Diffusionモデル学習記録④ ―Scalable Diffusion Models with Transformers
Preface
せっかく著者がCC-BYにしてくれていたので、今回はクリスマスプレゼントとして、クリスマス前から巷をにぎわせているScalable Diffusion Models with Transformersを翻訳する。
William Peebles, Saining Xie: Scalable Diffusion Models with Transformers, arXiv:2212.09748
©William Peebles, Saining Xie, Originally posted in arXiv(https://arxiv.org/abs/2212.09748), Mon, 19 Dec 2022
License: Creative Commons Attribution 4.0 International (CC-BY)
以下は、原文を翻訳したもので、以下の図はそこから引用したものです。
The following is the translation of the original content and the figures below are retrieved from it.
- Preface
- Scalable Diffusion Models with Transformers
- Diffusion Transformers
- 4. Experimental Setup
- 5. Experiments
- 5.1. State-of-the-Art Diffusion Models
- 5.2. Model Compute vs. Sampling Compute
- 6. Conclusion
- Apendix (The figures in the appendix are only part of the original contents.)
- References
Scalable Diffusion Models with Transformers

Abstract
本論文では、トランスフォーマーアーキテクチャーに基づく新しいクラスの拡散モデルについて述べる。 我々は、一般的に使用されるU-Netバックボーンを、潜在パッチ上で動作するトランスフォーマーと置き換えて、画像の潜在拡散モデル(Lattent Diffusion Model)を学習した。 我々は、Gflopsで測定される順方向の複雑さの視点から、我々の拡散トランスフォーマー(DiT)のスケーラビリティを分析した。 その結果、トランスフォーマーの深さや幅、入力トークンの数を増やすことでGflopsを高めたDiTは、一貫してFIDを低く抑えられることが分かった。また、良好なスケーラビリティ特性を有しているのに加え、クラス条件付きImageNet 512×512および256×256ベンチマークにおいて、DiT-XL/2の最大モデルはすべての先行拡散モデルよりも優れた性能を示し、後者においては2.27という最新のFIDを達成した。
1. Introduction
機械学習はトランスフォーマーによってルネッサンスを迎えている。 過去5年間で、自然言語処理[8, 39]、視覚(コンピュータヴィジョン)[10]、その他いくつかの領域のためのニューラルアーキテクチャは、トランスフォーマー[57]にほぼ吸収されてきた。しかし、画像レベルの生成モデルモデルの多くは、このトレンドにの乗れていない。トランスフォーマーは自己回帰モデル[3, 6, 40, 44]では広く使われているが、他の生成モデリングのフレームワークではあまり採用されていないようである。例えば、拡散モデルは、画像レベルの生成モデル[9,43]における最近の進歩の最前線にも関わらず、それらはすべて、バックボーンの事実上の選択として畳み込みU-Netアーキテクチャを採用している。
Hoetら[19]は、拡散モデルにU-Netバックボーンを最初に導入した。 この設計上の選択は、自己回帰生成モデルである PixelCNN++ [49, 55] から継承されたものであり、いくつかのアーキテクチャ上の変更がなされている。このモデルは畳み込み型で、主にResNet [15] ブロックで構成されている。標準的なU-Net [46]とは対照的に、トランスフォーマーの重要な構成要素である空間的な自己注意ブロックが追加され、低解像度で散在している。DhariwalとNichol [9]は、条件情報と畳み込み層のチャンネル数を注入するために、適応的正規化層[37]を使用するなど、U-Netのアーキテクチャの選択についていくつか検討している。しかし、HoetらのU-Netの高いレベルのデザインはほぼそのまま残ったままである。
この研究で、我々は拡散モデルにおけるアーキテクチャ選択の重要性を解明し、将来の生成モデル研究のための経験的なベースラインを提供することを目的とする。その結果、U-Netの帰納バイアスは拡散モデルの性能にとって重要ではなく、トランスフォーマーのような標準的な設計で容易に置き換えることができることが分かった。その結果、拡散モデルは、最近のアーキテクチャーの統一化というトレンドの恩恵を受けるのに適していることが分かった。例えば、他のドメインのベストプラクティスやトレーニングレシピを継承し、スケーラビリティ、ロバスト性、効率性などの好ましい特性を保持することができる。しかも、 標準化されたアーキテクチャは、分野横断的な研究の新たな可能性を開くものでもある。
本論文では、トランスフォーマーに基づく新しい拡散モデルに焦点を当てる。我々はそれらをDiffusion Transformers、または短くDiTsと呼ぶ。DiTsは、従来の畳み込みネットワーク(例えば、ResNet [15])よりも視覚認識に対して効果的にスケーリングすることが示されているVision Transformers (ViTs) [10]のベストプラクティスに準拠している。
より具体的には、我々は、ネットワークの複雑さ vs. サンプルの質に関するトランスフォーマーのスケーリング挙動を研究する。我々は、拡散モデルがVAEの潜在空間内で学習されるLatent Diffusion Models(LDMs) [45]の枠組みの下でDiTデザイン空間を構築しベンチマークすることにより、U-Netバックボーンをトランスフォーマーで置き換えることに成功することを示す。さらに、DiTが拡散モデルのためのスケーラブルなアーキテクチャであることを示す。というのも、ネットワークの複雑さ(Gflopsで測定)vs. サンプルの品質(FIDで測定)の間に強い相関があるのである。DiTをスケールアップし、大容量のバックボーン(118.6 Gflops)を持つLDMをトレーニングするだけで、クラス条件付き256×256ImageNet生成ベンチマークにおいて2.27FIDというSOTAを達成することができた。
2. Related Work
Transformers
Transformers [57]は言語、視覚(コンピュータヴィジョン)[10]、強化学習 [5, 23]、メタ学習 [36]において、ドメイン固有のアーキテクチャを置き換えてきた。また、言語領域[24]、汎用自己回帰モデル[17]、ViT[60]において、モデルサイズ、学習量、データが増加する中で顕著なスケーリング特性を示した。言語を超えて、トランスフォーマーはピクセルを自己回帰的に予測するために訓練されてきた[6, 7, 35]。 また、自己回帰モデル[11, 44]とマスクされた生成モデル[4, 14]として離散コードブック[56]で学習され、前者は20Bパラメータまでの優れたスケーリング挙動を示した[59]。最後に、トランスフォーマーは非空間データを合成するためにDDPMで研究されてきた。例えば、DALL-E 2のCLIP画像埋め込みを生成するためである[38, 43]。本論文では、画像の拡散モデルのバックボーンとして使用された場合のトランスフォーマーのスケーリング特性について研究する。
Denoising diffusion probabilistic models (DDPMs)
拡散モデル[19, 51]とスコアベース生成モデル[22, 53]は画像の生成モデルとして特に成功し、多くの場合、それまで最先端であったGAN[12]を凌駕している。 過去2年間のDDPMの改良は、サンプリング技術の改良[19, 25, 52]、特に分類器放棄誘導[21]、画素ではなくノイズを予測する拡散モデルの再構成[19]、アップサンプラーと並行して低解像度ベース拡散モデルを学習するカスケードDDPMパイプラインの使用により大きく推進されている[9, 20]。上記のすべての拡散モデルにおいて、畳み込みU-Net [46]がバックボーンアーキテクチャのデファクトスタンダードとなっている。
Architecture complexity
画像生成に関する文献では、アーキテクチャの複雑さを評価する際、パラメータカウントを使用することが一般的である。 一般に、パラメータカウントは、例えば、性能に大きな影響を与える画像解像度を考慮していないため、画像モデルの複雑さの代用としては不十分な場合がある[41, 42]。その代わり、本論文では、モデルの複雑さの分析の多くをGflopsの理論の視点で行っている。このことは、Gflopsが複雑さの測定に広く使用されているアーキテク チャ設計の文献と一致している。実際のところ、最良の複雑さの指標(が何であるか)は、それが特定のアプリケー ションシナリオに頻繁に依存するため、まだ議論が続いている。NicholとDhariwalの拡散モデルの改善に関する代表的な研究[9, 33]は、我々と最も関連が深く、彼らはそこで、U-NetアーキテクチャクラスのスケーラビリティとGflop特性を分析した。この論文では、トランスフォーマークラスに焦点を当てる。
Diffusion Transformers
3.1. Preliminaries
Diffusion formulation
我々のアーキテクチャを紹介する前に、拡散モデル(DDPMs)[19, 51]を理解するために必要ないくつかの基本的な概念を簡単に復習しておく。ガウスシアン拡散モデルは、定数は超パラメーターとして、実データ
に徐々にノイズを加える順方向ノイズプロセスを仮定する。再パラメータ化のトリックを適用すると、サンプル
が得られる。
拡散モデルは、順プロセスでの劣化を反転させる逆プロセス
を学習するために訓練され、ニューラルネットワークは
の統計量を予測するために使用される。 逆方向モデルは
の対数尤度の変分下界[27]で学習され、
を減少させ、学習に無関係な付加項が除かれる。
と
はともにガウス分布であるため、
は2つの分布の平均と共分散で評価することが可能である。
をノイズ予測ネットワーク
として再パラメータ化することにより、予測ノイズ
とサンプリングしたground-truthガウスノイズ
との単純な平均二乗誤差
を用いてモデルを学習することが可能である。しかし、逆プロセスでの共分散
をフルに学習して拡散モデルを学習するためには、
項を最適化する必要がある。そこで、NicholとDhariwal のアプローチ[33]に従い、
を
で学習し、
を
フルに使い学習する。一度
が学習されると、
を初期化し、再パラメータ化のトリックにより
をサンプリングすることにより、新たな画像を得ることができる。
Classifier-free guidance
条件付き拡散モデルは、クラスラベルのような追加的な情報を入力として受け取ることができる。この場合、逆プロセスは
となり、
と
は
に条件づけられる。 この設定において、分類器放棄誘導は、
が高くなるような
を見つけるようにサンプリング手順を促すために使用することができる[21]。ベイズ則では、
であるので、
となる。このように拡散モデルの出力をスコア関数として解釈することで、DDPMのサンプリング手順を、
が高いサンプル
に誘導することができる。このことは次のような式で表せる。
、ここで
は誘導規模を表す(
は標準サンプリングであることに注意する。)。
を用いた拡散モデルの評価は、学習中にランダムに
を削除し、学習した「ヌル」埋め込み
に置き換えることによって行われる。 分類器放棄誘導は、一般的なサンプリング技術よりも大幅に改善されたサンプルをもたらすことが広く知られており[21, 32, 43]、この傾向は我々のDiTモデルでも同様である。
Latent diffusion models
高解像度の画素空間で拡散モデルを正しく学習させることは、計算量的に困難である。潜在拡散モデル(LDM)[45]は、2段階のアプローチでこの問題に取り組む。(1)学習したエンコーダで画像をより小さな空間表現に圧縮するオートエンコーダを学習する、(2)画像
の拡散モデルの代わりに、表現
の拡散モデルを学習する。(
は固定されているとする。)図2に示すように、LDMはADMのようなピクセル空間拡散モデルの数分の一のGflopsで良好な性能を達成することができる。新しい画像は、拡散モデルから表現
をサンプリングし、学習したデコーダ
を用いて画像にデコードすることで生成できる。
図2に示すように、LDMはADMのようなピクセル空間拡散モデルの数分の1のGflopsで良好な性能を達成することができる。 本論文では、DiTsを潜在空間に適用しているが、そのままピクセル空間に適用することも可能である。このため、我々の画像生成パイプラインは、既製の畳み込みVAEとトランスフォーマーベースのDDPMを用いたハイブリッド型のアプローチとなっている。

3.2. Diffusion Transformer Design Space
我々は、拡散モデルのための新しいアーキテクチャである拡散トランスフォーマー(DiTs)を紹介する。我々は、スケーリング特性を保持するために、標準的な変換器アーキテクチャにできるだけ忠実であることを目指している。我々は画像(特に画像の空間表現)のDDPMの学習をすることに焦点を当てているため、DiTはパッチのシーケンスに対して動作するVision Transformer(ViT)アーキテクチャをベースにしている[10]。DiTは、ViTのベストプラクティスの多くを継承している。 図3は、DiTのアーキテクチャの概要を示している。 本節では、DiTの順方向過程と、DiTクラスの設計空間の構成要素を説明する。

が与えられたとき、形状
の空間表現(VAEからのノイズ潜在変数)は、隠れ次元
で長さ[tex: T= (\frac{I}{p})2]のシーケンスに「パッチ」化される。パッチサイズ
が小さいとシーケンス長が長くなり、Gflopsが増加する。
Patchify
DiTの入力は空間表現(256×256×3画像の場合、
は32×32×4の形状を持つ)である。DiTの最初の層は "patchify "であり、空間入力を、各パッチを線形に埋め込むことによって、各次元
の
トークンのシーケンスに変換する。 パッチ化の後、標準的なViT周波数ベースの位置埋め込み(サイン・コサイン版)をすべての入力トークンに適用する。パッチ化で生成されるトークンの数は、パッチサイズのハイパーパラメータ
によって決定される。 図4に示すように、
を半分にすると
は4倍になり、したがってトランスフォーマーの総Gflopsは少なくとも4倍になる。Gflopsに大きな影響を与えるが、
を変更しても下流のパラメータ数には意味がないことに注意してください。DiTの設計空間に
を追加した。
DiT block design
パッチファイに続いて、入力トークンは一連のトランスフォーマーブロックによって処理される。 ノイズを含む画像入力に加え、拡散モデルはノイズの時間ステップ、クラスラベル、自然言語などの追加の条件情報を処理することがある。我々は、条件付き入力を異なる方法で処理する4種類のトランスフォーマーブロックを検討した。 これらの設計は、標準的なViTブロックの設計に、小さいが重要な変更を導入している。 すべてのブロックの設計を図3に示す。
文脈内条件付け:入力シーケンスに2つの追加トークンとして
と
の埋め込みベクトルを単純に追加し、画像トークンと同様に扱う。これはViTsのclsトークンと同様であり、標準的なViTブロックをそのまま使用することができる。最終ブロックの後、シーケンスから条件トークンを除去する。このアプローチでは、モデルへの新たなGflopsの導入はごくわずかである。
クロスアテンションブロック:画像トークン列とは別に、
適応的レイヤー正規化(
)ブロック:GAN [2, 26] や U-Netバックボーンによる拡散モデル [9] において、適応的正規化層 [37] が広く用いられていることを受けて、我々は、トランスフォーマーブロックの標準的なレイヤー正規化層を適応的レイヤー正規化(adaLN)に置き換えることを検討する。次元ごとのスケールとシフトのパラメータ
と
を直接学習するのではなく、埋め込みベクトル
-addLN-Zeroブロック:ResNetsに関する先行研究では、各残差ブロックを恒等関数として初期化することが有効であることが分かっている。例えば、Goyalらは、各ブロックの最終バッチノルムスケールファクターをゼロに初期化することで、強化学習設定における大規模学習が加速されることを発見した[13]。拡散U-Netモデルも同様の初期化戦略を用いており、各ブロックの最後の畳み込み層を、任意の残留接続の前にゼロ初期化する。我々は、同じことを行うAdaLN DiTブロックの改良を探求している。また、
と
の回帰に加えて、DiTブロック内の任意の残留接続の直前に適用される次元単位のスケーリングパラメータ
も回帰させる。すべての
に対してゼロベクトルを出力するようにMLPを初期化し,これにより,完全なDiTブロックを恒等関数として初期化する。バニラAdaLNブロックと同様に、AdaLN-Zeroはモデルへの無視できるほどのGflopsを増やす。
我々はDiTの設計空間には、文脈内条件付け、クロスアテンション、適応的レイヤー正規化、adaLN-Zeroブロックが含めた。

Model size
我々は、それぞれ潜在次元で動作する
個のDiTブロックのシーケンスを適用する。ViTに倣い、
、
とアテンションヘッドを共同でスケールする標準的なトランスフォーマー構成を用いる[10, 60]。具体的には、4つの構成、DiT-S、DiT-B、DiT-L、DiT-XLである。0.3から118.6Gflopsの幅広いモデルサイズとフロップ数で構成されており、スケーリング性能を測定することができる。表1には、構成の詳細を示す。
我々は、DiTの設計空間にB、S、L、XLの構成を追加した。
Transformer decoder
最後のDiTブロックの後、一連の画像トークンを出力ノイズの予測と出力対角共分散の予測にデコードする必要がある。これらの出力は、いずれも元の空間入力と同じ形状をしている。そのために、標準的な線形デコーダを使用している。最終層の正規化(adaLNの場合は適応的)を適用し、各トークンをのテンソル(ここで
はDiTへの空間入力のチャンネル数)に線形復号する。最後に、デコードされたトークンを元の空間レイアウトに並べ替えて、予測されるノイズと共分散を得る。
我々が探求するDiTの完全な設計空間は、パッチサイズ、トランスフォーマーブロックアーキテクチャとモデルサイズである。
4. Experimental Setup
DiTのデザイン空間を探索し、モデルクラスのスケーリング特性を研究する。モデルの名前は、その構成と潜在パッチの大きさに従って付けられている。 例えば、DiT-XL/2はXLarge構成でである。
Training
本論文では、高い競争力を持つ生成モデリングベンチマークであるImageNetデータセット[28]を用いて、256×256および512×512画像解像度でクラス条件付き潜在DiTモデルの学習を行った。最終線形層はゼロで初期化し、それ以外はViTの標準的な重み初期化手法を使用する。全てのモデルはAdamW [27, 30]で学習する。
学習率はで、重みの除去は行わず、バッチサイズは256である。データ拡張に用いたのは水平フリップのみである。ViTsの先行研究[54, 58]とは異なり、DiTsを高性能に学習させるために、学習率のウォームアップや正則化は必要ないと考えた。これらの手法を用いない場合でも、学習は全てのモデル構成で非常に安定しており、トランスフォーマーを学習する際によく見られる損失スパイクも観察されなかった。生成モデリングの文献によく見られるように、我々はDiTの重みの指数移動平均(EMA)を0.9999の減衰率で維持しながら学習を進めた。すべての結果はEMAモデルを用いている。学習用ハイパーパラメータはADMからほぼ完全に保持されている。DiTモデルのサイズとパッチサイズに関わらず同一の学習ハイパーパラメータを使用した。学習率、減衰/ウォームアップスケジュール、Adamβ1/β2、重み減衰は調整しなかった。
Diffusion
Stable Diffusion [45]の既製の学習済みVariational Autoencoder (VAE)モデル[27]を使用した。VAEエンコーダは、形状256×256×3のRGB画像を8倍ダウンサンプルし、
は形状32×32×4とする。本節の全ての実験において、我々の拡散モデルはこの
空間で動作する。 拡散モデルから新しい潜在変数をサンプリングした後、VAEデコーダ
を用いてそれをピクセルにデコードする。具体的には、
から
の範囲の
の線形分散スケジュール、ADMの共分散のパラメータ化
、入力タイムステップとラベルを埋め込む方法を用いた。
Evaluation metrics
スケーリング性能は、画像の生成モデルを評価するための標準的な指標であるFID(Frechet Inception Distance)[18]を用いて測定する。 先行研究との比較では、慣例に従い、250 DDPMのサンプリングステップを用いたFID-50Kを報告する。FIDは小さな実装のディテールに敏感であることが知られている[34]が、正確な比較を確実にするために、この論文で報告されたすべての値は、サンプルをエクスポートし、ADMのTensorFlow評価[9]を使用して得られたものである。 このセクションで報告されたFID数は、特に明記された場合を除き、分類器放棄誘導を使用していない。また、二次評価指標としてInception Score [48]、sFID [31]、 Precision/Recall [29]を報告している。
Compute
すべてのモデルをJAX[1]で実装し、TPU-v3ポッドを用いて学習させた。最も計算量の多いDiT-XL/2は、TPU v3-256ポッドを用いて、グローバルバッチサイズ256で約5.7回/秒の速度で学習する。

5. Experiments
DiT block design
Gflop DiT-XL/2モデルのうち、最高レベルの4つのモデルを、それぞれ異なるブロックデザインー文脈内条件付け(119.4 Gflops)、クロスアテンション(137.6 Gflops)、適応的レイヤー正規化(AdaLN、118.6 Gflops)、AdaLN-zero(118.6 Gflops)で学習させた。トレーニングの過程でFIDを測定しており、図5はその結果である。 adaLN-Zeroブロックはクロスアテンションや文脈内条件付けよりもFIDが低く、計算効率も最も良い。400Kのイタレーションにおいて、adaLN-Zeroモデルで達成されたFIDは文脈内条件付けのほぼ半分であり、条件付けメカニズムがモデルの品質に決定的な影響を与えることが証明された。初期化も重要であり、各DiTブロックを恒等関数として初期化するadaLN-Zeroは、バニラadaLNを大幅に上回る性能を示した。本稿では、これ以降すべてのモデルにadaLN-Zero DiTブロックを使用する。
Scaling model size and patch size
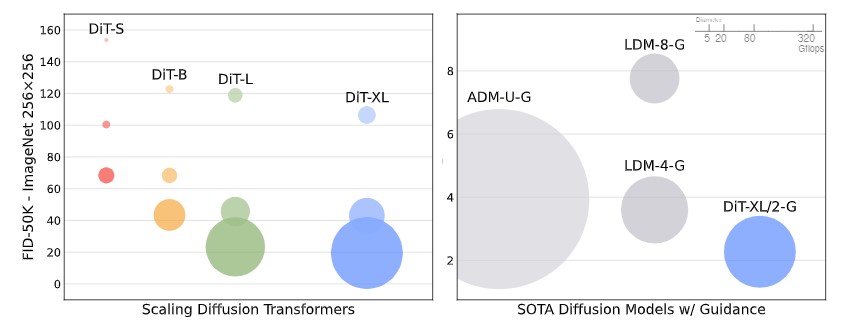
モデル構成(S, B, L, XL)とパッチサイズ(8, 4, 2)にわたって、12のDiTモデルを学習させた。DiT-LとDiT-XLは、他の構成に比べて相対的なGflopsの点で互いにかなり接近していることに注意してください。 図2(左)は、40万回の学習イタレーションにおける各モデルのGflopsとFIDの概要を示している。いずれの場合も、モデルサイズを大きくし、パッチサイズを小さくすることで、拡散モデルがかなり改善されることがわかった。
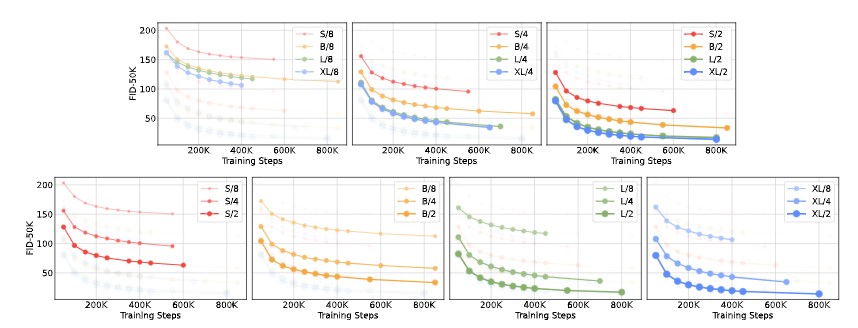
図6(上)は、モデルサイズを大きくし、パッチサイズを一定にした場合のFIDの変化を示している。4つの構成すべてにおいて、トランスフォーマーを深く、広くすることによって、学習のすべての段階でFIDが大幅に改善されることがわかる。同様に、図6(下)は、パッチサイズを小さくし、モデルサイズを一定にしたときのFIDを示したものである。このように、DiTのパラメータをほぼ固定したまま、処理するトークン数をスケールアップさせるだけで、学習全体を通してFIDが大幅に改善されることがわかる。
DiT Gflops are critical to improving performance
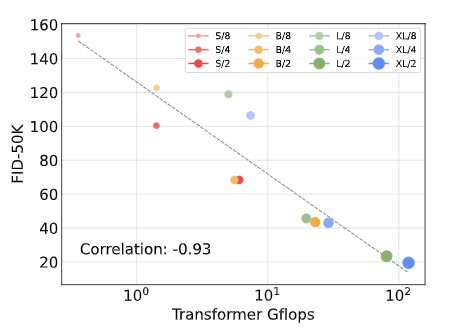
図6の結果は、DiTモデルの品質を決定する上で、パラメータ数はほとんど重要でないことを示唆している。モデルサイズを一定に保ち、パッチサイズを小さくすると、トランスフォーマーの全パラメータは実質的に変化せず、Gflopsのみが増加する。これらの結果は、モデルGflopの拡張が性能向上の鍵であることを示している。さらに調査するために、図8に400K学習ステップのFID-50KをモデルGflopsに対してプロットした。その結果、サイズやトークンの異なるDiTモデルでも、総Gflopsが同程度であれば、最終的に同じようなFID値が得られることが分かった(例えば、DiT-S/2とDiT-B/4)。実際、モデルのGflopsとFID-50Kの間には強い負の相関が見られ、モデルの追加計算がDiTモデルの改良に不可欠な要素であることが示唆されている。図12 (付録) では、この傾向が Inception Score などの他の指標にも見られることが分かる。

Larger DiT models are more compute-efficient
図9では、すべてのDiTモデルについて、FIDを総トレーニング量に対する関数としてプロットしている。学習量は、モデルGflop・バッチサイズ・学習ステップ・3とし、係数3は、バックパスがフォワードパスの2倍の計算量になることをおおよそ示している。その結果、小さなDiTモデルは、たとえ長く学習しても、より少ないステップで学習した大きなDiTモデルに比べて、最終的に計算効率が悪くなることが分かった。同様に、パッチサイズ以外は同一であるモデルは、学習Gflopsを制御した場合でも、性能のプロファイルが異なることがわかる。 例えば、XL/4は約 GflopsでXL/2より性能が向上する。

Visualizing scaling
図7は、スケーリングがサンプルの品質に与える影響を可視化したものである。400K学習ステップにおいて、12個のDiTモデルのそれぞれから、同じ(identical)開始ノイズ、サンプリングノイズ、クラスラベルを用いて画像をサンプリングする。これにより、スケーリングがDiTサンプルの品質にどのように影響するかを視覚的に解釈することができる。実際、モデルサイズとトークン数の両方を拡張することで、視覚的品質が顕著に向上する。

5.1. State-of-the-Art Diffusion Models
256×256 ImageNet.
スケーリング解析に続いて、最も高いGflopを持つモデルDiT-XL/2を7Mステップ学習させる。 このモデルのサンプルを図1に示し、SOTAのクラス条件付き生成モデルとの比較を行う。 また、表2に結果を示す。 DiT-XL/2は、分類器放棄誘導を用いた場合、すべての事前拡散モデルを上回り、LDMが達成したFID-50Kの最高値3.60を2.27に減少させることができた。図2(右)は、DiT-XL/2(118.6 Gflops)がLDM-4(103.6 Gflops)などの潜在空間U-Netモデルに対して計算効率が高く、ADM(1120 Gflops)やADM-U(742 Gflops)などのピクセルスペースU-Netモデルよりも実質的に効率が良いことを示している。本手法は、先行するSOTAであったStyleGAN-XL[50]を含むすべての生成モデルの中で最も低いFIDを達成した。最後に、DiT-XL/2はLDM-4やLDM-8と比較して、テストしたすべての分類器放棄誘導のスケールでより高いリコール値を達成することが確認された。2.35Mステップ(ADMと同様)のみで学習した場合でも、XL/2は2.55のFIDでいまだ全ての先行拡散モデルを凌駕している。

512×512 ImageNet
512×512解像度のImageNetに対して、256×256モデルと同じハイパーパラメータで3Mイタレーションの新しいDiT-XL/2モデルを学習させる。 パッチサイズ2の場合、64×64×4入力の潜在能力をパッチ処理した後、このXL/2モデルは合計1024トークンを処理する(524.6 Gflops)。表3は、SOTA手法との比較である。XL/2は、この解像度においても、ADMが達成した従来の最高値3.85のFIDを3.04に改善し、すべての先行する拡散モデルを再び上回った。トークンの数が増えても、XL/2は計算効率を維持したままである。 例えば、ADMでは1983 Gflops、ADM-Uでは2813 Gflops、XL/2では524.6 Gflopsを使用している。 高解像度XL/2モデルのサンプルを図1および付録に示す。

5.2. Model Compute vs. Sampling Compute
多くの生成モデルと異なり、拡散モデルは、画像を生成する際のサンプリングステップ数を増やすことで、学習後に追加の計算を行うことができる点が特徴である。このセクションでは、モデルGflopsのサンプル品質の重要性を考慮し、より小さなモデル計算DiTが、より多くのサンプリング計算を使用することによって、より大きなものを上回ることができるかどうかを研究する。 我々は、400Kの学習ステップの後、12個のDiTモデルすべてについて、1画像あたり[16, 32, 64, 128, 256, 1000]のサンプリングステップを用いて、FIDを計算した主な結果は図10に示す通りである。1000サンプリングステップのDiT-L/2と128サンプリングステップのDiT-XL/2を比較する。この場合、L/2は各画像のサンプリングに80.7 Tflopsを使用し、XL/2は各画像のサンプリングに5倍少ない15.2 Tflopsの計算を使用する。それにもかかわらず、FID-10KはXL/2の方が優れている(23.7 vs 25.9)。一般に、サンプリング計算ではモデル計算の不足を補うことはできない。
6. Conclusion
本論文では、従来のU-Netモデルよりも優れた性能を持ち、トランスフォーマーモデルクラスの優れたスケーリング特性を継承した、シンプルなトランスフォーマーベースの拡散モデル用バックボーンである、Diffusion Transformers (DiTs) を紹介した。 本論文で得られた有望なスケーリング結果を考慮すると、今後、より大きなモデルやトークン数にDiTsをスケーリングする研究を継続する必要がある。また、DiTはDALL-E 2やStable Diffusionのようなtext-to-imageモデルのためのドロップインバックボーンとして検討される可能性がある。
Acknowledgements.
Kaiming He、Ronghang Hu、Alexander Berg、Shoubhik Debnath、Tim Brooks、Ilija RadosavovicそしてTete Xiaoに有益な議論を頂いたことに感謝する。William Peeblesは、NSF GRFPの支援を受けている。
Apendix (The figures in the appendix are only part of the original contents.)
*付録の図は原文の一部のみを掲載しています。



A. Additional Implementation Details
表4には、256×256および512×512の両モデルを含む、すべてのDiTモデルに関する情報を記載している。Gflop数、パラメータ、トレーニングの詳細、FIDなどを含む。 また、表6にはADMとLDMのDDPM U-NetモデルのGflopカウントも含まれている。
DiT model details
入力タイムステップを埋め込むために、我々は256次元周波数埋め込み[9]と、トランスフォーマーの隠れサイズとSiLU活性化関数に等しい次元を持つ2層MLPを使用している。各adaLN層はタイムステップとクラス埋め込みの和をSiLU非線形と線形層に送り、出力ニューロンはトランスフォーマーの隠れサイズに等しい4×(adaLN)か6×(adaLN-Zero)のいずれかに等しい。コアトランスフォーマーにはGELU非線形(tanhで近似)を用いる[16]。

B. VAE Decoder Ablations
この実験では、既製の事前学習済みVAEを使用した。VAEモデル(ft-MSEとft-EMA)は、オリジナルのLDM「f8」モデルをファインチューンしたものである(デコーダの重みのみをファインチューン)。第5節のスケーリング解析では、ft-MSE デコーダを使用して指標を監視し、表2と表3に示した最終指標では、ft-EMA デコーダを使用した。このセクションでは、LDMで使用されるオリジナルのVAEデコーダと、Stable Diffusionで使用される2つのファインチューンされたデコーダの3つの異なる選択肢について説明する。エンコーダはモデル間で同一であるため、拡散モデルを再学習することなくデコーダを交換することができる。表5に結果を示す。LDMデコーダを用いた場合、XL/2はすべての先行拡散モデルを凌駕している。
C. Model Samples
DiT-XL/2の3Mステップと7Mステップで学習した512×512と256×256解像度のモデルのサンプルを示す。図1および図11は、両モデルから選択されたサンプルである。図13から図32は、分類器放棄誘導スケールと入力クラスラベル(250 DDPMサンプリングステップとft-EMA VAEデコーダで生成)の範囲における2つのモデルのサンプルを切断したものである。その結果、スケールを大きくすると、視覚的な忠実度が増し、サンプルの多様性が低下することがわかった。

References
[1] JamesBradbury,RoyFrostig,PeterHawkins,Matthew James Johnson, Chris Leary, Dougal Maclau-rin, George Necula, Adam Paszke, Jake VanderPlas, SkyeWanderman-Milne, and Qiao Zhang.JAX: composabletransformations of Python+NumPy programs, 2018. 6
[2] Andrew Brock, Jeff Donahue, and Karen Simonyan. Largescale GAN training for high fidelity natural image synthesis.InICLR, 2019. 5, 9
[3] Tom B Brown, Benjamin Mann, Nick Ryder, Melanie Sub-biah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan,Pranav Shyam, Girish Sastry, Amanda Askell, et al. Lan-guage models are few-shot learners. InNeurIPS, 2020. 1
[4] Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William TFreeman. Maskgit: Masked generative image transformer. InCVPR, pages 11315–11325, 2022. 2
[5] Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee,Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srini-vas, and Igor Mordatch. Decision transformer: Reinforce-ment learning via sequence modeling. InNeurIPS, 2021. 2
[6] Mark Chen, Alec Radford, Rewon Child, Jeffrey Wu, Hee-woo Jun, David Luan, and Ilya Sutskever. Generative pre-training from pixels. InICML, 2020. 1, 2
[7] Rewon Child, Scott Gray, Alec Radford, and Ilya Sutskever.Generating long sequences with sparse transformers.arXivpreprint arXiv:1904.10509, 2019. 2
[8] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and KristinaToutanova. Bert: Pre-training of deep bidirectional trans-formers for language understanding. InNAACL-HCT, 2019.1
[9] Prafulla Dhariwal and Alexander Nichol. Diffusion modelsbeat gans on image synthesis. InNeurIPS, 2021. 1, 2, 3, 5,6, 9, 12
[10] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov,Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner,Mostafa Dehghani, Matthias Minderer, Georg Heigold, Syl-vain Gelly, et al. An image is worth 16x16 words: Trans-formers for image recognition at scale. InICLR, 2020. 1, 2,4, 5
[11] Patrick Esser, Robin Rombach, and Bj ̈orn Ommer. Tamingtransformers for high-resolution image synthesis, 2020. 2
[12] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, BingXu, David Warde-Farley, Sherjil Ozair, Aaron Courville, andYoshua Bengio. Generative adversarial nets. InNIPS, 2014.3
[13] Priya Goyal, Piotr Doll ́ar, Ross Girshick, Pieter Noord-huis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch,Yangqing Jia, and Kaiming He. Accurate, large minibatchsgd: Training imagenet in 1 hour.arXiv:1706.02677, 2017.5
[14] Shuyang Gu, Dong Chen, Jianmin Bao, Fang Wen, BoZhang, Dongdong Chen, Lu Yuan, and Baining Guo. Vec-tor quantized diffusion model for text-to-image synthesis. InCVPR, pages 10696–10706, 2022. 2
[15] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.Deep residual learning for image recognition. InCVPR,2016. 2
[16] Dan Hendrycks and Kevin Gimpel. Gaussian error linearunits (gelus).arXiv preprint arXiv:1606.08415, 2016. 12
[17] Tom Henighan, Jared Kaplan, Mor Katz, Mark Chen,Christopher Hesse, Jacob Jackson, Heewoo Jun, Tom BBrown, Prafulla Dhariwal, Scott Gray, et al. Scaling lawsfor autoregressive generative modeling.arXiv preprintarXiv:2010.14701, 2020. 2
[18] Martin Heusel, Hubert Ramsauer, Thomas Unterthiner,Bernhard Nessler, and Sepp Hochreiter. Gans trained by atwo time-scale update rule converge to a local nash equilib-rium. 2017. 6
[19] Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffu-sion probabilistic models. InNeurIPS, 2020. 2, 3
[20] Jonathan Ho, Chitwan Saharia, William Chan, David JFleet, Mohammad Norouzi, and Tim Salimans.Cas-caded diffusion models for high fidelity image generation.arXiv:2106.15282, 2021. 3, 9
[21] Jonathan Ho and Tim Salimans. Classifier-free diffusionguidance. InNeurIPS 2021 Workshop on Deep GenerativeModels and Downstream Applications, 2021. 3, 4
[22] Aapo Hyv ̈arinen and Peter Dayan.Estimation of non-normalized statistical models by score matching.Journalof Machine Learning Research, 6(4), 2005. 3
[23] Michael Janner, Qiyang Li, and Sergey Levine. Offline rein-forcement learning as one big sequence modeling problem.InNeurIPS, 2021. 2
[24] Jared Kaplan, Sam McCandlish, Tom Henighan, Tom BBrown, Benjamin Chess, Rewon Child, Scott Gray, AlecRadford, Jeffrey Wu, and Dario Amodei. Scaling laws forneural language models.arXiv:2001.08361, 2020. 2
[25] Tero Karras, Miika Aittala, Timo Aila, and Samuli Laine.Elucidating the design space of diffusion-based generativemodels. InProc. NeurIPS, 2022. 3
[26] Tero Karras, Samuli Laine, and Timo Aila. A style-basedgenerator architecture for generative adversarial networks. InCVPR, 2019. 5
[27] Diederik Kingma and Jimmy Ba. Adam: A method forstochastic optimization. InICLR, 2015. 3, 5, 6
[28] Alex Krizhevsky, Ilya Sutskever, and Geoffrey E Hinton.Imagenet classification with deep convolutional neural net-works. InNeurIPS, 2012. 5
[29] Tuomas Kynk ̈a ̈anniemi, Tero Karras, Samuli Laine, JaakkoLehtinen, and Timo Aila. Improved precision and recall met-ric for assessing generative models. InNeurIPS, 2019. 6
[30] Ilya Loshchilov and Frank Hutter. Decoupled weight decayregularization.arXiv:1711.05101, 2017. 5
[31] Charlie Nash, Jacob Menick, Sander Dieleman, and Peter WBattaglia. Generating images with sparse representations.arXiv preprint arXiv:2103.03841, 2021. 6
[32] Alex Nichol, Prafulla Dhariwal, Aditya Ramesh, PranavShyam, Pamela Mishkin, Bob McGrew, Ilya Sutskever,and Mark Chen.Glide: Towards photorealistic imagegeneration and editing with text-guided diffusion models.arXiv:2112.10741, 2021. 3, 4
[33] Alexander Quinn Nichol and Prafulla Dhariwal. Improveddenoising diffusion probabilistic models. InICML, 2021. 3
[34] Gaurav Parmar, Richard Zhang, and Jun-Yan Zhu.Onaliased resizing and surprising subtleties in gan evaluation.InCVPR, 2022. 6
[35] Niki Parmar, Ashish Vaswani, Jakob Uszkoreit, LukaszKaiser, Noam Shazeer, Alexander Ku, and Dustin Tran. Im-age transformer. InInternational conference on machinelearning, pages 4055–4064. PMLR, 2018. 2
[36] William Peebles, Ilija Radosavovic, Tim Brooks, AlexeiEfros, and Jitendra Malik. Learning to learn with genera-tive models of neural network checkpoints.arXiv preprintarXiv:2209.12892, 2022. 2
[37] Ethan Perez, Florian Strub, Harm De Vries, Vincent Du-moulin, and Aaron Courville. Film: Visual reasoning with ageneral conditioning layer. InAAAI, 2018. 2, 5
[38] Alec Radford, Jong Wook Kim, Chris Hallacy, AdityaRamesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry,Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learn-ing transferable visual models from natural language super-vision. InICML, 2021. 2
[39] Alec Radford, Karthik Narasimhan, Tim Salimans, and IlyaSutskever. Improving language understanding by generativepre-training. 2018. 1
[40] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, DarioAmodei, Ilya Sutskever, et al. Language models are unsu-pervised multitask learners. 2019. 1
[41] Ilija Radosavovic, Justin Johnson, Saining Xie, Wan-Yen Lo,and Piotr Doll ́ar. On network design spaces for visual recog-nition. InICCV, 2019. 3
[42] Ilija Radosavovic, Raj Prateek Kosaraju, Ross Girshick,Kaiming He, and Piotr Doll ́ar. Designing network designspaces. InCVPR, 2020. 3
[43] Aditya Ramesh, Prafulla Dhariwal, Alex Nichol, Casey Chu,and Mark Chen. Hierarchical text-conditional image gener-ation with clip latents.arXiv:2204.06125, 2022. 1, 2, 3, 4
[44] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray,Chelsea Voss, Alec Radford, Mark Chen, and Ilya Sutskever.Zero-shot text-to-image generation. InICML, 2021. 1, 2
[45] Robin Rombach, Andreas Blattmann, Dominik Lorenz,Patrick Esser, and Bj ̈orn Ommer. High-resolution image syn-thesis with latent diffusion models. InCVPR, 2022. 2, 3, 4,6, 9
[46] Olaf Ronneberger, Philipp Fischer, and Thomas Brox. U-net: Convolutional networks for biomedical image segmen-tation. InInternational Conference on Medical image com-puting and computer-assisted intervention, pages 234–241.Springer, 2015. 2, 3
[47] Chitwan Saharia, William Chan, Saurabh Saxena, LalaLi, Jay Whang, Emily Denton, Seyed Kamyar SeyedGhasemipour, Burcu Karagol Ayan, S. Sara Mahdavi,Rapha Gontijo Lopes, Tim Salimans, Jonathan Ho, David JFleet, and Mohammad Norouzi.Photorealistic text-to-image diffusion models with deep language understanding.arXiv:2205.11487, 2022. 3
[48] Tim Salimans, Ian Goodfellow, Wojciech Zaremba, VickiCheung, Alec Radford, Xi Chen, and Xi Chen. Improvedtechniques for training GANs. InNeurIPS, 2016. 6
[49] Tim Salimans, Andrej Karpathy, Xi Chen, and Diederik PKingma. PixelCNN++: Improving the pixelcnn with dis-cretized logistic mixture likelihood and other modifications.arXiv preprint arXiv:1701.05517, 2017. 2
[50] Axel Sauer, Katja Schwarz, and Andreas Geiger. Stylegan-xl: Scaling stylegan to large diverse datasets. InSIGGRAPH,2022. 9
[51] Jascha Sohl-Dickstein, Eric Weiss, Niru Maheswaranathan,and Surya Ganguli.Deep unsupervised learning usingnonequilibrium thermodynamics. InICML, 2015. 3
[52] Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois-ing diffusion implicit models.arXiv:2010.02502, 2020. 3
[53] Yang Song and Stefano Ermon. Generative modeling by es-timating gradients of the data distribution. InNeurIPS, 2019.3
[54] Andreas Steiner, Alexander Kolesnikov, Xiaohua Zhai, RossWightman, Jakob Uszkoreit, and Lucas Beyer. How to trainyour ViT? data, augmentation, and regularization in visiontransformers.TMLR, 2022. 6
[55] Aaron Van den Oord, Nal Kalchbrenner, Lasse Espeholt,Oriol Vinyals, Alex Graves, et al. Conditional image genera-tion with pixelcnn decoders.Advances in neural informationprocessing systems, 29, 2016. 2
[56] Aaron Van Den Oord, Oriol Vinyals, et al. Neural discreterepresentation learning.Advances in neural information pro-cessing systems, 30, 2017. 2
[57] Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszko-reit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and IlliaPolosukhin. Attention is all you need. InNeurIPS, 2017. 1,2, 5
[58] Tete Xiao, Piotr Dollar, Mannat Singh, Eric Mintun, TrevorDarrell, and Ross Girshick. Early convolutions help trans-formers see better. InNeurIPS, 2021. 6
[59] Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong,Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku,Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autore-gressive models for content-rich text-to-image generation.arXiv:2206.10789, 2022. 2
[60] Xiaohua Zhai, Alexander Kolesnikov, Neil Houlsby, and Lu-cas Beyer. Scaling vision transformers. InCVPR, 2022. 2,5