Gu, Albert, and Tri Dao. "Mamba: Linear-Time Sequence Modeling with Selective State Spaces." arXiv preprint arXiv:2312.00752 (2023).
©2023 The Authors
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容に基づき筆者が要約または翻訳したものです。以下の図は、そこから引用しています。
This article is my summary or translation based on the content of the original publication. The following figures are taken from it.
要点まとめ
現在、ディープラーニングのエキサイティングなアプリケーションのほとんどを動かしている基盤モデルは、ほとんど例外なくTransformerアーキテクチャとそのコアとなるアテンションモジュールに基づいている。線形アテンション、ゲート付き畳み込み、再帰的モデル、構造化状態空間モデル(SSM)など、多くの二次時間以下のアーキテクチャが、長いシーケンスにおけるTransformerの計算効率の悪さに対処するために開発されてきたが、言語などの重要なモダリティではアテンションほどの性能を発揮していない。
我々は、このようなモデルの重要な弱点が、内容ベースの推論ができないことであることを明らかにし、いくつかの改善を行う。第一に、単にSSMパラメータを入力の関数とすることで、離散的なモダリティに対する弱点に対処し、現在のトークンに応じてシーケンスの長さ次元に沿って選択的に情報を伝搬したり、忘れたりすることを可能にする。第二に、この変更により効率的な畳み込みが使えなくなっても、リカレントモードでハードウェアを意識した並列アルゴリズムを設計する。これらの選択的SSMを、アテンションやMLPブロックさえも持たない単純化されたエンド・ツー・エンドのニューラルネットワークアーキテクチャ(Mamba)に統合する。
Mambaは、高速な推論(Transformerより5倍高いスループット)とシーケンス長における線形スケーリングを享受し、その性能は実データにおいて100万長シーケンスまで向上する。一般的な配列モデルのバックボーンとして、Mambaは言語、オーディオ、ゲノミクスなど様々なモダリティにおいて最先端の性能を達成している。言語モデリングにおいて、我々のMamba-3Bモデルは同じサイズのTransformerを上回り、事前学習と下流タスクでの評価の両方で2倍のサイズのTransformerに匹敵する。
1. Introduction
基盤モデル(FM)、すなわち膨大なデータで事前学習された後、下流のタスクに適応される大規模モデルは、現代の機械学習における効果的なパラダイムとして台頭してきた。これらのFMのバックボーンは多くの場合シーケンスモデルであり、言語、画像、音声、時系列、ゲノムなど様々な領域からの入力の任意のシーケンスで動作する(Brown et al. 2020; Dosovitskiy et al. 2020; Ismail Fawaz et al. 2019; Oord et al. 2016; Poli et al. 2023; Sutskever, Vinyals, and Quoc V Le 2014)。このコンセプトはモデルアーキテクチャの特定の選択に不可知論的であるが、現代のFMは主に単一のタイプのシーケンスモデル、すなわちTransformer(Vaswani et al. 2017)とそのコアとなるアテンション層(Bahdanau, Cho, and Bengio 2015)に基づいている。セルフアテンションの有効性は、コンテキストウィンドウ内で情報を高密度にルーティングする能力に起因し、複雑なデータをモデル化することを可能にする。しかし、この特性は、有限のウィンドウの外側のものをモデル化することができないこと、ウィンドウの長さに関して2次スケーリングすること、といった基本的な欠点をもたらす。これらの欠点を克服するために、より効率的なアテンションの変種に関する膨大な研究が登場している(Tay, Dehghani, Bahri, et al. 2022)。今のところ、これらの変種はいずれも、経験的に、領域横断的なスケールで有効であることが示されていない。
最近、構造化状態空間シーケンスモデル(SSM)(Gu, Goel, and Ré 2022; Gu, Johnson, Goel, et al. 2021)が、シーケンスモデリングのための有望なアーキテクチャのクラスとして出現した。これらのモデルは、古典的な状態空間モデル(Kalman 1960)から着想を得て、リカレントニューラルネットワーク(RNN)と畳み込みニューラルネットワーク(CNN)を組み合わせたものと解釈できる。このクラスのモデルは、再帰または畳み込みとして非常に効率的に計算でき、シーケンスの長さに対して線形または線形に近いスケーリングが可能である。さらに、特定のデータモダリティにおける長距離依存性(Gu, Dao, et al. 2020)をモデル化するための原理的なメカニズムを持っており、Long Range Arena(Tay, Dehghani, Abnar, et al. 2021)などのベンチマークを支配してきた。多くのSSM(Gu, Goel, and Ré 2022; Gu, Gupta, and Berant 2022; Y. Li et al. 2023; Smith, Warrington, and Linderman 2023)は、音声や視覚のような連続的な信号データを含む領域では成功を収めている(Goel et al. 2022; Nguyen, Goel, et al. 2022; Saon, Gupta, and Cui 2023)。しかし、テキストのような離散的で情報密度の高いデータのモデル化にはあまり有効ではない。
我々は、いくつかの軸で先行研究を改善し、シーケンスの長さを線形にスケーリングしながらTransformerのモデリング能力を達成する、新しいクラスの選択的状態空間モデルを提案する。
選択メカニズム まず、先行モデルの重要な限界、すなわち、入力に依存した方法でデータを効率的に選択する能力(すなわち、特定の入力に焦点を当てたり、無視したりする能力)を明らかにする。選択的コピーやインダクションヘッドのような重要な合成タスクに基づく直観を基に、入力に基づいてSSMパラメータをパラメータ化することで、簡単な選択メカニズムを設計する。これにより、モデルは無関係な情報をフィルタリングし、関連する情報を無期限に記憶することができる。
ハードウェアを意識したアルゴリズム この単純な変更は、モデルの計算に技術的な課題をもたらす。実際、先行するすべてのSSMモデルは、計算効率を上げるために、時間と入力に不変でなければならない。我々は、畳み込みの代わりにスキャンを使用してモデルを再帰的に計算するハードウェアを意識したアルゴリズムでこれを克服するが、GPUメモリ階層の異なるレベル間のIOアクセスを回避するために、展開された状態を実体化しない。その結果、理論的にも(すべての畳み込みベースのSSMの擬似線形と比較して、シーケンス長で線形にスケーリングする)、最新のハードウェア上でも(A100 GPUで最大3倍高速)、以前の方法よりも高速な実装が可能となった。
アーキテクチャ 先行するSSMアーキテクチャ(Dao, Fu, Saab, et al. 2023)の設計とTransformerのMLPブロックを1つのブロックに組み合わせることで、先行するディープシーケンスモデルアーキテクチャを簡素化し、選択的状態空間を組み込んだシンプルで均質なアーキテクチャ設計(Mamba)を導く。
選択的SSM、ひいてはMambaアーキテクチャは、シーケンス上で動作する一般的な基礎モデルのバックボーンとして適した、重要な特性を持つ完全リカレントモデルである。(i) 高品質:選択性は、言語やゲノミクスのような高密度なモダリティにおいて強力な性能をもたらす。(ii) 高速な学習と推論:学習中の計算とメモリはシーケンス長に対して線形にスケールし、推論中のモデルの自己回帰的なアンロールは、前の要素のキャッシュを必要としないため、ステップごとに一定の時間しか必要としない。(iii) 長い文脈:品質と効率性を合わせると、シーケンス長1Mまでの実データで性能向上が得られる。
我々は、一般的なシーケンスFMのバックボーンとしてのMambaの可能性を、いくつかのタイプのモダリティと設定において、事前学習の品質とドメイン固有のタスク性能の両方において実証的に検証する:
合成。大規模言語モデルの鍵として提案されているコピーや帰納法のような重要な合成タスクにおいて、Mambaはそれらを簡単に解くだけでなく、無限に長い(>1Mトークン)解を外挿することができる。
オーディオとゲノミクス。Mambaは、音声波形やDNA配列のモデリングにおいて、SaShiMi、Hyena、Transformersなどの先行する最先端モデルを、事前学習の品質とダウンストリームメトリクスの両方で上回っている(例えば、困難な音声生成データセットのFIDを半分以下に削減)。どちらの設定においても、100万長シーケンスまでの長いコンテキストで性能が向上している。
言語モデリング。Mambaは、Transformerに匹敵する性能を達成した最初の線形時間シーケンスモデルである。1Bパラメータまでのスケーリング則により、LLaMa(Touvron et al. 2023)に基づく非常に強力な最新のTransformerトレーニングレシピを含む、広範囲のベースラインの性能をMambaが上回ることを示す。私たちのMamba言語モデルは、同規模のTransformerと比較して5倍の生成スループットを持ち、Mamba-3Bの品質は2倍のサイズのTransformerに匹敵する(例えば、Pythia-3Bと比較して常識的推論で平均4ポイント高く、さらにPythia-7Bを上回る)。
モデルコードと事前学習済みチェックポイントは以下のサイトGitHub - state-spaces/mambaでオープンソース化されている。
2. State Space Models
構造化状態空間シーケンスモデル(S4)は、RNN、CNN、および古典的な状態空間モデルに広く関連する、深層学習のためのシーケンスモデルの最近のクラスである。 具体的には、S4モデルは4つのパラメータで定義され、2段階でシーケンスからシーケンスへの変換を定義する。

離散化。第一段階は、と
という固定式によって、「連続パラメータ」
を「離散パラメータ」
に変換する。ここで、
の組を離散化規則と呼ぶ。式(4)で定義されるゼロ次ホールド(ZOH)など、様々なルールを使用することができる。

離散化には連続時間システムとの深いつながりがあり、解像度不変性(Nguyen, Goel, et al. 2022)や、モデルが適切に正規化されていることを自動的に保証する(Gu, Johnson, Timalsina, et al. 2023; Orvieto et al. 2023)といった付加的な特性を持たせることができる。また、RNNのゲーティング機構(Gu, Gulcehre, et al. 2020; Tallec and Ollivier 2018)にも関連しており、これについてはセクション3.5で再確認する。しかし、機械的な観点からは、離散化は単にSSMのフォワードパスにおける計算グラフの最初のステップとみなすことができる。別のタイプのSSMは、離散化ステップをバイパスし、代わりにを直接パラメータ化することができる(Zhang et al. 2023)。
計算。パラメータがと変換された後、モデルは線形再帰(2)またはグローバル畳み込み(3)の2つの方法で計算することができる。一般的に、このモデルは、並列化可能な効率的な学習(入力シーケンス全体が先読みされる)のために畳み込みモード(3)を使用し、効率的な自己回帰推論(入力が一度に1タイムステップずつ見られる)のためにリカレントモード(2)に切り替えられる。
線形時間不変性(LTI)。式(1)~(3)の重要な特性は、モデルのダイナミクスが時間を通して一定であることである。言い換えれば、、ひいては
はすべてのタイムステップで固定される。この性質は線形時間不変性(LTI)と呼ばれ、再帰や畳み込みと深く関係している。非公式には、LTI SSMは線形再帰(2a)や畳み込み(3b)と等価であると考え、これらのクラスのモデルの総称としてLTIを用いる。
これまでのところ、全ての構造化SSMは、セクション3.3で議論する基本的な効率性の制約から、LTIであった(例えば、畳み込みとして計算された)。しかし、この研究の核となる洞察は、LTIモデルはある種のデータのモデリングにおいて基本的な制約があるということであり、我々の技術的な貢献は、効率のボトルネックを克服しながらLTI制約を取り除くことにある。
構造と次元。最後に、構造化SSMは、効率的に計算するためには行列に構造を課す必要があるため、このような名前になっていることに注意する。最も一般的な構造は対角構造であり(Gu, Gupta, et al. 2022; Gupta, Gu, and Berant 2022; Smith, Warrington, and Linderman 2023)、我々もこれを用いる。
この場合、はすべて
個の数字で表現できる。バッチサイズ
、長さ
、
チャンネルの入力シーケンス
を操作するために、SSM は各チャンネルに独立に適用される。この場合、全隠れ状態は入力ごとに
の次元を持ち、それをシーケンス長に渡って計算するには
の時間とメモリが必要であることに注意されたい。これがセクション3.3で扱った根本的な効率性のボトルネックの根源である。
一般的な状態空間モデル。状態空間モデルという用語は非常に広い意味を持ち、単に潜在的な状態を持つ任意のリカレント過程の概念を表すことに注意する。マルコフ決定過程(MDP)(強化学習(Hafner et al. 2020))、動的因果モデリング(DCM)(計算論的神経科学(Friston, Harrison, and Penny 2003))、カルマンフィルター(制御(Kalman 1960))、隠れマルコフモデル(HMM)と線形力学システム(LDS)(機械学習)、リカレント(時には畳み込み)モデル(ディープラーニング)など、様々な分野で多くの異なる概念を指すために使われてきた。
本稿全体を通して、我々は「SSM」という用語を、構造化SSMまたはS4モデル(Gu, Goel, and Ré 2022; Gu, Gupta, et al. 2022; Gupta, Gu, and Berant 2022; Hasani et al. 2023; Ma et al. 2023; Smith, Warrington, and Linderman 2023)を指すものとして使用し、これらの用語を互換的に使用する。便宜上、線形回帰や大域的畳み込みの視点に焦点を当てたもの(Y. Li et al. 2023; Orvieto et al. 2023; Poli et al. 2023)など、このようなモデルの派生モデルも含め、必要に応じてニュアンスを明確にする。
SSMのアーキテクチャ。SSMは、エンドツーエンドのニューラルネットワークアーキテクチャに組み込むことができる、独立した配列変換である。(我々はSSMアーキテクチャをSSNNと呼ぶこともあるが、これはCNNが線形畳み込み層に対するように、SSM層に対するものである)。最もよく知られたSSMアーキテクチャーをいくつか取り上げるが、その多くは我々の主要なベースラインにもなる。
線形アテンション(Katharopoulos et al. 2020)は、退化した線形SSMと見なすことができる、再帰を含むセルフアテンションの近似である。
H3 (Dao, Fu, Saab, et al. 2023)は、この再帰をS4を使うように一般化したもので、SSMを2つのゲート接続で挟んだアーキテクチャとみなすことができる(図3)。H3はまた、メインのSSM層の前に、標準的な局所畳み込みを挿入しており、これはシフトSSMとして枠組まれている。
Hyena(Poli et al. 2023)はH3と同じアーキテクチャを使っているが、S4層をMLPパラメータ化されたグローバル畳み込みに置き換えている(Romero et al. 2021)。
RetNet(Y. Sun et al. 2023)は、アーキテクチャに追加のゲートを追加し、より単純なSSMを使用することで、畳み込みの代わりにマルチヘッドアテンション(MHA)の変種を使用し、並列化可能な別の計算経路を可能にしている。
RWKV (B. Peng et al. 2023)は、別の線形アテンション近似(attention-free Transformer(S. Zhai et al. 2021))に基づいて言語モデリング用に設計された最近のRNNである。その主な「WKV」メカニズムはLTI再帰を含み、2つのSSMの比率と見なすことができる。
他の密接に関連するSSMとアーキテクチャーについては、拡張された関連研究(付録B)を参照されたい。我々は、特にS5(Smith, Warrington, and Linderman 2023)、QRNNB(radbury et al. 2016)、SRU(Lei et al. 2017)を、我々のコア選択的SSMと最も密接に関連する手法とみなす。

3. Selective State Space Models
我々は、合成タスクからの直感を用いて我々の選択メカニズムを動機付けし(セクション3.1)、次にこのメカニズムを状態空間モデルに組み込む方法を説明する(セクション3.2)。結果として得られる時変SSMは畳み込みを使用することができず、いかに効率的に計算するかという技術的課題を提示する。我々は、最新のハードウェアのメモリ階層を利用したハードウェアを意識したアルゴリズムでこれを克服する(セクション3.3)。次に、アテンションやMLPブロックを用いないシンプルなSSMアーキテクチャについて述べる(セクション3.4)。最後に、選択機構の付加的な性質について述べる(セクション3.5)。
3.1 Motivation: Selection as a Means of Compression
我々は、シーケンスモデリングの基本的な問題は、コンテキストをより小さな状態に圧縮することであると主張する。実際、この観点から、一般的なシーケンスモデルのトレードオフを見ることができる。例えば、アテンションは効果的であると同時に非効率的でもある。このことは、自己回帰推論がコンテキスト全体(すなわちKVキャッシュ)を明示的に保存する必要があり、Transformersの遅い線形時間推論と2次時間学習の直接の原因となっていることからもわかる。一方、リカレントモデルは有限の状態を持つため効率的であり、一定時間の推論と線形時間の学習を意味する。しかし、その有効性は、この状態がどれだけ文脈を圧縮しているかによって制限される。
この原理を理解するために、合成タスクの2つの実行例に注目する(図2)。
選択的コピータスクは、記憶するトークンの位置を変化させることで、一般的なコピータスク(Arjovsky, Shah, and Bengio 2016)を修正する。関連するトークン(色付き)を記憶し、無関係なトークン(白)をフィルタリングできるように、内容を認識した推論が必要である。
インダクション・ヘッドタスクは、LLMの文脈内学習能力の大部分を説明すると 仮定された、よく知られたメカニズムである(Olsson et al. 2022)。この課題では、適切な文脈で正しい出力を出すタイミングを知るために、文脈を意識した推論が必要となる(黒)。
これらのタスクは、LTIモデルの失敗モードを明らかにしている。リカレントの観点からは、その一定のダイナミクス(例えば(2)の遷移)は、文脈から正しい情報を選択することができず、入力に依存した方法でシーケンスに沿って渡される隠れた状態に影響を与えることができない。畳み込みの観点からは、グローバル畳み込みは、時間認識のみを必要とするため、バニラコピー課題(Romero et al. 2021)を解決できることが知られているが、選択的コピー課題(Selective Copying task)に対しては、内容認識がないため困難であることが知られている(図2)。より具体的には、入力と出力の間隔は変化するため、静的な畳み込みカーネルではモデル化できない。
要約すると、シーケンスモデルの効率と有効性のトレードオフは、どれだけ状態を圧縮するかによって特徴付けられる。効率的なモデルは小さな状態を持たなければならないが、有効なモデルはコンテキストから必要な情報をすべて含む状態を持たなければならない。そこで、シーケンスモデルを構築するための基本的な原理は、選択性、つまり、コンテクストを意識して、シーケンス状態への入力に焦点を当てたり、フィルタリングしたりする能力であることを提案する。特に、選択メカニズムは、情報がシーケンスの次元に沿ってどのように伝搬し、あるいは相互作用するかを制御する(詳細な議論についてはセクション3.5を参照)。


3.2 Improving SSMs with Selection
モデルに選択メカニズムを組み込む1つの方法は、シーケンスに沿った相互作用に影響を与えるパラメータ(RNNのリカレントダイナミクスやCNNの畳み込みカーネルなど)を入力依存にすることである。アルゴリズム1と2は、我々が使用する主な選択メカニズムを示している。主な違いは、単純にいくつかのパラメータを入力の関数とし、それに伴ってテンソルの形状を全体的に変化させることである。特に、これらのパラメータが長さ次元
を持つようになり、モデルが時不変から時変に変わったことを意味する。(形状の注釈はセクション2で説明した)。これは畳み込み(3)との等価性を失い、次に説明する効率に影響する。
私たちは、特に、を
次元へのパラメータ化された投影として、
、
、
、
を選択した。
𝑠と∆の選択は、セクション3.5で説明したRNNのゲーティング機構との関連によるものである。と
の選択は、セクション3.5で説明したRNNのゲーティングメカニズムに関連している。
3.3 Efficient Implementation of Selective SSMs
畳み込み(Krizhevsky, Sutskever, and Hinton 2012)やTransformer (Vaswani et al. 2017) のような、ハードウェアフレンドリーなアーキテクチャは、幅広いアプリケーションで利用されている。ここでは、選択的SSMを最新のハードウェア(GPU)上でも効率的にすることを目指す。選択メカニズムは極めて自然であり、以前の研究では、リカレントSSMにおいてを時間的に変化させるなど、選択の特殊なケースを取り入れることを試みている(Gu, Dao, et al.) しかし、先に述べたように、SSMの使用における核心的な限界は計算効率であり、そのためS4とすべての派生研究は、LTI(非選択的)モデル、最も一般的にはグローバル畳み込みの形式を使用していた。
3.3.1 Motivation of Prior Models
まずこの動機を再検討し、先行手法の限界を克服するための我々のアプローチを概説する。
セクション3.1で議論したように、隠れ状態の次元が大きいモデルはより効果的であるが、より遅い。したがって、我々はスピードとメモリーのコストを支払うことなく、隠れ状態の次元を最大化したい。
後者(3)は前者(2)を展開することで得られるので、リカレント・モードは畳み込みモードよりも柔軟であることに注意する(Gu, Goel, and Ré 2022; Gu, Johnson, Goel, et al. 2021)。しかし、この場合、入力
と出力
の形状
よりもはるかに大きい(SSMの状態次元である、
のファクターにより)形状
を持つ潜在状態
を計算し、実体化する必要がある。そのため、状態計算をバイパスし、
先行するLTI SSMは、リカレントと畳み込みの二重形式を活用することで、有効な状態次元を従来のRNNよりも遥かに大きい
のファクターだけ増加させることができ、効率性のペナルティはない。
3.3.2 Overview of Selective Scan: Hardware-Aware State Expansion
選択メカニズムはLTIモデルの限界を克服するように設計されている。同時に、SSMの計算問題を再検討する必要がある。我々は、カーネル融合、並列スキャン、再計算という3つの古典的手法でこれに対処する。我々は主に2つの観察を行う:
素朴なリカレント計算が
FLOPsを使うのに対し、畳み込み計算は
FLOPsであり、前者の方が定数係数が小さい。このように、シーケンスが長く、状態次元
2つの課題は、再帰のシーケンシャルな性質と、大きなメモリ使用量である。後者に対処するため、畳み込みモードと同様に、完全な状態
主なアイデアは、最新のアクセラレータ(GPU)の特性を利用して、メモリ階層のより効率的なレベルでのみ状態を実体化することである。特に、ほとんどの演算(行列の乗算を除く)は、メモリ帯域幅によって制限される (Dao, Fu, Ermon, et al. 2022; Ivanov et al. 2021; Williams, Waterman, and Patterson
2009)。これにスキャン演算も含まれ、カーネルフュージョンを使用してメモリIOの量を削減し、標準的な実装と比較して大幅な高速化を実現している。
具体的には、サイズのスキャン入力
をGPU HBM(高帯域幅メモリ)に準備する代わりに、SSMパラメータ
を低速HBMから直接ロードし、SRAMで離散化と再帰を実行し、サイズ
の最終出力をHBMに書き戻す。
逐次再帰を回避するために、線形ではないにもかかわらず、作業効率の高い並列スキャンアルゴリズムで並列化できることを確認する(Blelloch 1990; Martin and Cundy 2018; Smith, Warrington, and Linderman 2023)。
最後に、バックプロパゲーションに必要な中間状態の保存も避けなければならない。中間状態は保存されず、入力がHBMからSRAMにロードされるバックワードパスで再計算される。その結果、融合された選択スキャン層は、FlashAttentionを使用した最適化されたトランスフォーマ実装と同じメモリ要件になる。
融合カーネルと再計算の詳細は付録Dにある。完全な選択SSMレイヤーとアルゴリズムを図1に示す。
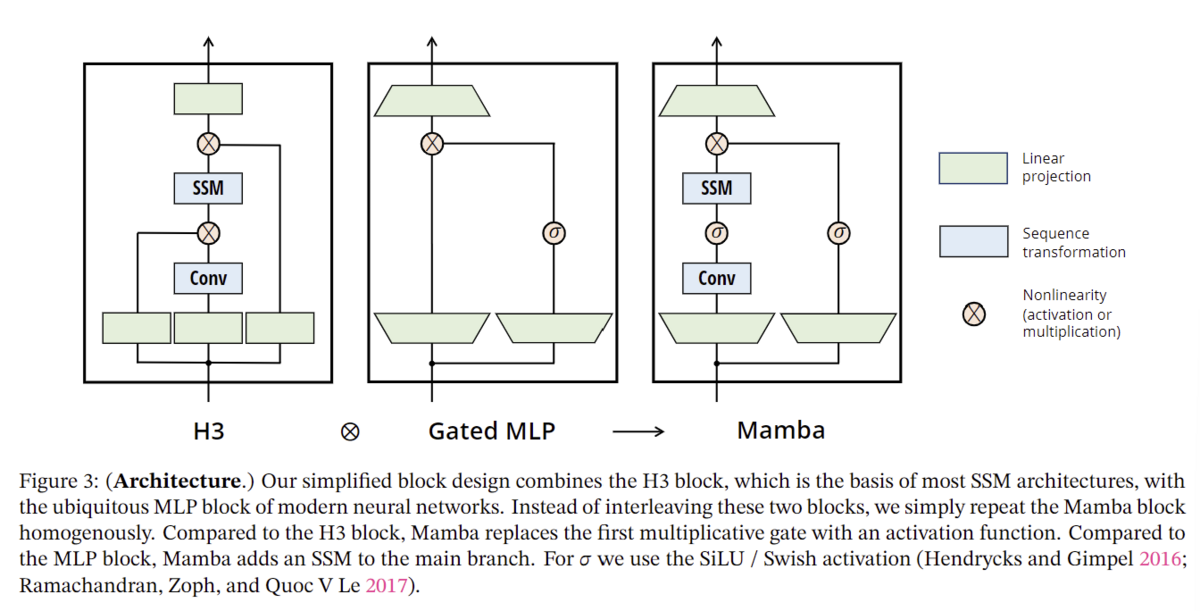
3.4 A Simplified SSM Architecture
構造化SSMと同様に、選択的SSMはニューラルネットワークに柔軟に組み込むことができる独立したシーケンス変換である。H3アーキテクチャーは最もよく知られたSSMアーキテクチャー(セクション2)の基礎であり、一般に線形アテンションにヒントを得たブロックとMLP(多層パーセプトロン)ブロックから構成されている。我々はこの2つのコンポーネントを1つにまとめ、均質に積み重ねることで、このアーキテクチャを単純化している(図3)。これは、アテンションと似たようなことを行うGAU(gated attention unit)(Hua et al. 2022)から着想を得ている。
このアーキテクチャでは、モデルの次元を制御可能な拡大係数
で拡大する。各ブロックについて、パラメータの大部分(
)は線形投影(入力投影は
、出力投影は
)にあり、内側のSSMの寄与は少ない。それに比べてSSMパラメータ(
、行列
に対する投影)の数はずっと少ない。このブロックを繰り返し、標準的な正規化と残差接続をインターリーブして、Mambaアーキテクチャを形成する。実験では常に
に固定し、TransformerのインターリーブされたMHA(multi-head attention)とMLPブロックの
パラメータに合うように、ブロックの2つのスタックを使用する。我々はSiLU/Swish活性化関数(Hendrycks and Gimpel 2016; Ramachandran, Zoph, and Quoc V Le 2017)を使用し、Gated MLPが人気のある "SwiGLU "バリアント (Chowdhery et al. 2023; Shazeer 2020; Touvron et al. 2023)になるように動機づける。最後に、我々はオプションの正規化層(我々はLayerNorm (J. L. Ba, Kiros, and Hinton 2016)を選択)を追加で使用するが、RetNetも同じような場所で正規化層を使用している(Y. Sun et al. 2023)。
3.5 Properties of Selection Mechanisms
選択メカニズムは、より伝統的なRNNやCNN、異なるパラメータ(アルゴリズム2のなど)、または異なる変換
を使用するなど、さまざまな方法で適用できる、より広い概念である。
3.5.1 Connection to Gating Mechanisms
最も重要なコネクションを強調する。RNNの古典的なゲーティング機構は、SSMの選択機構のインスタンスである。RNNのゲーティングと連続時間システムの離散化との関連はよく確立されていることに注意する(Funahashi and Nakamura 1993; Tallec and Ollivier 2018)。実際、定理1はGu, Johnson, Goel, et al. (2021, Lemma 3.1)をZOH離散化と入力依存ゲートに一般化した改良である(証明は付録C)。より広義には、SSMにおけるは、RNNゲート機構の一般化された役割を果たすとみなすことができる。先行研究と同様に、SSMの離散化はヒューリスティックゲーティング機構の原理的基礎であるという見解を採用する。

セクション3.2で述べたように、の具体的な選択はこの関連からである。特に、与えられた入力
が(合成タスクで必要なように)完全に無視されるべきであれば、すべての
チャンネルはそれを無視すべきで、
で繰り返し/ブロードキャストする前に、入力を1次元に投影する。
3.5.2 Interpretation of Selection Mechanisms
ここでは、選択のメカニズム的効果について、特に2つ詳しく説明する。
可変間隔。選択性によって、関心のある入力の間に発生する可能性のある無関係なノイズトークンをフィルタリングすることができる。これは「選択的コピー」タスクで例証されるが、一般的なデータモダリティ、特に離散データ、例えば「um」のような言語フィラーの存在などではどこにでも発生する。この性質は、例えばゲーテッドRNNの場合(定理1)のの時のように、モデルが機械的に特定の入力
をフィルタリングできるために生じる。
文脈のフィルタリング。より多くのコンテキストが厳密により良い性能につながるはずの原則にもかかわらず、多くのシーケンスモデルはコンテキストが長くなっても改善しないことが経験的に観察されている(F. Shi et al. 2023)直感的な例としては、大域畳み込み(および一般的なLTIモデル)がある。一方、選択的モデルはいつでも状態をリセットして余計な履歴を取り除くことができるので、原理的にはコンテキストの長さに応じて単調に性能が向上する(例えばセクション4.3.2)。
境界リセット。複数の独立したシーケンスがつなぎ合わされた設定では、Transformerは特定のアテンションマスクをインスタンス化することでそれらを分離しておくことができるが、LTIモデルはシーケンス間の情報を流出させる。選択的SSMは、境界で状態をリセットすることもできる(例えば、や
のときの定理1)。このような設定は、人為的に(例えば、ハードウェアの使用率を向上させるために文書をまとめて)、あるいは自然に(例えば、強化学習におけるエピソードの境界(Lu et al. 2023))発生する。
さらに、各選択パラメータの効果について詳しく説明する。
の解釈。一般に、
は、現在の入力
をどれだけ重視するか、無視するかのバランスを制御する。これはRNNゲート(例えば定理1の
)を一般化したもので、機械的には、大きな
は状態
をリセットし、現在の入力
に集中し、小さな
は状態を維持し、現在の入力を無視する。SSM(1)-(2)は、タイムステップ
で離散化された連続システムとして解釈することができ、この文脈で は、大きな
はシステムが現在の入力に長く集中する(したがって、入力を 「選択」して現在の状態を忘れる)ことを表し、小さな
は過渡的な入力を無視することを表す。
の解釈 。パラメーター
も選択的であり得るが、最終的には
(離散化(4))を介した
との相互作用を通じてのみモデルに影響を与えることに注意する。したがって、
の選択性は
の選択性を保証するのに十分であり、改善の主な原因である。我々は、
に加えて(あるいは
の代わりに)
を選択的にすることで、同様のパフォーマンスが得られると仮定し、簡単のため省く。
と
の解釈。スモデルのコンテクストを効率的な状態に圧縮できるように、無関係な情報をフィルタリングすることである。SSMでは、
と
を選択的に変更することで、入力
を状態
に入れるか、状態を出力
に入れるかをより細かく制御できる。これらは、モデルがそれぞれ内容(入力)と文脈(隠れた状態)に基づいてリカレント・ダイナミクスを調節できるようにすると解釈できる。
3.6 Additional Model Details
実数vs複素数。先行するSSMのほとんどは、状態に複素数を用いており、これは多くのタスクで強力な性能を発揮するために必要である(Gu, Goel, and Ré 2022)。しかし、完全に実数値のSSMは問題なく動作するようであり、いくつかの設定においてはより良い可能性さえあることが経験的に観察されている(Ma et al. 2023)。複素数と実数のトレードオフは、データモダリティの連続-離散スペクトルに関連しており、連続モダリティ(音声、ビデオなど)には複素数が有効だが、離散モダリティ(テキスト、DNAなど)には複素数が有効ではないという仮説を立てた。
初期化。先行するSSMのほとんどは、特に複素数の場合の特別な初期化を提案している。複素数の場合のデフォルトの初期化はS4D-Linであり、実数の場合はHIPPO理論(Gu, Dao, et al. 2020)に基づくS4D-Real(Gu, Gupta, et al. 2022)である。これらはの
番目の要素をそれぞれ
と
と定義する。しかし、多くの初期化は、特に大データや実数値のSSM領域でうまくいくことが期待される。
のパラメータ化。我々は
の選択的調整を
と定義したが、これは
の力学(セクション3.5)に動機づけられたもので、1次元からより大きな次元
に一般化できることがわかる。我々はこれを
の小数とし、ブロック内の主要な線形投影と比較して無視できる数のパラメータを使用する。さらに、ブロードキャスト操作は、1と0の特定のパターンに初期化された別の線形射影と見なすことができる。この射影が訓練可能であれば、これは低ランク射影と見なすことができる
という代替につながる。
我々の実験では、SSMに関する先行研究(Gu, Johnson, Timalsina, et al. 2023)に従い、パラメータ(バイアス項とみなすことができる)は
に初期化される。
備考3.1。我々の実験結果を簡潔にするため、選択的SSMをS6モデルと略すことがある。これは、選択メカニズムを持つS4モデルであり、スキャンで計算されるからである。
付録C:選択的SSMのメカニズム
定理1の証明。、
、
、
、
とした際の選択的SSM(アルゴリズム 2)について考える。これに対応する連続時間SSM(1)は、以下であらわされ、これはリーキー積分器とも呼ばれる。
離散化のステップサイズは、以下。
ここで、パラメータは学習可能なバイアスとみなすことができ、線形射影に折り込まれることがわかる。 ここで0次ホールド(ZOH)離散化公式を適用する:
したがって、最終的な離散漸化式(2a)は、以下のように求められる。
付録D:ハードウェアを意識した選択的SSMのためのアルゴリズム
入力依存の選択性がなければ、SSMはプリミティブとして高速フーリエ変換(FFT)を活用した畳み込みとして効率的に実装できる(Dao, Fu, Saab, et al. 2023; Gu, Goel, and Ré 2022)。選択性を持つSSMはもはや畳み込みと等価ではないが、並列連想スキャンを活用する。SSMスキャンは理論的には効率的だが( FLOPs、
で線形スケーリング)、選択的SSMを用いた基礎モデルの学習には、最新のハードウェア(GPU)でも効率的であることが要求さる。本稿では、カーネル融合と再計算を用いてSSMスキャンを高速かつメモリ効率的に行う方法について述べる。セクション4.5で畳み込みやアテンションと比較した我々のスキャン実装の速度を評価し、シーケンス長32Kでアテンションより最大7倍高速であり、最高のアテンション実装(FlashAttention)と同等のメモリ効率であることを示す。
速度。最新のハードウェアアクセラレータ(GPU)では、ほとんどの演算(行列乗算を除く)はメモリ帯域幅によって制限される(Dao, Fu, Ermon, et al. 2022; Ivanov et al. 2021; Williams, Waterman, and Patterson 2009)。私たちのスキャン演算もこのケースに当てはまり、カーネルフュージョンを使用してメモリIOの量を削減し、標準的な実装と比較して大幅な高速化を実現している。
セクション3. 2 のスキャン・アルゴリズムの標準的な実装方法は、GPU HBM(high-bandwidth memory、一般に GPU メモリと呼ばれる)にサイズのスキャン入力
を準備することで、 並列連想スキャン実装を呼び出して、サイズ
のスキャン出力を GPU HBM に書き込み、そのスキャン出力に
を乗算してサイズ
の出力を生成する。しかし、これには
オーダーのメモリーの読み書きが必要である。代わりに、離散化ステップ、スキャン、
との乗算を1つのカーネルに融合することができる。
バイトのメモリ
を低速HBMから高速SRAMに読み込む。
離散化して、SRAMにサイズ
を生成。
並列連想スキャンを行い、SRAMにサイズ
との乗算と和算を行い、サイズ
このようにして、IOを(状態の次元)のファクターだけ減らすことができ、実際には20~40倍高速化される(セクション4.5)。
シーケンスの長さが長すぎてSRAM(HBMよりはるかに小さい)に収まらない場合は、シーケンスをチャンクに分割し、各チャンクでフューズドスキャンを実行する。中間スキャン状態がある限り、次のチャンクでスキャンを続けることができる。

メモリ。古典的な再計算のテクニックを使って、選択的SSM層の学習に必要なメモリの総量を削減する方法を説明する。
フォワードパスの融合方法から、我々はメモリの爆発を避けるために、サイズの中間状態を保存しない。しかし、これらの中間状態はバックワードパスで勾配を計算するために必要である。その代わりに、これらの中間状態をバックワードパスで再計算する。HBMからSRAMに読み出される入力
と出力勾配は
のサイズであり、入力勾配も
であるため、再計算はHBMから
要素を読み出すコストを回避する。つまり、バックワードパスでSSM状態を再計算することで、それらを保存してHBMから読み出すよりも計算が高速化される。
スキャン操作だけのメモリ要件を最適化するだけでなく、選択的SSMブロック全体(入力投影、畳み込み、活性化、スキャン、出力投影)のメモリ要件を最適化するために再計算を使用する。特に、多くのメモリを消費するが再計算が速い中間活性化(活性化関数の出力や短い畳み込みなど)は保存しない。その結果、選択的SSM層は、FlashAttentionを用いた最適化されたTransformer実装と同じメモリ要件を持つ。特に、各アテンション層(FlashAttention)は1トークンあたり約12バイトの活性化を保存し、各MLP層は1トークンあたり約20バイトの活性化を保存し、合計32バイト(FP16またはBF16での混合精度学習を仮定)となる。各選択的SSMはトークンあたり約16バイトのアクティブを保存する。したがって、2層の選択的SSMは、アテンション層とMLP層とほぼ同じ活性化メモリを持つことになる。
4. Empirical Evaluation
セクション4.1では、セクション3.1で動機付けされた2つの合成タスクを解くMambaの能力をテストする。次に、3つの領域で評価を行い、それぞれ自己回帰の事前学習と下流タスクで評価する。
セクション4.3: DNA配列の事前学習と、長い配列の分類タスクでの微調整。
セクション4.4: 音声波形の事前学習と、自己回帰的に生成された音声クリップの品質。
最後に、セクション4.5では学習時と推論時のMambaの計算効率を示し、セクション4.6ではアーキテクチャと選択的SSMの様々なコンポーネントを除去する。
4.1 Synthetic Tasks
タスクの詳細とトレーニングプロトコルを含む、これらのタスクに関する実験の詳細は付録E.1にある。
4.1.1 Selective Copying
コピータスクはシーケンスモデリングにおいて最もよく研究された合成タスクの一つであり、元々はリカレントモデルの記憶能力をテストするために設計された。セクション3.1で議論したように、LTIのSSM(線形リカレンスとグローバル畳み込み)は、データについて推論する代わりに、時間だけを追跡することで、このタスクを簡単に解くことができる。例えば、正確に正しい長さの畳み込みカーネルを構成することで行われる(図2)。これはグローバル畳み込みに関する以前の研究(Romero et al. 2021)。選択的コピー(Selective Copying)タスクは、トークン間の間隔をランダムにすることで、このショートカットを防ぐ。なお、このタスクは以前にDenoisingタスクとして紹介されている(Jing et al. 2019)。
多くの先行研究が、アーキテクチャゲーティング(乗法的相互作用)を追加することで、モデルに「データ依存性」を付与し、関連するタスクを解決できると主張している(Dao, Fu, Saab, et al. 2023; Poli et al. 2023)。しかし、このようなゲーティングはシーケンス軸に沿った相互作用がなく、トークン間の間隔に影響を与えることができないため、この説明は直感的には不十分だと思われる。特に、ゲーティングアーキテクチャは選択メカニズムの一例ではない(付録A)。
表1から、H3やMambaのようなゲーティングアーキテクチャは部分的にしか性能を向上させないが、選択メカニズム(S4をS6に変更する)は、特にこれらの強力なアーキテクチャと組み合わせた場合に、この課題を簡単に解決することが確認された。

4.1.2 Induction Heads
インダクションヘッド(Olsson et al. 2022)は、機械論的解釈可能性レンズ(Elhage et al. 2021)に基づく単純なタスクであり、LLMの文脈内学習能力を驚くほど予測する。例えば、モデルが「ハリー・ポッター」のようなビッグラムをシークエンスで見たことがある場合、次に同じシークエンスで「ハリー」が現れたとき、モデルは履歴からコピーすることで「ポッター」を予測できるはずである。
データセット。これはこのタスクに関する先行研究(Dao, Fu, Saab, et al. 2023)さらに、テスト時にから
までのシーケンス長の範囲で評価することで、汎化能力と外挿能力を調査した。
モデル。インダクションヘッドに関する確立された研究に従い、我々は2層モデルを使用し、これによりアテンションはインダクションヘッド課題を機械的に解くことができる(Olsson et al.2022)。マルチヘッドアテンション(8ヘッド、様々な位置エンコーディング)とSSMバリエーションの両方をテストする。モデル次元はMambaでは64、他のモデルでは128を使用。
結果。表2から、Mamba、より正確にはその選択的SSM層は、関連するトークンを選択的に記憶し、その間にある他の全てを無視する能力を持つため、タスクを完璧に解く能力を持つことがわかる。他のどの手法も2倍を超えないのに対し、Mambaは100万長シーケンス、つまりトレーニング中に見た長さの4000倍の長さのシーケンスに対しても完璧に汎化する。
アテンションモデルの位置エンコーディングのバリエーションのうち、xPos(これは長さの外挿のために設計された)は他のものよりもわずかに優れている。また、メモリの制限のため、すべてのアテンションモデルはシーケンス長までしかテストされていないことに注意。他のSSMのうち、H3とハイエナは、Poliら(2023)の所見に反して類似している。

4.2 Language Modeling
標準的な自己回帰言語モデリングに関するMambaアーキテクチャを、他のアーキテクチャと比較し、事前学習メトリクス(perpelxity)とゼロショット評価の両方で評価する。モデルサイズ(深さと幅)はGPT3の仕様を反映するように設定した。Pileデータセット(L. Gao, Biderman, et al. 2020)を用い、 Brownら(2020)の訓練方法に従った。すべてのトレーニングの詳細は付録E.2にある。
4.2.1 Scaling Laws
ベースラインとして、標準的なTransformerアーキテクチャ(GPT3アーキテクチャ)と、PaLMおよびLLaMaアーキテクチャ(Roatary Embedding、SwiGLU MLP、LayerNormの代わりにRMSNorm、線形バイアスなし、より高い学習率など)に基づく、我々が知っている最強のTransformerレシピ(ここではTransformer++と呼ぶ)と比較する。また、他の最近のサブ2次アーキテクチャとの比較も行っている(図4)。すべてのモデルの詳細は付録E.2にある。

図4は標準的なChinchilla(Hoffmann et al. 2022)プロトコルの下で、から
パラメータまでのモデルにおけるスケーリング則を示している。Mambaは、特にシーケンス長が長くなるにつれて、現在標準となっている非常に強力なTransformerレシピ(Transformer++)の性能に匹敵する最初のアテンションフリーモデルである。RWKVとRetNetのベースラインは、SSMとしても解釈可能な先行する強力なリカレントモデルであるが、効率的な実装がなされていないため、メモリ不足や非現実的な計算が必要となり、文脈長8kでの完全な結果が得られていない。
4.2.2 Downstream Evaluations
表3は、様々なダウンストリームのゼロショット評価タスクにおけるMambaのパフォーマンスを示している。最も重要なのはPythia (Biderman et al. 2023)とRWKV (B. Peng et al. 2023)であり、これらは我々のモデルと同じトークナイザー、データセット、学習長(300Bトークン)で学習されている。(ただし、MambaとPythiaは文脈長2048、RWKVは文脈長1024で学習している)。

4.3 DNA Modeling
大規模な言語モデルの成功に触発され、最近、基盤モデルのパラダイムをゲノミクスに利用しようという試みがなされている。DNAは、有限の語彙を持つ離散的なトークンのシーケンスから構成されているという点で、言語に例えられている。また、DNAは長距離の依存関係をモデル化する必要があることでも知られている(Avsec et al. 2021)。我々は、DNAの長鎖モデルに関する最近の研究(Nguyen, Poli, et al. 2023) と同じ設定で、MambaをプリトレーニングとファインチューニングのためのFMバックボーンとして調査する。特に、モデルサイズと配列長に渡るスケーリング則の2つの探索(図5)と、長い文脈を必要とする難しい下流の合成分類タスク(図6)に焦点を当てる。
事前学習では、学習とモデルの詳細について、標準的な因果言語モデリング(次のトークン予測)のセットアップにほぼ従う(付録E.2も参照)。データセットについては、HyenaDNA(Nguyen, Poli, et al. 2023)のセットアップをほぼ踏襲している。HyenaDNAは、約45億のトークン(DNA塩基対)を持つ単一のヒトゲノムで構成されるHG38データセットを事前学習に用いている。

4.3.1 Scaling: Model Size
この実験では、様々なモデルのバックボーンを用いて、ゲノミクス基盤モデルのスケーリング特性を調べる(図5左)。
訓練。セクション4.3.2で示したように、配列長が長くなるとMambaがより有利になることが予想される。グローバルバッチサイズを1024に固定し、1バッチあたりトークンを学習する。モデルは
の勾配ステップで学習され、合計
のトークンが学習された。
結果。図5(左)は、Mambaの事前学習の複雑さがモデルサイズとともに滑らかに向上すること、そしてMambaがHyenaDNAとTransformer++の両方よりも優れたスケールを持つことを示している。例えば、最大のモデルサイズであるパラメータでは、MambaはTransformer++とHyenaDNAのモデルにおよそ3倍から4倍少ないパラメータで匹敵することを示している。
4.3.2 Scaling: Context Length
次のDNA実験では、配列長に対するモデルのスケーリング特性を調べる。配列長が長くなると2次アテンションは法外に高価になるため、HyenaDNAとMambaモデルのみを比較する。配列長、
、
、
、
、
でモデルを事前訓練する。モデルサイズは6層×幅128(約1.3M-1.4Mパラメータ)とした。モデルは
勾配ステップで合計
トークンで学習された。配列長が長い場合は、(Nguyen, Poli, et al. 2023)と同様の配列長ウォームアップを用いた。
結果 図5(右)は、Mambaが長さ1Mの非常に長い配列まで、より長い文脈を利用することができ、文脈が増えるにつれて事前学習のperplexityが向上することを示している。一方、HyenaDNAモデルは配列の長さとともに悪化する。これはセクション3.5の選択メカニズムの特性に関する議論から直感的に理解できる。特に、LTIモデルは情報を選択的に無視することはできない。畳み込みの観点から見ると、非常に長い畳み込みカーネルは、非常にノイズが多い可能性のある長いシーケンス全体のすべての情報を集約することになる。HyenaDNAは文脈が長いほど改善すると主張しているが、その結果は計算時間を制御していないことに注意されたい。
4.3.3 Synthetic Species Classification
DNAの連続するセグメントをランダムにサンプリングして5つの異なる種を分類するという下流のタスクでモデルを評価する。このタスクは、{ヒト、キツネザル、マウス、ブタ、カバ}の種を用いたHyenaDNAから採用した。我々は、DNAの99%を共有することが知られている5種の類人猿{ヒト、チンパンジー、ゴリラ、オランウータン、ボノボ}の間を分類することで、かなり難易度の高いタスクに変更した。
4.4 Audio Modeling and Generation
音声波形モダリティについては、主にSaShiMiアーキテクチャと学習プロトコル(Goel et al. 2022)を比較する。 このモデルは、
U-Netバックボーンと、各ステージごとにモデル次元
を2倍にする係数
による2段階のプーリング
各ステージにおけるS4ブロックとMLPブロックの交互配置
から構成される。
S4+MLP ブロックを Mamba ブロックに置き換えることを検討した。実験の詳細は付録 E.4 を参照。
4.4.1 Long-Context Autoregressive Pretraining
YouTubeMix(DeepSound 2017)で事前学習品質(自己回帰次サンプル予測)を評価する。YouTubeMixは、16000Hzのレートでサンプリングされた4時間のピアノ独奏曲からなる、先行研究で使用された標準的なピアノ音楽データセットである。 事前学習の詳細は、ほぼ標準的な言語モデリングのセットアップ(セクション4.2)に従う。図7は、学習シーケンスの長さをから
まで増加させた場合の効果を評価したものである。(データの扱い方に若干のエッジケースがあるため、スケーリング曲線にねじれが生じる可能性がある。例えば、分単位のクリップしか利用できなかったため、最大配列長は
で結ばれている)。
MambaとSaShiMi(S4+MLP)のベースラインは、コンテキストの長さが長くなるにつれて一貫して改善する。主な指標はバイトあたりのビット数(BPB)であり、これは他のモダリティを事前学習するための標準的な負の対数尤度(NLL)損失の一定係数log(2)である。
この論文で、実数パラメータ化から複素数パラメータ化(セクション3.6)に切り替えたのはこの実験だけである。付録E.4で追加のアブレーションを示す。
4.4.2 Autoregressive Speech Generation
SC09はベンチマーク音声生成データセット(Donahue, McAuley, and Puckette 2019; Warden 2018)であり、16000Hzでサンプリングされた「0」から「9」までの数字の1秒クリップで構成され、非常に可変的な特性を持つ。我々はGoelら(2022)の自己回帰学習セットアップと生成プロトコルにほぼ従っている。
表4は、Goelら(2022)の様々なベースラインと比較したMamba-UNetモデルの自動化指標を示している。比較対象は、WaveNet (Oord et al. 2016)、SampleRNN (Mehri et al. 2017)、WaveGAN (Donahue, McAuley, and Puckette 2019)、DiffWave (Z. Kong et al. 2021)、SaShiMiである。小さなMambaモデルは、最先端の(そしてはるかに大きな)GANと拡散ベースのモデルを凌駕する。ベースラインにパラメータを合わせたより大きなモデルは、忠実度メトリクスをさらに劇的に改善する。
表5は、小さなMambaモデルを用いて、外側のステージと中央のステージの異なるアーキテクチャの組み合わせを調べたものである。外側のブロックではMambaがS4+MLPよりも一貫して優れており、中央のブロックではMamba > S4+MLP > MHA+MLPであることがわかる。

4.5 Speed and Memory Benchmarks
図8では、SSMスキャン操作(状態拡張)の速度と、Mambaのエンドツーエンドの推論スループットをベンチマークしている。我々の効率的なSSMスキャンは、シーケンス長2Kを超えると、我々の知る限り最高のアテンション実装(FlashAttention-2(Dao 2023))よりも高速であり、PyTorchの標準的なスキャン実装よりも最大20-40倍高速である。Mambaは、KVキャッシュがないため、同じようなサイズのTransformerよりも4-5倍高い推論スループットを達成している。例えば、Mamba-6.9B(未訓練)は、5倍小さいTransformer-1.3Bよりも高い推論スループットを持つ。詳細は付録E.5を参照のこと。付録E.5にはメモリ消費量のベンチマークも含まれている。

4.6 Model Ablations
チンチラのトークン数(図4と同じ設定)で、サイズのモデルで言語モデリングの設定に焦点を当てて、私たちのモデルのコンポーネントの一連の詳細な切除を実行する。
4.6.1 Architecture
表6は、アーキテクチャ(ブロック)とその内側のSSM層(図3)の効果を調べたものである。
我々は、以下のことを発見した。
これまでの非選択的(LTI)SSMのうち、グローバル畳み込みに相当するものでは、性能は非常によく似ている。
このことは、ハードウェア効率を考慮すると、(少なくともLMでは)実数値SSMの方が良い選択であることを示唆している。
これらのいずれかを選択的SSM(S6)に置き換えると性能が大幅に向上し、セクション3の動機が検証される。
付録E.2.2では、MambaブロックとMLP(伝統的なアーキテクチャー)MHA(ハイブリッ ドアテンションアーキテクチャー)などの他のブロックとのインターリーブも調査している。

4.6.2 Selective SSM
表7は、選択的なパラメータ(アルゴリズム2)の異なる組み合わせを考慮することにより、選択的なSSM層を切除し、RNNゲーティング(定理1)との関係により、
が最も重要なパラメータであることを示している。
表8は、SSMの異なる初期化を考慮したもので、いくつかのデータモダリティや設定において大きな違いがあることが示されている(Gu, Goel, and Ré 2022; Gu, Gupta, et al. 2022) 。言語モデリングでは、より標準的な複素数値のパラメータ化(S4D-Lin、1行目)ではなく、より単純な実数値の対角初期化(S4D-Real、3行目)の方が良い結果が得られる。ランダムな初期化もうまくいき、先行研究(Mehta et al. 2023)の結果と一致する。
表9と表10は、それぞれと
プロジェクションの次元を変えることを検討している。静的な投影から選択的な投影に変更することで、最も大きな効果が得られるが、次元をさらに増やすと、一般的に、パラメータ数が少し増えるだけで、性能がわずかに向上する。
特に注目すべきは、状態サイズを大きくしたときの選択的SSMの劇的な改善であり、わずか1%の追加パラメータのコストで1.0以上のperplexsityの改善が見られる。これは3.1節と3.3節で述べた我々の動機の核心を検証するものである。
5. Discussion
関連する仕事、限界、将来の方向性について述べる。
関連研究。付録Aは、選択メカニズムが類似の概念とどのように関連しているかを論じる。付録Bは、SSMと他の関連モデルの拡張された関連作業である。
ノーフリーランチ: 連続-離散スペクトル。 構造化SSMはもともと連続システムの離散化として定義され(1)、知覚信号(例:オーディオ、ビデオ)のような連続時間データモダリティに強い帰納的バイアスを持つ。セクション3.1と3.5で議論したように、選択メカニズムはテキストやDNAのような離散モダリティでの弱点を克服しているが、これは逆にLTI SSMが得意とするデータでの性能を阻害する可能性がある。音声波形に関する我々のアブレーションでは、このトレードオフをより詳細に検証している。
ダウンストリーム・アフォーダンス Transformerベースの基盤モデル(特にLLM)には、微調整、適応、プロンプト、コンテキスト内学習、命令チューニング、RLHF、量子化など、事前学習されたモデルとの相互作用の特性や態様の豊かな生態系がある。私たちは、SSMのようなTransformerの代替手段が同様の特性やアフォーダンスを持っているかどうかに特に興味がある。
スケーリング。我々の実証的な評価は小さなモデルサイズに限定されており、ほとんどの強力なオープンソースLLM(例えばLlama(Touvron et al. 1023))や、RWKV(B. Peng et al. 2023)、RetNet(Y. Sun et al. 2023)などの他のリカレントモデルと同様に、7Bパラメータスケール以上で評価されている。Mambaがこのような大きなサイズでも有利に比較できるかどうかを評価する必要がある。また、SSMのスケーリングには、本論文では議論していない更なる工学的な課題やモデルの調整が含まれる可能性があることに注意する。
6. Conclusion
我々は構造化状態空間モデルに選択メカニズムを導入し、シーケンスの長さを線形にスケーリングしながら、コンテキスト依存の推論を行うことを可能にする。単純なアテンションフリーアーキテクチャに組み込むことで、Mambaは多様なドメインにおいて最先端の結果を達成し、強力なTransformerモデルの性能に匹敵するか、それを上回る。我々は、選択的状態空間モデルが、様々なドメイン、特にゲノム、オーディオ、ビデオなどの長い文脈を必要とする新しいモダリティのための基礎モデルを構築するための幅広い応用に期待している。我々の結果は、Mambaが一般的な配列モデルのバックボーンとなる有力な候補であることを示唆している。