットは、ConceptNet 5(Speer et al., 2017)のOpenMind Common Sense (OMCS) エントリから得られたタプルから構成されています。タプルはスタンダートフォーム - (e.g., take a nap, Causes, have energy)になっている。 最も信頼性の高い1200タプルはテストセットの作成に使用され、次の1200タプルは2つの開発セットの作成に使用され、我々はこの作業で組み合わせる。トレーニングセットの100kバージョンはモデルのトレーニングに使用され、34の関係タイプを含んでいる。
5.1 セットアップ
指標:ConceptNet関係を生成するモデルを以下の指標で評価する。まず、テストセット(PPL)に含まれるゴールド関係の複雑さを報告する。また、生成された知識の質を評価するために、Liら(2016)によって開発された事前学習済みのBilinear AVGモデルによって正しいと評価されたテストセット内の生成された正の例の数を報告する。与えられたタプルに対して、このモデルは、タプルが正しいかどうかの確率を生成する。Lietら(2016)で提案された完了タスクにおいて、このモデルはテストセットで92.5%の精度を達成し、生成されたタプルが正しいかどうかを自動的に評価する強力な代理であることが示された。最後に、ATOMICと同じ新規性メトリクスである、N/TsroとN/Toを報告する。
ベースライン:ベースラインとして、Saitoら(2018) が提案したBiLSTMモデルを、付録A.2で概説したマイナーチェンジを加えて再実装する。このモデルは、知識ベース補完モデルを補強するのに役立つように、と
の両方向で知識をエンコードすることを学習するように訓練されている。 しかし、このモデルは
タプルの生成タスクでのみ評価されている。また、後の研究のために、
タスクのみで学習させたLSTMモデル(LSTM -s)の結果も掲載する。
アブレーション:私たちのフルモデルには、以下のようなアブレーションが含まれている。まず、大規模コーパス(Radford et al., 2018)での事前学習がパフォーマンスにどのように役立つか、表6でCOMET(- pretrain)と表記した比較モデルをゼロから訓練することで評価する。第二に、我々のメインモデルでは、関係名を自然言語(例えば、IsA→"is a"; HasSubevent→"has subevent")にマッピングし、各関係に対してゼロから特別な埋め込みを学習するのではなく、モデルが言語を使ってこれらの概念を表現することを学習できるようにしている(Levy et al., 2017)。また、関係トークンを自然言語に変換しないモデル(例:ISA "is a")を学習し、これをCOMET-RELTOKと呼ぶことにする。
5.2 結果
品質:我々の結果は、質の高い知識を生成することができることを示すものである。表6にある低いperplexityスコアは、予測に対するモデルの高い信頼性を示し、高い分類スコア(95.25%)は、Li et al(2016)のKB補完モデルが生成されたタプルをほとんどのケースで正しいものとしてスコア付けしていることを示している。この高いスコアは、敵対的な生成が原因である可能性があるが、人間による評価(ATOMICと同じデザインに従う)では、簡単にデコードされたタプルの91.7%が正しいとして評価された。 また、表7に示したランダムに選択された例も、モデルによって生成された知識の質の高さを示している。


新規性:高品質であることに加え、COMETによって生成されたタプルは新規性も持っており、タプルの59.25%は訓練セットには存在しない。これは、モデルがノード間の新しい辺を生成し、さらに新しいノード(ノードの3.75%が新規)を生成して知識グラフのサイズを拡張できることを示した。しかし、新規生成はトレーニングセットのタプルを単純化したものであることがある。例えば、表7では、"doctor CapableOf save life"というタプルはトレーニングセットには存在しないが、"doctor CapableOf save person life "は存在する。 しかし、"bird bone HasProperty fragile "や "drift wood AtLocation beach "のように、トレーニングセットに関連タプルが存在しない、全く新しいタプルも多い。
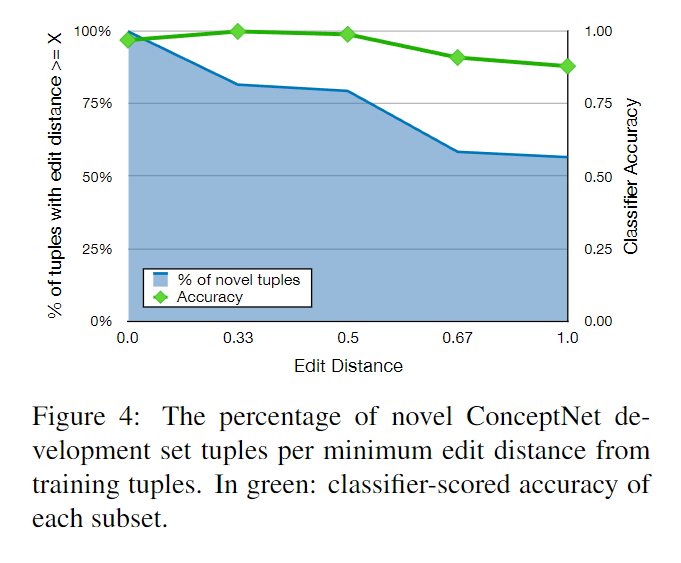
さらに、開発セットの新規タプルは、トレーニングセットのフレーズオブジェクトと、同じのフレーズオブジェクトの最小編集距離でどれだけ異なるかを調査する。フレーズオブジェクト
の編集距離は、タプル
から、最も近い訓練用タプル
の編集距離と比較して測定される。編集距離は単語トークン(ストップワードを除く)を用いて測定し、
または
の最大単語数で正規化する。編集距離の最大値は1(つまり全く異なる単語列)、最小値は0(つまりストップワードを除いた同じ単語列)であり、編集距離の最大値は1(つまり全く異なる単語列)、最小値は0(つまりストップワードを除いた同じ単語列)である。図4は、最も近いトレーニングセットタプルとの編集距離が少なくともX軸の値である新規開発セットタプルのパーセンテージを示したものである。 75%以上の新規フレーズタプルは、訓練フレーズオブジェクトとの正規化編集距離が0.5以上であり、新規フレーズオブジェクトのほとんどが、訓練セット内の最も近い類似物と著しく異なる単語配列を持っていることを示している。
言語からの知識の学習:ATOMICと同様に、大規模な言語コーパスでCOMETを事前学習することが、常識の一般化能力にどのように影響するかを調べた。この効果は表6で明らかであり、事前訓練されたCOMETは、ランダムに初期化されたモデルよりも、自動評価と人間評価で明らかに向上している。トレーニングセットには存在しない "mangoIsAfruit "というタプルが生成され、表7でこの効果を確認することができる。トレーニングセットで "mango "エンティティを含む唯一のタプルは "mangoUsedForsalsa "で、これは十分に情報を提供ししない。確認として、COMET(-pretrain)の出力が "mangoIsAspice "であることを見ますが、これは知識の種集合にある "mango "に関する情報を考えると妥当な推論であると考えられる。
言語による関係表現:記号による関係表現と自然言語による関係表現のモデルを比較した場合、自動的な指標は重要な差異を示さないが(表6)、関係を言語として表現することの利点については、事例から定性的な洞察を得ることができる。 ConceptNetの学習セットでは、"dove"に対する非鳥類学的な参照は"dove CapableOf fly"のみであるが、我々のモデルは一般化を学習して"dove SymbolOf purity"というタプルを生成している。 シンボル関係詞を用いたモデルでは、"dove SymbolOf submarine "という関係しか生成できず、これは "submarine "と "dove "のより海っぽい(そして関連性のない)語義を関連付けるようである。
6 関連研究
知識ベース構築:これまでの研究では、専門家の知識を利用した再論理スキーマとしての知識ベースの構築(Lenat,1995; Bodenreider, 2004; Miller, 1995)、半構造化テキスト抽出(Suchanek et al, 2007;Hoffart et al, 2013; Auer et al, 2007; Bollacker et al, 2008)および非構造化テキスト抽出(Dong et al, 2014; Carlson et al, 2010; Nakasholeet al, 2011, 2012; Niu, 2012)が研究された。我々の研究では、明確に定義された関係スキーマ構造ではなく、オープンテキストのイベントの使用を必要とする常識的な知識ベースの構築に焦点を当てる。 情報抽出の他の研究は、オープンテキストエンティティを用いた知識ベース構築に適用することもできるが(Soderland et al., 2010; Etzioni et al., 2011; Fader et al., 2011; Mausam et al., 2012; Fan et al., 2010; Cui et al., 2018)、これらの方法は通常、明示的なテキスト再列を抽出する。 逆に、我々のアプローチは、コモンセンス情報が一般的であるように、しばしばテキストに記載されていない新しい知識を生成する(Gordon and Van Durme, 2013)。
コモンセンス知識ベースの補完:新しいコモンセンス知識の生成に関する既存の研究は、ConceptNetとATOMICを基礎KBとして使用している。具体的には、Liら(2016)は、ConceptNetのタプルをスコアリングするための一連のニューラルネットワークモデルを提案した。我々の研究は、彼らのモデルが知識グラフの新しいノードを作るためのフレーズを生成するために学習するのではなく、完全なタプルを評価するので、このアプローチとは異なるものである。Saitoetら2018)は、コモンセンスタプルの補完と生成のための共同モデルを提案することによって、この仕事を構築している。しかし、彼らの研究は、非合理的なKB構築のカバレッジを高めるためではなく、KBの補完モデルを補強するためにタプル生成を使用することに焦点を当てている。最後に、Sapら(2019)は、LSTMエンコーダ-デコーダモデルを使用して、社会的状況についてのコモンセンス知識を生成する。我々は、トランスフォーマーを使用し、それらを初期化するために事前に訓練された言語表現(Radford et al., 2018)を使用することの効果を調査する。
トランスフォーマーと事前学習:最後に、我々の仕事は、様々なシーケンスラベリング、分類、およびNLIエンドタスクのための事前訓練された言語モデルの適応に関する以前の仕事(Radford et al., 2018; Peters et al., 2018; Devlin et al., 2018)に基づいている。私たちの研究は、新しいグラフノードとノード間のエッジを生成することにより、事前に訓練された言語モデルを大規模なコモンセンスKB構築にどのように使用できるかを調査している。
7 結論
常識的な知識ベースを自動構築するためのCOMmonsenseTransformers(COMET)を紹介する。COMETは、言語モデルの重みを適応させ、新規かつ多様な常識知識タプルを生成するように学習する枠組みである。ATOMICとConceptNetの2つの常識知識ベースに関する実証結果は、人間の評価者が正しいとみなす新規の常識知識をCOMETが頻繁に生成することを示している。 これらのポジティブな結果は、他の様々なタイプの知識ベースにアプローチを拡張すること、また、COMETが任意の知識シードに対してOpenIEスタイルの知識タプルを生成することを学習できるかどうかを調査することを今後の課題としている。