今日の論文2023/05/03:SKILL: Structured Knowledge Infusion for Large Language Models.
SKILL: Structured Knowledge Infusion for Large Language Models.
Fedor Moiseev, Zhe Dong, Enrique Alfonseca, and Martin Jaggi. 2022. SKILL: Structured Knowledge Infusion for Large Language Models. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 1581–1588, Seattle, United States. Association for Computational Linguistics.
©2022 Association for Computational Linguistics
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容に基づき筆者が要約または翻訳したものです。以下の図は、そこから引用しています。
This article is my summary or translation based on the content of the original publication. The following figures are taken from it.
要点まとめ
大規模言語モデル(LLM)は、膨大な数の自然言語タスクにおいて、人間レベルの性能を実証してきた。しかし、知識グラフのような構造化されたデータから、あるいはテキストから、よりよく知識を取り込むことができるかどうかは、ほとんど未解明である。本研究では、知識グラフ(KG)の事実のトリプレットをT5モデルに直接学習させることで、LLMに構造化知識を注入する方法を提案する。
本手法を用いてWikidata KGで事前訓練したモデルは、FreebaseQAとWikiHop、さらにTriviaQAとNaturalQuestionsのWikidata回答可能サブセットにおいてT5ベースラインを上回る性能を持つことを明らかにする。事実のトリプレットで事前に訓練されたモデルは、同じ知識を含む自然言語文のモデルと比べて競争力がある。また、より小さなサイズのKGであるWikiMoviesで訓練したところ、MetaQAtaskの完全一致スコアがT5ベースラインと比較して3倍向上したことが確認された。提案手法は、知識グラフとテキストコーパスの間のアライメントが不要であるという利点がある。このため、本方法は業界規模の知識グラフを扱う場合に特に有効である。
序論
BERT(Devlin et al., 2019)、GPT-3(Brown et al., 2020)、T5(Raffel et al., 2019)、REALM(Guu et al., 2020)、ERNIE(Sun et al., 2021)などの大規模事前学習済み言語モデルは、多くのタスクでSoTAとなってきた。 これらは、一般に、構造化されていないテキスト群を用いて、next word prediction、next sentence prediction(NSP:next sentence prediction)、masked language modeling(MLM)などのタスクで事前学習される。特にT5では、MLMを用いたラベルなしテキストコーパスの自己教師あり学習が一般的な事前学習方法となっている(Roberts et al., 2020)。通常、この後、目的のタスクのファインチューンが行われるが(Ruder et al., 2019)、大規模な言語モデルは、タスク固有のファインチューンなしで有用であることも証明されている(Brown et al., 2020)。
文脈を理解する能力を超えて、人間レベルの言語理解は、世界に関する知識を軸にしている。世界に関する知識は、しばしば、(主語:subject entity, 関係:relation, 目的語:object entity)で表される事実のトリプレット(三つ組)として表現される(Jiet al., 2020)。事実のトリプレットによって定義される知識グラフ(KG)は、主語と目的語を頂点/ノードとし、それらを結ぶエッジを形成する関係(リレーション)からなる。大規模なKG(例:Wikidata, Vrandeˇci ́c and Krötzsch, 2014)の多くは、トリプレット形式となっている。
LLMは、自然テキストコーパスから世界の知識を学習する能力を持つが(Roberts et al., 2020)、構造化されたKGトリプレットや、それらを明示的に記述したテキストから直接新しい知識を学習・記憶することがどの程度可能かは不明である。
LLMに知識を注入するためには、知識ベースのテキストバージョンを生成し、MLMなどの標準的学習課題を適用するという選択肢も考えられる。これは残念ながら非常に非自明なことである。ERNIE(Sun et al., 2021)で行われているように、文章をKGトリプレットに合わせるか、KELM(Agarwal et al., 2021)で行われているように、トリプレットから文章を生成するかのどちらかである。これらのアプローチは、残念ながら異なるスキーマを持つ知識グラフに移植することは困難である。また、これらの処理は、すべてのトリプレットが揃うわけではなく、有効な文が生成されるわけでもないという欠点があり、元のKGに存在するバイアスに加えて、不必要な選択バイアスが生じる可能性があるかどうかについては、十分に理解されてはいない。
本研究では、LLMが知識のトリプレットから直接学習するKnowledge Infusion for Large Language Models(SKILL)という手法を提案する。実験の結果、WikidataKGで提案手法により学習されたチェックポイントは、4つの標準的なClosded-book質疑応答(QA)タスクにおいてT5ベースラインを上回った。また、より小さなKGであるWikiMoviesでは、提案手法はMetaQAタスクにおいて3倍の完全一致スコアの性能を向上させた。また、知識トリプレットから直接学習するモデルは、同じ量の知識を含む自然文を並べたモデルと同等の性能を示した。さらに、知識トリプレットから直接学習できることで、言語モデリングの事前訓練に構造化知識を簡単に追加できる。
関連研究
知識集約的なダウンストリームタスクの品質を向上させるために知識グラフを利用する先行研究は、推論時に知識グラフを利用するグループと、事前学習時にモデル重みに知識を融合させるグループの二つに分けられる。提案手法は後者のグループに属する。
知識グラフの明示的な利用:外部の記憶やソースから知識を検索して適用するために、検索補強モデル(retrieval-augmented model)が一般的に使用される。FILM (Vergaet al., 2021)とEaE (Févry et al., 2020)はTransformer (Vaswani et al., 2017) モデルを外部のエンティティ (FILMとEaE両方) そして事実(FILM)のメモリ―によって拡張する。REALM(Guu et al., 2020)は、推論中に大規模なテキスト知識コーパスに対する推論をon-the-flyで実行するように事前に訓練されている。UniK-QA(Oguz et al., 2020)は、オープンドメインのQAタスクを改善するために、構造化情報と非構造化情報を、retriever-reader frameworkで結合している。提案手法であるSKILLと検索補強モデルとの主な違いは、SKILLは検索システムや外部記憶をモデルに導入せず、知識をモデルパラメータに直接埋め込むため、推論時に余分なコストが発生しない。
知識注入:パラメータ化した知識注入の一般的な方法は、構造化した知識を自然言語テキストにマッピングまたは変換することだ。ERNIE 3.0 (Sun et al., 2021) は、トリプレットとその整列された文を組み合わせたコーパスに、トリプレット内のリレーションや文中の単語をランダムにマスクすることによって、知識強化モデルを学習する。一方、SKILはトリプレットに対してのみ訓練する。 KnowBert(Peters et al., 2019)は、WikipediaとWordNet(Miller, 1995)からの知識を、知識アテンションと再文脈化メカニズムを持つエンティティ埋め込みを通じてBERTモデルに組み入れるものである。BERT-MK(He et al., 2020)は、医療KGのグラフコンテキスト知識を統合するBERTベースのモデルであり、グラフレベル知識の有用性を実証している。
KG-FiD (Yu et al, 2021) は、Fusion-in-Decoder モデル (Izacard and Grave, 2021) を、知識グラフの構造的な接続に基づいて、文章をフィルタリングして再ランク付けするモジュールで拡張した。私たちが提案するSKILL法とは対照的に、知識グラフの各エンティティを記述する自然文の存在を必要とするため、エンティティを記述する記事を自然に提供するWikipediaコーパスを使用した。
Heinzerling and Inui (2021)は、知識グラフから情報を記憶し理解する言語モデルの能力を研究したが、構造化表現ではなく、事前定義されたテンプレートに基づくトリプレットの自然言語表現を使用した。定義済みのテンプレートを使用すると、スケーラビリティが著しく低下するため、Google-REなどの比較的小さな知識グラフのみを使用した。
本稿で紹介する新しい手法とは対照的に、これらのアプローチはいずれも、知識グラフのエンティティや事実と対応する自然言語センテンスとの間に明示的なマッピングを必要とするため、そのようなマッピングを持たない業界規模の知識グラフへの適用を制限する可能性がある。
知識グラフを使用する際の異なる目標:一方で、知識をモデルの重みに埋め込むが、下流タスクのパフォーマンスを向上させるのではなく、異なる目標を追求する論文もある。COMET(Bosselut et al., 2019)は、我々の研究に最も似ており、構造化された知識を与えられた自然言語で、緩やかに構造化されたコモンセンス記述を生成することを学習することによって、コモンセンス認識のトランスフォーマー言語モデルを訓練する。我々と同様に、表面形のKGトリプレットも訓練データのソースとして使用しているが、我々の研究とは異なり、COMETの最終目標は、既存の知識を利用するのではなく新しい知識を生成することである。もう一つの重要な違いは規模であり、COMETは、Wikidata(Vrandeˇci ́candKrötzsch, 2014)よりもはるかに小さいAtomic(Sap et al., 2019)およびConceptNet(Speer et al., 2017)ナレッジグラフを使用している。
KELM(Agarwal et al., 2021)は、T5モデルをファインチューンしてKGを合成自然言語文に変換し、既存の事前学習コーパスを補強する。我々はこの上に研究を構築し、KELMデータセットを使用して、知識の構造化表現と自然言語表現を比較する。
手法
LLMのための知識注入(SKILL)には、コーパスと学習方法という2つの要素がある。ここではWikidata KGに基づいた方法を紹介するが、他のKGにも適用可能である。
訓練コーパス:WikidataKG(Vrandeˇci ́c and Krötzsch, 2014)のトリプレットフォーマットと、WikidataKGから変換した合成自然言語文のKELMコーパス(Agarwal et al, 2021)の知識表現が異なる2つのコーパスを使用する。KELMコーパスには15,628,486文の合成文が含まれている。 2つのコーパラが同じ知識を共有するために、KELMコーパスの作成に使用した35,697,715トリプレットを含むWikidata KGのスナップショットを取得した。 自然言語理解におけるモデルの性能低下を防ぐために、知識注入訓練データに対してWikidataコーパスまたはKELMコーパスとC4 (Raffel et al. 2019) の自然文を50:50の比率で混合する、
学習方法:T5 (Raffel et al., 2019)は、ランダムスパンがマスクされているC4コーパスに対して、MLMによって訓練された。Robertset et al. (2020)は、T5モデルの事前学習において、ランダムトークンスパンをマスクする代わりに、重要な用語をマスクする(Guuet al., 2020)と、下流のタスク、例えばClosed Book QAでのパフォーマンスが大幅に改善されることを発見した。
我々は知識融合学習において、教師なし学習用の重要なスパンのマスキングを適用する。 両者の情報量が同じになるように、次のような方法を適用している。 知識トリプレットの場合、主語と目的語のどちらかをマスクする。KELM文の場合は、付録Aにあるように、整列したトリプレットを特定し、そのトリプレットの主語または目的語に対応するフルスパンをマスクする。知識トリプレットの抽象的な関係をKELM文の自然言語トークンに対応させる確実な方法がないため、関係(relation)トークンはマスクされない。両コーパスの入力の例を表1に示す。

実験
SKILLを、知識を注入したモデルを、文脈や外的知識の裏付けがない状態で出題されるclosed-bookQAタスクで訓練し、評価することによって調査する。
実験セットアップ
SKILL事前学習:SKILLをそれぞれ約200M、約800M、約11Bのパラメータを持つ三つのT5.1.1事前学習済みのチェックポイント、base、large、XXLに適用する。T5.1.1-baseと-largeでは、500Kステップ、バッチサイズ1024でSKILL学習を行い、これはWikidata KGでは約7.17エポック、KELM文では約16.38エポックに相当する。T5.1.1-XXLでは、実現可能な時間で学習を終了するため、100Kステップでモデルを学習している。
ベースラインとして、同じサイズの事前学習済みT5チェックポイントを使用している。また、C4の事前学習を長く行うのではなく、知識の注入による改善を確認するため、SKILLで使用したC4の事前学習量に合わせ、前述の半分のステップでT5チェックポイントをC4でさらに学習させ、第2のベースラインを使用する。
すべてのモデルバリエーションは、T5で使用されたのと同じ設定であるの学習率とドロップアウト率
でAdaFactor(Shazeer and Stern, 2018)によって最適化される。
Closed-bookQAタスクでのファインチューニング:我々は、以下のQAベンチマークで微調整を行うことによってチェックポイントを評価する: FreebaseQA (Jianget al., 2019)、WikiHop(Welbl et al., 2018)、Triv-iaQA (Joshi et al., 2017)そしてNaturalQuestions(Kwiatkowski et al., 2019)を、前述の最適化のためのハイパーパラメーターと128バッチサイズに設定した。テストデータのないベンチマークでは、テストに検証データを使用し、最後の10%の訓練データを検証データとして使用している。すべてのモデルは、EMスコアによる検証セットで、目立たないオーバーフィッティングで収束した。
T5.1.1-baseと-largeモデルについては50Kステップ、-XXLモデルについては10Kステップでファインチューンした後、テストセットの完全一致 (EM) スコアを算出した。
Wikidata-answerableQA:FreebaseQAとWikiHopの質問の大部分は、Wikidataのトリプレットから直接答えることができることがわかった。これは、FreebaseQAがFreebase(Bollacker et al., 2008)のトリプレットと質問-回答のペアをマッチングすることで作成され、そのほとんどがWikidata(Vrandeˇci ́c and Krötzsch, 2014)にインポートされたためである。
しかし、TriviaQAとNaturalQuestionsはWikidataから独立して作成され、すべての質問にこの知識ベースを使用して回答できるわけではない。例えば、「イギリス最大のスーパーマーケットチェーンはどこですか?」の正解は「Aldi 」だが、今日では 「Tesco 」になっているなど、知識の新しさの問題が頻繁に見受けられる。例えば、「1984年にラジオのマイクテスト中に『私はロシアを永遠に違法化する法案に署名しました。5分後に爆撃が始まります。』と言ったのは誰ですか?」の答えが「ロナルド・レーガン」であるなど、その他、WikiDataでは答えられない質問もある。
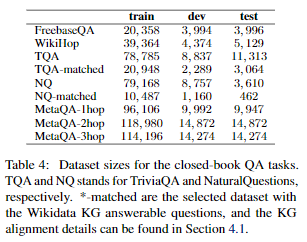
これを軽減するために、Wikidataに答えがある可能性が高いTriviaQA(TQA)とNaturalQuestions(NQ)のサブセットを作成した。ウィキデータに答えが主語か目的語になっているトリプレットが存在し、トリプレット内の他のエンティティが質問で言及されている項目をすべて選択した。大文字と小文字を区別せず、エンティティ名でマッチングする。TQAとNQのwikidata連携版をそれぞれTQA-matched、NQ-matchedと名付ける。すべてのQAタスクのデータセットサイズは、付録Bにまとめられている。
結果
Closed-bookQAタスクの結果を表2にまとめた、SKILLで学習したモデルは,FreebaseQA、WikiHop、Wikidataで回答可能なTriviaQAとNaturalQuestionsでは改善したが、オリジナルのTriviaQAとNaturalQuestionsでは大きな改善はなかった。 前節で述べたように、これはデータセットとWikidataとの不整合によるものと考えられる。
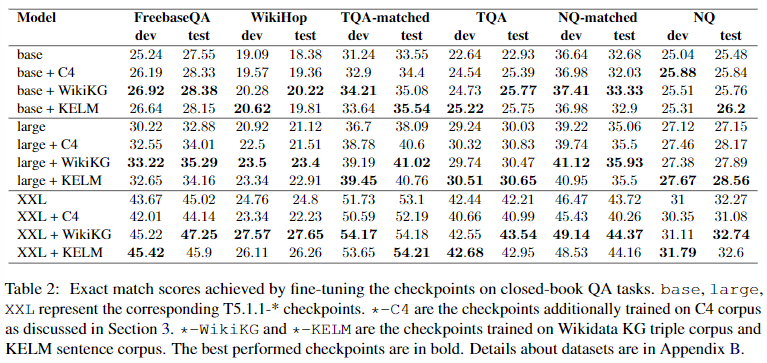
Wikidata KGで事前に学習したモデルは、KELMの文章で学習したモデルと同等の結果を得ることができた。その結果、トリプレット表現が自然言語表現と同程度の性能を持ちながら、より大きなKGに対してより容易にスケールアップできることが示された。
T5.1.1-baseと-largeでは、C4に対する事前学習が追加され、元のベースラインと比較して性能が向上していることがわかる。T5.1.1-XXLでは、この追加的な事前学習により、性能が後退する。(Raffel et al., 2019)では、C4で複数回学習すると、T5モデルの性能が低下することが述べられている。
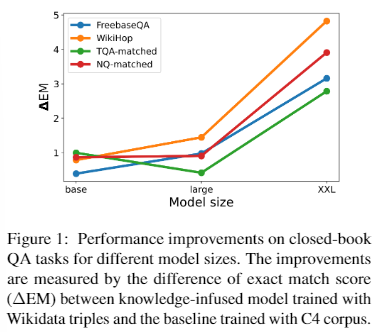
モデルサイズの影響:図1に示すように、大きなモデルに適用すると、SKILL事前学習は大きな改善をもたらすことがわかる。Wikidata KGには35M以上のトリプレットがあり、300Mパラメータを持つT5.1.1.-baseのような小さなサイズのモデルでは、効率的に記憶することが難しくなっている。この結果は、モデルサイズが大きくなるにつれて、SKILLの事前学習による利益がさらに増加する可能性を示唆しており、励みになる結果だと考えている。
より小さなKGでのパフォーマンス:Wiki-Movies KG(Miller et al., 2016)は134,741個のトリプレットを含んでいる。T5.1.1-largeは、KGを記憶するのに十分なパラメーターを持つはずである。我々は、Wikidata KGと同じハイパーパラメータで、KG上で100Kステップ、約380エポックのT5.1.1-largモデルを訓練する。我々は、WikiMovies KG上で構築したMetaQA(Zhang et al., 2018)ベンチマークでチェックポイントを評価する。このベンチマークには、3つの異なるサブタスクが含まれている。1-hop QA(例:「Paresh Rawalはどんな映画に出演しているか」)、2-hop QA(例:「LauraKerrが書いた映画の監督は誰か」)、3-hop QA(例:「ミレニアム女優の作家が書いた映画の監督は誰か」)の三つである。
表3の結果は、知識グラフ全体を記憶することが可能な場合、SKILLの事前学習が有効であることを示している。
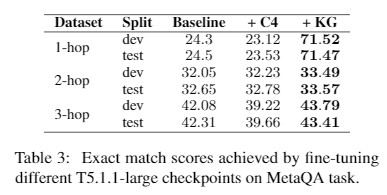
WikiMoviesのKGでは、1-hopの質問が一つのトリプレットによってサポートされているため、このサブタスクではEMスコアが3倍向上していることが確認された。2-hopと3-hopの質問に答えるためには、トリプレットを記憶するだけでは不十分であり、モデルはトリプレットを使って推論することができる必要がある。 そのためには、グラフ構造をより深く理解する必要がある。単一のトリプレットを用いたトレーニングでは十分でない可能性があり、観測された改善は顕著に小さい。訓練データにおいてグラフ構造をより明示的に表現することで、性能はさらに向上する可能性があるが、これは将来の研究に委ねられる。
結論
事前学習により、ナレッジグラフの知識をT5モデルに直接注入する方法を提案した。 その結果、T5が構造化データから直接学習し、学習した知識を適用することで、クローズドブックQAの結果を改善できることが実証された。 また、事実関係のトリプルで事前学習したモデルは、同じ知識を含む自然言語文のモデルと競合することを実証した。トリプレットから直接知識を注入することで、この方法は産業スケールのKGに非常に簡単に適用することができる。
付録A
WikidataのKGエンティティを対応するKELM文から見つけるに、Algorithm 1を使用する。22行目の追加サイクルが必要なのは、例えばJohn Doe (born1990) のように、エンティティによっては括弧内に文中に存在しないはずの情報を持っているためである。 このアルゴリズムでは、15,628,486文のKELM文のうち、15,383,248文に少なくとも1つのエンティティをマッチさせた。
トリプレットの関係(relation)部分は、さまざまな形で表現できるため、マッチングは試みない。例えば、(Pulp Fiction, cast member, John Travolta)というトリプルは、"John Travolta was an actor in Pulp Fiction"、"John Travolta starred in Pulp Fiction"、"John Travolta played Vincent Vega in Pulp Fiction"などのように表すことができ、すべての可能な表面形に対して関係を堅牢に整合する方法は存在しない。

付録B
Wikidata(Vrandeˇci ́c and Krötzsch, 2014)はCreative Commons CC0 Licenseでリリースされた。KELM (Agarwal et al., 2021)はCreative Commons CC BY-SA 2.0 Licenseでリリースされた。NaturalQuestions(Kwiatkowski et al, 2019)とWikiHop(Welbl et al., 2018)はCreative Commons CC BY-SA 3.0 Licenseの下でリリースされた。MetaQA(Zhang et al., 2018)はCreative Commons CC BY-ND 3.0 Licenseの下でリリースされた。 C4(Raffel et al., 2019)とTriviaQA)Joshi et al., 2017)はApache-2.0 Licenseでリリースされた。WikiMovies(Miller et al., 2016)はMIT Licenseでリリースされている。FreebaseQA (Jiang et al., 2019)はライセンス無しでリリースされた。
FreebaseQA