今日の論文2023/05/18,19:Diving Deep into Modes of Fact Hallucinations in Dialogue Systems
Diving Deep into Modes of Fact Hallucinations in Dialogue Systems
©2022 Association for Computational Linguistics
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容に基づき筆者が要約または翻訳したものです。以下の図は、そこから引用しています。
This article is my summary or translation based on the content of the original publication. The following figures are taken from it.
要点まとめ
知識グラフ(KG)ベースの会話は、多くの場合、事前に訓練された大規模なモデルを使用し、通常、事実の幻覚に悩まされている。知識ソースや会話履歴にないエンティティが応答に導入され、会話の流れが阻害されることがよくある。既存の研究では、学習手順を修正したり、多段階の洗練方法を用いることで、この問題を克服しようとしている。しかし、応答生成時に誤変換を抑制するきめ細かなシグナルを提供する、エンティティレベルの幻覚検出システムの構築は、ほとんど行われていない。この問題を解決するための第一歩として、我々は、人間のフィードバック分析を通じて、KGに基づいたチャットボットの様々な幻覚のモードを特定するために深く探索する。次に、FADE(FActual Dialogue Hallucination DEtection Dataset)と名付けられた合成データセットを作成するために、一連の摂動戦略を提案する。最後に、包括的なデータ分析を行い、幻覚検出のための複数のベースラインモデルを作成し、人間が検証したデータや既に確立されたベンチマークと比較する。
1. 序論
知識ベースの会話モデルは、多くの場合、事前に訓練された大規模なモデルを使用する(Radford et al., 2019;Brown et al., 2020)。これらのモデルは、提供された知識に従わない応答を生成することで有名である。この現象は、幻覚(Hallucination)(Dziri et al., 2022b; Rashkin et al, 2021b)と呼ばれている。補足的な知識エッジに忠実であることは、これらの知識基盤型チャットボットの主要な設計要因の一つである。もし、ある応答が与えられた知識に忠実でない場合、その応答は非情報的となり、会話の流れを危うくする危険性がある。このような大規模な言語モデル(LM)は、強力な言語学的能力を保持しているにもかかわらず、会話中に事実を理解し、提示することが不十分である。LMは、データの分布特性を模倣するように訓練され、テスト時に幻覚的な特性を強める。
一方、多くの先行研究(Wisemanet al., 2017; Parikh et al., 2020; Tuan et al., 2019)は、忠実性を確保するために外部データでこれらのモデルを訓練すると、参照が追加の事実情報を含む、ソースと参照の発散問題が発生する可能性があることを示唆している。この問題を総合的に解決するために、Dziriらは、従来の対話生成に別の洗練段階(refinement stage)を追加することによって、2段階のgenerate-then-refineアプローチを提案し、対話システムがKGに問い合わせることによって潜在的な幻覚を修正することを可能にした。また、本研究では、2つの摂動戦略を用いて構築した合成データセットで訓練したトークンレベルの幻覚分類器を採用している。この方法には明確な利点があるが、本研究で提案された幻覚の摂動戦略は、事実生成モデルの曖昧な帰属の一部を捕らえることができないかもしれない。 図1に示すように、ニューラルモデルは、k-hop KGに存在し、期待されるものと欺瞞的に類似している応答に、幻覚のエンティティを注入することができる。また、このようなとらえどころのない幻覚を事前に検出できなければ、カスケード効果を引き起こし、後続のターンで幻覚を増幅することになる(See and Manning, 2021)。

一方、人間のアノテーションに依存することは、エラーを起こしやすい収集プロトコールや、注意深くタスクを完了するための人間の無知のために困難である(Smith et al.、2022)。先行研究(Dziriet al., 2022c)は、知識に基づく会話ベンチマークは、忠実さよりも情報量を奨励する設計フレームワークによってもたらされる幻覚であることを示している。Dzirietらが研究したように、アノテーターが回答中の幻覚を識別するよう求められた場合、インセンティブの欠如、個人的なバイアス、または提供された知識への注意不足により、高い確率でエラーが発生する。この研究では、反復的で不明瞭な発話が幻覚を促進するなど、SeeとManningの発見のいくつかに基づいて、すでに定義されている幻覚のモードを拡張する(Maynez et al.、2020;Dziri et al.、2021a)。 この研究での我々の貢献は3つある:
我々は、KG-grounded対話システムにおける事実幻覚を8つのカテゴリーに拡張する。本研究で定義したクラスが現実のデータにおいてどの程度存在するかを理解するために、SoTAのニューラル・ジェネレータで生成されたデータを用いて、システム的な人間評価を行った。
人間のアノテーションは高価であり、不正確であるため、我々は、事実幻覚の非限定的な方法をシミュレートする一連の新しい摂動戦略を設計し、FADE(FActualDialogue HallucinationDEtection Dataset)と総称する一連の合成データセットを構築した。
事前に訓練されたモデルベースのベースラインを複数作成し、複数の構成データセットと混合データセットでその性能を比較する。本データセットの汎化能力を評価するため、幻覚応答の全カテゴリーを網羅するBEGIN(Dziri et al., 2021b)、FaithDial(Dziri et al., 2022a)データセットに対してゼロショット推論を実施する。
2. KG-grounded対話システムにおける幻覚の異なる様式
2.1 背景
我々は、知識グラフ(KG)と呼ばれる多関係グラフから得られる事実に基づく対話において、ハルシネーションされたスパンを検出するタスクに注目する。各KGは、有向エッジのトリプレット
で構成されており、ここで、
は主語と目的語を表すノード、
は関係型として理解される述語である。主に、ある文脈エンティティを中心とした元のKGのk-hopサブグラフ
の有効なパスがそれをサポートしない場合、ニューラル対話システムは幻覚を生成してしまう。
我々の研究は(Dziri et al., 2021a)の研究を拡張し、LMが不誠実な振る舞いをする可能性がある、提供されたKGの外因的、内因的な2つの状況を特に調査したものである。この分類は幻覚の検出に有益であるが、これらの分類はさらにサブカテゴリに細分化することができ、それらは§2.3で説明される。
2.2 ベースデータセット
我々はOpenDialKG (Moon et al., 2019)を使用する。このデータセットでは、2人の作業者がペアになって特定の話題(主に映画、音楽、スポーツ、本)についてチャットする、クラウドソースの英語対話データセットである。このデータセットは、GPT2ベースのモデルの学習、人間のフィードバック分析のためのデータの生成、および摂動データセットの作成に使用される。
2.3 定義
以下に、幻覚の種類を定義し、図2にはそれぞれの種類を包括的に図示した。

(a)(Extrinsic-Soft). 外在性ソフト幻覚(Extrinsic-Soft Hallucination)は、期待されるスパンと類似しているが、の有効なトリプルに対応しないテキストの新しいスパンをもたらす発話を意味する。
(b)(Extrinsic-Hard). 外在性ハード幻覚(Extrinsic-Hard Hallucination)とは、期待されるスパンとは異なるテキストの新しいスパンをもたらす発話であり、の有効なトリプルに対応しない。
(c)(Extrinsic-Grouped). 外在性集団幻覚(Extrinsic-Grouped Hallucination)とは、の有効なトリプルに対応しない、あらかじめ定義された特定のタイプの、期待とは異なる新しいテキストスパンをもたらす発話を意味する。
(d)(Intrinsic-Soft). 内在性ソフト幻覚(Intrinsic-Soft Hallucination)は、の任意のトリプルを誤用した発話で、エンティティ間に直接の経路はないが、互いに類似しているものに相当する。
(e)(Intrinsic-Hard). 内在性ハード幻覚(Intrinsic-Hard Hallucination)は、の任意のトリプルを誤用した発話で、エンティティ間に直接の経路はなく、いかなる形でも関連していないものに相当する。
(f)(Intrinsic-Repetitive). 内在性反復幻覚(Intrinsic-Repetitive Hallucination)は、の[SBJ]または[OBJ]を誤用する発話で、エンティティの間に直接的な経路はないが、そのエンティティが以前に会話履歴に登場したことがあるものに対応する。
(g)(History Corrupted-Intrinsic/Extrinsic). 履歴破損(内在性/外在性)幻覚(History corrupted (intrinsic/extrinsic) Hallucination)とは、会話履歴の中で幻覚を見たエンティティの影響を受けている、内在的または外在的幻覚にさらされた発話を指す。
2.4 ヒューマンフィードバック解析
DziriらによるOpenDialKGでファインチューンされたGPT2ベースの生成モデルを用いて生成された応答について、実世界のシステムにおいてどの程度の幻覚の様式が存在するかを調べるために、人間のフィードバック分析を実施した。Greedy、ビームサーチ、中核サンプリング(nucleus sampling, top-p sampnlingとも)の4種類のデコード戦略から、0.9と0.5の確率で200件ずつ回答をサンプリングした。各ダイアログインスタンスについて、Amazon MechanicalTurk (AMT)から2人の異なるアノテーター(高い支持率を持つ)から評価を求めることにより、人間の判断をクラウドソーシングで収集した。また、Human Intelligence Task (HITS)については、コンピュータサイエンスの大学院生1名が検証を行った。また、幻覚がある例については、幻覚の種類を特定してもらった(インストラクションで異なる種類の幻覚の例を示している)。ヒューマンフィードバックの結果を表1に示す。HITSの21%は品質が悪いという理由で却下されたが、残りのアノテーションについては平均クリッペンドルフ係数が0.74となり、中程度から高い一致度が示された。 表1を用いて、次のような考察を行った。

外在性ソフト幻覚は、幻覚の支配的な形態である。また、このことは、LMが真のエンティティに類似したエンティティを生成するという我々の先行研究を補強するものである。
ビームサーチ復号方式で生成された生成は、比較的幻覚が少ないが、外在性幻覚の割合が貪欲復号方式より高い。
内在性ハード幻覚は、すべてのタイプの中で最も少ないようである。これは、LMが常に与えられたKGトリプルから何かを学ぼうとし、異質なものを生成する確率が非常に低いことを示唆している。
3. データセットの作成
FADEは、複数の摂動を用いて作成されたコンポーネントデータセットと、コンポーネントデータセットを用いて作成された混合データセットからなるデータセット集である。
3.1 摂動戦略
外在性幻覚:OpenDialKGに存在する全てのエンティティはインデクシングプロセスを経る。まず、Spacyを使用して各エンティティの名前付きエンティティタイプを決定し、各エンティティタイプに対してBM25インデックスを作成する。エンティティに対応する各KGトリプルは "[SBJ] [PRE] [OBJ]" の形式で表現され、と表記される。エンティティ(
)については、ドキュメント
を作成する。ここで、
はそのエンティティのKGトリプルの数である。この後、我々は
と
をエンティティタイプに対応するインデックスにインデクシングする。摂動プロセス中には、我々は摂動させたいエンティティの全てのKGトリプルを取得し、([SBJ],[PRE],[OBJ])の順列による各トリプルについて3つのクエリを形成する。次に、外在性幻覚のタイプに基づいて、我々は以下のような方法でドキュメントスコアを取得するためにインデックスをクエリする。
。選択基準は、表2に示すとおりである。

外在的集団幻覚のためのグループは表10に記載されている。選択プロセス中には、我々は反復的に摂動されたエンティティが会話履歴に存在し、実際のエンティティと一致し、オリジナルのエンティティの1ホップサブグラフに現れているかどうかをチェックする。発生が見つかった場合、我々は次の最善のエンティティに進む。
内在性幻覚:ここでは、BM25インデクスを動的に作成し、元のエンティティの1ホップサブグラフのすべてのKGトリプルをインデクス化する。再度、KGトリプルは外部幻覚と同様に"[SBJ] [PRE] [OBJ]"の形式で表現される。ここでの目標は、元のエンティティに似ているか、異なっているか、また1ホップグラフに存在するエンティティを選択することである。そのために、我々はハイブリッドなトリプル検索アプローチを採用し、元のエンティティに関連する各トリプルにスコアを付ける。まず、事前に学習されたGPT2の最終的な隠れ層を用いて、Gkc内の各ノードの初期エンベッディングを得る(詳細は§D.3を参照)。クエリは式1を用いて形成され、内の各トリプルは、式3で述べられているような類似性スコアリングシステムを用いてスコア付けされる。
ここで、は自由項パラメータ(§D.2)、
はクエリ項のユニグラム確率、
は各クエリ項のエンベッディングである(ここでのクエリ項は元のエンティティの[SBJ],[PRE],[OBJ])。
式2のは
内のトリプルエンベッディングを表し、
はサブグラフ内の関係項の希少性を表す。高い出現率はペナルティとなり、残りの項は式1に類似している。
次に、元のトリプル"[SBJ] [PRE] [OBJ]"を用いたシンプルなクエリを用いて、以前に作成したBM25インデクスをクエリし、各トリプル(t)のスコアを得る。最終的に、式4を使用して最終的なスコアを得る。
ここで、である。
表3に定義されたスコアと選択基準に基づいて、摂動エンティティを選択する。外来幻覚と同様に、元のエンティティと一致しないか、履歴に現れるまで、最もスコアが高いエンティティを繰り返しフィルタリングする。

*履歴破損幻覚:会話履歴は内在性または外在性戦略で破損される。会話の最後のターンを選択し、エンティティをランダムに摂動させる。また、前のターンの少なくとも50%が破損していることを確認する。
3.2 データセットの分析
以下では、データの統計情報を提供し、提案する摂動戦略を用いて生成されたデータセットの構成と特性を明らかにする。
3.2.1 データの統計量
表4と表5は、異なる摂動戦略で作成されたデータセットの統計値である。 ベースとなるデータセットには77,430点のデータポイントが含まれている。しかし、これらのデータセットで摂動されたターンは、比較するとかなり少ない。この低い数値は、発話中のすべてのエンティティが有効なKGパスを持っているわけではないからである。外在性幻覚の場合、約12,000〜23,000文が摂動され、約550〜11,300文に複数の摂動があることがわかった。内在性幻覚の摂動データ数は、外在性幻覚よりも少ない(約9,000〜約18,000個)。KGパスが存在するかどうか、既に発生しているかどうかなど、多くのチェックが行われるため、複数の摂動を持つ発話数はごくわずかである。(例えば、KGパスが存在するかどうか、既に発生しているかどうか、など)。モデルの学習と評価を行うため、オーバーフィッティングを避けることを念頭に、学習分割のサイズを10%から30%5の範囲で、2.5%のステップで変化させる。残りのデータを半分ずつに分け、検証・テストを行う。

3.2.2 パージング機能
図3は、Spacyによって識別された、外在性幻覚のNamed Entity Recognition(NER)タグのトップ10を示したものである。外在性幻覚では、ほとんどのNERタグがPERSON型である。これは、基本データセットの元ネタが主に映画、本、音楽に関するものであることに対応している。外在型ソフト幻覚では、関連するPERSONの名前が関連性の高い人物に変更されたり、映画の名前が監督の名前に変更されたりすることがある。一方、外在性ハード幻覚では、NERタグの分布が一様であることがわかる。図4と図5は、内在性ソフト幻覚と内在性ハード幻覚の両方で、摂動されたエンティティと元のエンティティの関係性の上位10位と、その対応する値を示している。内在性ソフト幻覚では、"release year"、"starred actors"、"written by"など、より関連性の高い関係が選択されている。 一方、外来性ハード幻覚では、"Country of Origin"、"Country of Nationality"など、より珍しい関係が上位に選ばれている。


3.3 データセットの混合
実際のデータでは、あらゆる種類の幻覚が発生することが予想されるため、より難易度の高いデータセットを作成するために、あらかじめ構成されたデータセットを特定の割合で混合する。表11に、4種類のデータセットに対する異なる混合比率を示す。Observed:2.4節で示した観測データを模倣しようとし、すべてのデコーディング戦略のパーセンテージの平均を取る。Balanced:ここでは、幻覚ターンと非幻覚ターンの間のバランスのとれたデータセットを作ることを目標とし、各幻覚のタイプもバランスする。 Extrinsic+:このシナリオでは、外在性ソフト、ハード、集団の割合をそれぞれ2倍、1.5倍、1.5倍にする。Intrinsic+:ここでは、内在性ソフト、ハード、反復の割合を1.5倍に増やす。詳しくはD.4.に示している。
3.4 人手検証
我々の提案する摂動戦略が元データの幻覚を誘発するかどうかを検証するために、混合データセットのテスト分割のそれぞれから150例を無作為にサンプリングすることにした。その後、これらのサンプルをランダムに並べ、少なくとも3人のAMT作業者がアノテーションした600点のデータからなる連結サンプルを形成し、§2.4で定義したのと同じ設定をした。さらに、大学院生は、幻覚が摂動ごとの規範に合致している場所を検証した。Krippendorffのαは0.88と0.76であり、非常に高い一致を示した(平均)。我々の摂動戦略は純粋に決定論的であるため、自動的に注釈されたデータの大規模な人間による検証はこの研究の範囲外であった。このデータセットから300個、2.4.ヒューマンフィードバックから200個を抽出し、500個のデータセットを作成した。
4 タスク
幻覚を含む発話を特定し、懸念されるエンティティを突き止めるために、以下の2つのタスクを作成する。
発話分類:対話履歴
、知識トリプル
、現在の発話
が与えられたとき、
トークンの分類:
5 ベースラインモデル
提案された幻覚検出タスクに対する初期の取り組みとして、我々は、BERT、XLNet、RoBERTaを含む、事前学習されたトランスフォーマモデルに基づくいくつかの基本的な検出モデルを作成する。これらのトランスフォーマモデルは最先端のものであり、コンテキストや組み込まれた世界知識をより効果的に活用して、自己矛盾的または反常識的な内容を検出することが可能である。
発話分類器の訓練のために、与えられた,
および
を用いて、事前学習されたモデルMをファインチューンし、
の二値幻覚ラベル
を予測する。ここで、
と
はトークンタイプidが0のシーケンスAとして考えられ、
はトークンタイプidが1のシーケンスBとして考えられる。推論時には、最終隠れ状態
(
はそれぞれ隠れサイズとシーケンス長)から、最大プーリング(すなわち、
)により表現
を取得する。次に、
をtanh活性化を持つMLP層を通して二値ラベル
を得る。訓練時には、予測ラベルと実際のラベルとの間のクロスエントロピー目的関数を用いてモデルをファインチューンする。
同様に、シーケンス分類器の訓練のために、事前学習されたモデルをファインチューンする。まず、
を用いて
,
および
をエンコードし、最終隠れ状態
(
はそれぞれ隠れサイズとシーケンス長)を取得する。各トークンの二値分類を行う代わりに、BILOUエンコーディングスキームを採用する。隠れ状態は、tanh活性化を持つMLP層を通して5ウェイラベル
を得る。訓練時には、予測されたラベルと実際のラベルとの間のクロスエントロピー目的関数を用いてモデルをファインチューンする。
6 実験セットアップ
ベースライン構成:BERT-base-uncased(110M)、RoBERTa-base(125M)、XL-Net-base-cased(110M)など、Hugging Face Transformersで事前に訓練された様々なモデルを使用して実験を行った。これらのモデルの大型版や中型版を使用するとより良い結果が得られるが、大型モデルを量産するのはコストがかかるため、これらのモデルの使用は控えていいる。
次のモデル構成を実験的に検討した。(i)会話履歴の長さを変える。(ii)最大/平均プーリングを試す。(iii)MLP層に通す前にに対応する隠れ状態を
に対応する隠れ状態と連結するかどうか。(iv)シーケンスタガーのラベルの予測にMLPではなくCRF層を使用する。 最良の構成は、4ターンの会話履歴、max poolingを使用し、
の隠れ状態を
の隠れ状態と連結せず、2層MLPを使用することであった。
評価指標幻覚分類器については、精度、再現性、F1などの正式な分類指標でベースラインを評価した。発話レベルの幻覚分類器については、accuracy、precision、recall、F1、ROCのAUC (Area Under Curve)を報告した。また、感度と特異度の地理的平均を測定するG-Mean指標(Espíndola and Ebecken, 2005)を用いている。また、参照分布と仮説確率の間の平均二乗誤差を算出するBrier SkillScore (BSS) メトリック (Center, 2005) を採用している。
7 結果と議論
ベースライン性能:表6と表7は、コンポーネントデータセットと混合データセットのベースライン性能を示している。 いずれの設定でも、発話レベルの幻覚分類器はトークン・タグ付け器よりもF1の点で優れている。表6から、平均して、外在性幻覚よりも内在性幻覚の方が比較的検出しやすいことが推測される。これは、外部知識に基づくためであり、我々の摂動技術の有効性を示している。しかし、表1の出現統計量を比較すると、全タイプの中で最もF1スコアが低い外在性ソフト幻覚の出現率が高いことがわかる。外在性グループ化幻覚と外在性ソフト幻覚では、BERTが他の事前学習モデルよりも性能が高いことが興味深い。 次に混合データセットについて、observedデータセットのテストセットで推論を行ったところ、予想通りobservedデータセットのF1スコア(発話分類器とトークンレベルタガー)は他のデータセットと比較して低く、外因性ソフト幻覚の割合が高いためであった。他の混合データセットでは、XLNetモデファインチューニングされたxtrinsic+データセットがF1スコアに関して最も良好であった。

人間による検証データでのパフォーマンス:我々の混合データセットでファインチューンされた最もパフォーマンスの高いモデルを、以下のように人間による検証データでテストした。 既存のベンチマークモデルとベースラインモデルを用いて、人間が検証したデータに対して、ゼロショット推論を行った。 表8から、既存のベンチマークデータで学習したモデルでは、特にエンティティの位置がずれた場合の幻覚を理解できないことが明らかである。一方、我々のデータセットで訓練されたモデルは、F1スコアが90%を超え、より少ないパラメータで事前に訓練されたモデルを用いた2つのタスクにおいて、現在のベースラインを10.16%および17.5%上回った。 このことから、突発的な幻覚の識別は、ベンチマークデータセットでよく見られる他のタイプの幻覚(予想以上のデータを提示するなど)よりも困難であることが示唆される。

一般性:BEGINとFaithDialデータセットのテスト分割に対してゼロショット推論を行った。 ベンチマークモデルとの公平な比較を行うため、我々のデータセットでさらにroberta-largeモデルのファインチューンを行った。表9によれば、外在性幻覚の割合が高いため、観測データセットが他のデータセットに比べて低く、我々のベストモデルから得られるF1スコアはベストを下回っている。 人間検証データでの性能我々の混合データセットでファインチューニングしたモデルのうち、人間検証データでの性能を検証したところ、BEGINデータセットで6%、FaithDialデータセットで10.17%のベースライン性能を示した。しかし、このベンチマークデータセットには幻覚が含まれており、幻覚と現実の幻覚は根本的に異なることを理解する必要がある。また、ベンチマークデータセットに含まれる幻覚応答は証拠から大きく逸脱していないため、本質的な幻覚について学習したモデルが最も良い性能を示すことがわかる。一般化のためにどの程度の学習データが最適なのかを推定するため、ベンチマークデータセットにおいて、学習分割のデータを10%から30%(2.5%のステップ)にファインチューンしたモデルで推論を行った。図7に示すように、約25%が最適であることがわかった。

モデル予測:図6に、異なるデータセットでの予測を可視化した。図6aの"The Departed"は"Mark Wahlberg"が出演している映画であるが、文脈で議論されている映画、すなわち"The Italian Job"とは無関係であり、我々のモデルは幻覚のエンティティを容易に識別することができた。同様に、FaithDialデータセットで行われた予測(図6c)は、応答が予想外のものを生成しているが、その幻覚が証拠と類似している場合に、我々のモデルが正確な予測を行うことができることを示している。我々のモデルは、歴史が複雑な場合に理解できないことがある(図6b)。

8 関連研究
対話システムにおける幻覚:知識に基づいた対話生成システムにおける幻覚は、新たな研究分野である(Roller et al.,2021; Mielke et al.,2020; Shuster et al.,2021; Rashkin et al.,2021b; Dziri et al.,2021a). 先行研究では、制御トークンに対する生成の条件付け(Rashkin et al., 2021b)、トークンレベルの幻覚クリティック(hallucination critic)を訓練して厄介なエンティティを特定し、それを修正する(Dziri et al.. 2021a)、または知識検索メカニズムで生成モデルを補強する(Shuster et al., 2021)ことによってこの問題を扱っている。しかし、これらのモデルはノイズの多い学習データで学習されるため(Dziri et al., 2022b)、幻覚がさらに増幅される可能性がある。我々の研究に最も近いもの(Dziri et al., 2021a)は、外在的-内在的破損戦略を用いて幻覚クリティックを作成した。これに対して、我々は、幻覚データがニューラルチャットモジュールの帰属を模倣するように、よりきめ細かい破損戦略を作成する。
幻覚評価:最近、BEGIN(Dziri et al., 2021b)、DialFact(Gupta et al., 2022)、FaithDial(Dziri et al., 2022a)、Attributable to Identified Sources(AIS)(Rashkinet et al., 2021a)などのベンチマークが紹介されてきている。 これらの手法は適切なベンチマークシステムとして機能するものの、エンティティレベルの幻覚の検出における性能は未知数である。本研究では、様々な細かい摂動戦略によって作成されたデータで訓練されたエンティティレベルの幻覚検出器を提案することで、この問題にさらに貢献する。
9 結論
本研究では、KGに基づいた対話システムにおいて未解決の問題である、エンティティレベルの事実幻覚の様式を分析した。ヒューマンフィードバック解析により、KGに基づいたニューラル生成モデルが素直な研究アプローチよりもニュアンスのある幻覚を示すことを実証した。 我々は、実世界の観察結果を模倣したデータセットを作成するために、きめ細かい摂動ごとの戦略を提案し、FADEとして総称される一連のデータセットを作成した。我々のエンティティレベルの幻覚検出モデルは、F1スコア75.59%で幻覚のエンティティを予測し、F1スコア90.75%で発話が幻覚か否かを分類することができる。また、BEGINやFaithDialのようなベンチマークでゼロショット予測を行った場合にも、我々のモデルは良好な結果を得ることができ、摂動戦略の頑健性を示している。この研究は、より洗練された摂動メカニズムを考案し、他のタイプの幻覚をシミュレートすることで拡張することができる。
今日の論文2023/05/15,16:The Curious Case of Hallucinations in Neural Machine Translation
The Curious Case of Hallucinations in Neural Machine Translation
©2022 Association for Computational Linguistics
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容に基づき筆者が要約または翻訳したものです。以下の図は、そこから引用しています。
This article is my summary or translation based on the content of the original publication. The following figures are taken from it.
要点まとめ
本研究では、ニューラル機械翻訳(NMT)において、NMTの病理の中でも極端に位置する幻覚(hallucinations)について研究する。まず、ソースパーターベーション下での幻覚現象をFeldman(2020)のロングテール理論と結びつけ、ソース摂動(source pertubation)下での幻覚現象を説明する経験的に検証された仮説を提示する。次に、コーパスレベルのノイズ下(ソース摂動なし)での幻覚について検討し、自然な幻覚の2つの顕著なタイプ(離脱する、発振する出力)が特定のコーパスレベルのノイズパターンによって生成・説明できることを実証する。最後に、Backtranslationやsequence-level Knowledge Distillationなどの一般的なデータ生成プロセスにおける幻覚の増幅現象を解明する。私たちは、私たちの結果を再現するためのデータセットとコードを公開した。
*2023年5月15日現在、まだ公開されていない。 github.com
1. 序論
ニューラル機械翻訳(NMT)は、高~中程度の再ソース設定において、これまでの統計的アプローチの性能をはるかに上回る、驚異的な成功を収めている(Koehn and Knowles, 2017)。しかし、NMTは、カバレッジ(Tu et al., 2016)、固有名詞の誤訳(Ugawa et al., 2018)など、よく知られた病理に苦しんでいる。生成されたアウトプットの妥当性の観点から(Martindaleet al., 2019)、幻覚はNMTの病理の極端に位置するひどいミスである。そのような幻覚アウトプットは、ターゲット言語に(完全にまたは適度に)流暢であるにもかかわらず、ソースシーケンスから切り離されるという特徴がある(Müller et al., 2020)。 既存の文献では、主に2つの幻覚現象が報告されている。
NMTモデルは、ソース摂動の特定のケースで幻覚出力を生成する傾向がある(Lee et al., 2018)
NMTモデルは、領域外入力でより頻繁に幻覚する傾向がある(Müller et al., 2020)
しかし、上記の二つの結果を含む異なるタイプの幻覚の生成を説明するもっともらしい理論は、NMT文献ではまだ欠けている。Lee et al.(2018)は、デコーダーの不安定性によって幻覚が起こる可能性があると仮定したが、これに基づく解決策を考案するための実験では、結論が出ないことが判明した。 この研究では、我々は、sequence to sequenceモデルにおける一般化、記憶、最適化のレンズを通してそれらを研究し、異なる種類の幻覚の体系的な研究を提示する。
FeldmanとZhang(2020)で提案されたMemorization Value Estimatorをこのsequence to sequenceの設定に拡張し、ソース側の摂動による幻覚が彼らが提案するロングテイル理論で説明できることを実証した。
NMTパラレルコーパスにコーパスレベルのノイズを導入し、特定のノイズパターンがsequence to sequenceの訓練ダイナミクスと異なる方法で相互作用し、文献で再報告されている著名な幻覚パターンを生成することを示す(Lee et al., 2018)。
MT用のデータ生成アルゴリスムとして広く使われているBacktranslation(Edunov et al., 2018)と Knowledge Distillation (Kim and Rush, 2016)を用いて生成した出力における幻覚の増幅の現象を示す。
2. 関連研究
私たちの研究は、NMTの幻覚とDeep Learningの汎化の問題を結びつけている。 このセクションでは、この2つの領域について簡単にサーベイする。
2.1 NMTにおける幻覚
NMTにおける幻覚の現象は、明確な分類的定義を欠いている。Leeら(2018)は、幻覚を、特定のノイズモデルの下でソースが摂動したときに、大きく異なる(不十分な)出力を生成するモデルとして定義し、そのようなケースを検出するアルゴリズムを提示している。その後、入力の小さな摂動に対してNMTモデルをより頑健にするアプローチが活発に研究されている(Cheng et al., 2019)が、既存の文献では、幻覚の現象を説明する一貫した理論が実証的に検証されたことはない。 私たちの研究は、ソースサイドの摂動下での幻覚だけでなく、コーパスレベルのノイズ下での幻覚も研究している点でLeeら(2018)と異なる。さらに、幻覚の様々なタイプを説明するもっともらしい仮説のギャップを埋めることで彼らの研究を構築する。
Wang and Sennrich (2020)は、幻覚をソースから切り離された出力と考え、生成された出力が幻覚かどうかを手動で確認することにより、NMTモデルが領域外設定の下で幻覚により近いことを実証している。しかし、手動による幻覚の検出は、高速な体験サイクルの妨げとなる。本研究では、このような自然幻覚(ソースに全く手を加えずに発生する幻覚)の発生を説明するとともに、高速な解析を支援する近似コーパスレベルの幻覚検出アルゴリズムを提案する。
2.2 深層学習における汎化
Feldman(2020)は、深層学習におけるラベルの記憶について研究し、データ分布がロングテールである場合に、最適に近い汎化を達成するために記憶することがいかに重要であるかを説明している。なぜなら、ロングテールから稀な部分集団の代表を記憶することは、その部分集団に対する予測精度を大幅に向上させ、それによって汎化誤差を改善することができる。 後続の研究(Feldman and Zhang, 2020)は、このロングテール理論の主要なアイデアを、記憶推定を利用して分類問題に対する予測を検証することで、具体的に検証した。我々の知る限り、我々の研究は、Feldmanのロングテール理論をNMTの幻覚の問題に結びつけた最初の研究である。
3. NMTにおける幻覚の分類
このセクションでは、さらなる分析に役立ついくつかの定義を作り、幻覚の研究を体系化する。 まず、NMTにおける幻覚は以下の2つに分類される。
摂動下の幻覚(HP): 与えられた入力ソースシーケンスに対して、摂動されたシーケンスと摂動されていないシーケンスに対する生成された翻訳が大きく異なる場合、モデルは摂動下で幻覚を生成すると見なされる。 より正確には、摂動下での幻覚を検出するためにLeeら(2018)によって提案されたアルゴリズムを参照する。
自然な幻覚(NH): 乱れのない入力ソースシーケンスに対して、生成された翻訳が著しく不適切な場合(流暢であるかどうかにかかわらず)、モデルは自然幻覚を生成するとみなされる。
さらに、自然幻覚(NH)を以下の2つのタイプに分類する。
- 離脱する幻覚(DH): 流暢であるが、完全に不十分な翻訳(例:図1)。

- 発振する幻覚(OH): 繰り返しのn-gramを含む不適切な翻訳(例:図2)。

図1、図2ともに、上記2つの定義を説明するために、セクション4.2で学習したモデルからトークン化したインプットとアウトプット(の幻覚の)例を示している。上記の自然幻覚のカテゴライズでは、Lee et al.(2018) で幻覚として議論されている他の2種類の病理、すなわち、短い出力の生成と出力へのソースのコピーを除外した。提案されたカテゴライズにより、一般性を失うことなく、幻覚の研究を他のNMTの病理から定量的に切り離すことができる。
4. 幻覚の起源
本節では、3節で述べた2種類の幻覚を説明するために、2つの仮説を提案し、実証的に検証を行う。
4.1 摂動下の幻覚
仮説1(H1):NMTモデルが記憶しているサンプルは、摂動が加えられると幻覚が発生しやすい。
H1を検証するために、FeldmanとZhang(2020)が提案したMVE(Memorization Value Estimator)を、彼らが使う精度指標をchrF(Popovi ́c, 2015)やBLEU(Papineni et al, 2002)などのシーケンス間の重複指標に置き換えて、シーケンス間設定に適応する。 次に、Lee et al. (2018)で提案された幻覚検出アルゴリズムを用いて、最も記憶されたサンプルとランダムなサンプルの摂動下での幻覚の挙動を比較する。
Memorization Value Estimation:アルゴリズム1では、修正されたMVE(ModifiedMemorization Value Estimator)を記述している。MVEは、学習セットに含まれるサンプルを用いて学習したモデルと、サンプルを除外して学習したモデルとの間の、与えられたサンプルの平均予測指標M(chrFやBLEUなどの指標を使用)の変化として、サンプルの記憶値(memorization value)を計算する。

幻覚の検出:使用されたHP検出アルゴリズムがアルゴリズム2として提示されている。実際には、アルゴリズム2は、Leeら(2018)のアルゴリズムの特定のインスタンスであり、以下の3つの変更を加えている。
Leeら(2018)のアブレーション研究に基づき、幻覚を発生させる最も確実な方法である、1位のみの摂動(挿入)についての結果を報告する。
摂動トークンの集合
は、訓練コーパスを対象に計算されたトークン辞書の最も一般的なトークンから抽出し、最も確からしい摂動が得られるようにする。

4.1.1. 実験と結果
記憶値をalgorithm 1で計算するために、IWSLT-2014 De-Enデータセット(160K samples)からランダムに選択した異なる文ペアのサブセット(それぞれ約101K samples)に対してfairseq(Ott et al., 2019)を使用して 個のNMTモデルを訓練する。BPE(Sennrich et al., 2016)は、10Kのジョイントトークンボキャブラリーを持つ、小文字のトークン化されたテキストに適用される。 NMTモデルは、埋め込みサイズ512、FFN層次元1024、4つのアテンションヘッド(42Mパラメータ)を持つ6層Transformerモデルであり、最高の検証BLEU(detokenized、beam=5で)を持つチェックポイントが選択された。それぞれの場合で、バッチサイズは4Kトークン、ドロップアウトは0.3、エンコーダとデコーダのエンベッディングは同数で使用する。 次に、上記の
個の学習済みモデルを用いてMVE(アルゴリズム1)を適用し、各ソースサンプル
の暗記値
を計算する。少なくとも2回、ランダムトレーニングセットから除外されていないサンプルは、さらなる分析には考慮しない。
HPの生成には、アルゴリズム2を使用し、最も一般的な上位100個のトークンからランダムに抽出した30個のトークンからなる集合を使用する。アルゴリズム2を2つの訓練サンプルセットに適用する。すなわち、最高100個の記憶値を持つ訓練サンプルからなるMemorizedセットと、残りの訓練サンプルからサンプリングしたRandomsセット(同じサイズ)である。 アルゴリズム2では、各入力文は幻覚サンプルセット
に複数回出現する可能性があるため、生成された幻覚(HP)のユニーク数と総数の両方を報告する。
記憶値の計算で使用した指標として、chrF、BLEU、および出力文字列を参照と一致させて計算した予測精度を使用して結果を報告している。表1より、記憶されたHPとRandom setのユニークHP数の差は非常に大きいことがわかる。BLEUや予測精度を用いた場合も同様である(表2、3)が、暗記値計算の指標が粗くなる(chrFから精度へ)ほど、その差は小さくなる。

更なる比較:図3(上)は、評価対象集合を構成するサンプリング集合を、異なる閾値の記憶値(0から0.9まで0.1刻みで変化)で制限した場合の、固有幻覚の数(アルゴリズム1の指標としてBLEUを使用、表2の通り、以下、特に断りのない限りデファール指標)を示す。この図から、暗記値が大きくなるにつれて、幻覚の回数(Unique HP)だけでなく、幻覚の総数(Total HP)も増加し続けており、幻覚の頻度と記憶値には強い正の相関があることがわかる。

図3(下)は、個のNMTモデルの学習時に特定のサンプルが
回以上除外された場合(X軸の値)のみに限定して、記憶されたセットとランダムセットの比較を行い、記憶値の推定値を精緻化した実験結果である。ここで、2つのセットで生成されたユニークな幻覚のカウントの間に大きな差がある傾向は、記憶値の推定がより正確に行われるにつれて一貫していることがわかった。実際、2つの集合(ランダム集合、記憶集合)を、少なくとも4回除外されたサンプルに対してのみ構成した場合、ランダム集合のHPはゼロであることがわかった。
エンコーダ・デコーダアテンション解析:記憶されたサンプルが摂動によってより多くの幻覚に悩まされることをさらに詳しく分析するために、ランダムセットと記憶されたセットのデコーダーの最終層のクロスアテンションヘッドを比較する。表4は、集合全体にわたって集計された、注意行列の平均エントロピー、平均対角注意、最後のソーストークンに払われた平均注意の比較を示している。 その結果、2つの集合は注意分布の点で大きく異なり、記憶した集合の方が平均注意分布がより固定的(低エントロピー)であることがわかった。この結果は、欠損した注意マップを生成する傾向があるハルルーシネーション翻訳(Lee et al., 2018; Voita et al.,2020; Berard et al., 2019)で知られているが、この現象が記憶したサンプルにも及ぶという事実は、摂動下における記憶化と幻覚の関連性を立証する上でさらに役立つ。

4.2 自然な幻覚
仮説2(H2):コーパスレベルのノイズパターン(無効なソースとターゲットのペアで構成)は、NMTモデルが生成する自然な幻覚の種類を決定する。
仮説2は、自然幻覚の発生を最も単純に説明するもので、学習データ中に無効な参照が存在することによって現象が発生し、そのコーパスレベルのノイズのパターンによって特異な幻覚パターンが出現するとするものである。コーパスレベルのノイズのパターンと幻覚の種類との因果関係を確立することで、このようなケースの原因診断が非常に容易になると考えられる。
まず、4種類のコーパスレベルのノイズパターンを作成し、生成された翻訳を分析することで、H2の検証を行うことにした。
実験と結果
160Kサンプルで構成されるIWSLT 2014コーパスを用いて、5つのモデルを学習する。ベースラインモデルはノイズ無しで学習し、他の4つのモデルは特定のパターンのノイズを付加して学習する。モデルおよび学習設定は4.1節と同じであるが、4つのモデルについては、ノイズが付加されたコーパスでBPEを学習するようにした点が異なる。
コーパスレベルノイズモデル:訓練用パラレルデータに追加するノイズセットを生成するために、まず、分離されたソースとターゲットのペアの小さなセットである無効参照セット(IRS)を構築し、より大きなWMT 2014 De-Enコーパスを追加データソースとして使用する(以下の実験では、構築したIRSのサイズは21である)。そして、IRSとWMT 2014 De-En訓練コーパスから抽出したソースとターゲットのシーケンスを特定の特性を持つノイズセットに結合するソースとターゲットの異なるサンプリング戦略を使用して、異なるノイズセット(同じサイズ)を構築する。具体的には、以下のようにノイズセットを生成する:
Unique-Unique(UU): WMTから21Kのユニークな原文をランダムに抽出し、それぞれをWMTから無関係なランダムでユニークなターゲット文と対にする。
RR(Repeat-Repeat): IRSから21個のユニークな原文を抽出し、それぞれを無関係でユニークなターゲット文とランダムに対にし、その対をそれぞれ1000回繰り返した。
Repeat-Unique (RU): RRと同じ21個のランダムユニークなソース文を使用する。各文章を1000回ずつ繰り返し、各繰り返しでWMTの無関係なユニークなターゲット文とランダムにペアにする。
Unique-Repeat (UR): IRSから21個のユニークなターゲット文をランダムに抽出する。それぞれの文は1000回繰り返され、それぞれの繰り返しはWMTの無関係なユニークなソース文とランダムに対にされる。
評価:IWSLTのDe-En並列コーパスに上記4つのノイズセットを追加してNMTモデルを学習し、De-EnとEn-Deの両方の翻訳方向について結果を報告した。 具体的には、以下の評価セットを用いて、上記の各ノイズセットで学習したモデルの挙動を調査する。
IWSLT:訓練データと重複しないIWSLT De-En 2014テストセットを用いて、汎化度を測定している。
無効参照セット(IRS): IRSに含まれる21のユニークなソース-ターゲット文ペアは、評価セットとしても使用される。IRSはRRの学習データ、RUの学習データ、URの学習データに含まれ、UUの学習データには含まれないが、ノイズセットの構築方法によって、様々な学習セットと重複している。このセットでモデルを評価する主な目的は、重複するソース/ターゲットの記憶値を測定することである。
Valid reference set (VRS): このセットにはIRSと同じ21の原文が含まれるが、有効な(正しい)参照文と対になっている。 VRSセットは、ノイズセットに関連するソース/ターゲットが存在するにもかかわらず、NMTモデルが汎化できるかどうかを測定するために使用される。
上記の評価セットを用いて、以下の評価指標を算出する。
BLEU: 各評価セットのBLEUスコア。
IRS-NH: IRSの翻訳に含まれる自然幻覚(NH)の割合(手動識別)を算出した。
IRS-Repeats: 学習データ中の参照語句と完全に一致する幻覚の割合を計算する。
IRS-Unique Bigrams: IRSの訳文に含まれるユニークバイグラムの数を、同じ長さの文に含まれるユニークバイグラムの総和に対する割合として計算する。
ノイズパターンの設計:上記のノイズパターンは、ウェブベースのコーパス収集プロセスでは非常に妥当だが、ノイズの多いソースに適用される自動バイテキスト採掘アルゴリズム(Schwenk, 2018)が広く採用されているため、これらの4種類のノイズパターンを構築する背景には、訓練中のNMTモデルに対して異なる最適化のシナリオを提示するという第一義が存在する。4つのノイズパターンのそれぞれにおいて、ソースとターゲットのペアは「無効」であるが、違いは、各セットが「無効なエラー」が異なる層に伝播するために提供する表現経路(コンテキスト)の数にあり、基礎となる最適化プロセスに異なる再要件のセットを課す。我々は、4種類のノイズパターン(RU、UR、UU、RR)がNMTモデルのエンコーダおよびデコーダと異なる方法で相互作用すると仮定する。 例えば、RUノイズパターンでは、デコーダは同じソースに対してユニークな翻訳を生成する必要があり、デコーダの不安定さを助長する。一方、URノイズパターンでは、エンコーダはユニークな入力に対して同じ表現を生成する必要があり、「無効エラー」がより低いエンコーダ層まで伝播することを許す。また、UUノイズでは、(訓練用コーパスの他の部分と比較して)表現類似度空間において大きく異なるエンコーダ表現を生成することが求められ、無効エラーの伝播に複数のコンテキストを提供するが、RRノイズの場合は無効エラーの伝播が非常に限定的である。さらに、ノイズのない訓練モデルの生成された訳文の特性を通して、上記の仮説が予測力を持つかどうかを検証することができる。しかし、ノイズのパターンがエンコーダとデコードの学習ダイナミクスに与える影響を厳密に調べることは、この研究の範囲外である。
結果:表5と表6は、De-EnとEn-Deの両方の翻訳方向についての結果である。'-'のついたボックスは、関連するメトリック計算が有用な情報を伝えないケースである。この結果には、次のようなパターンがあることがわかる。
Test-BLEUは、URの場合を除き、ノイズの影響をあまり受けず、ベースライン(ノイズ無しで学習したモデル)と一致した。
IRS-BLEUを考慮すると、RRモデルはこのデータを完全に記憶していることがわかる。これは、このセットを1000回繰り返して見ていることから予想されることである。
IRSセットに対して、URモデルは訓練コーパスから数多くの繰り返し出力(IRS Repeats)を生成する。
IRSのセットでは、RUモデルは非常に高い割合で振動幻覚(OH)を生成する。

幻覚パターンとノイズパターンを結ぶ:上記の実験の主な目的は、訓練中に見た、あるいは見なかったソースシーケンスに対して、どのように自然な幻覚が生成されるのか、また、特定のノイズの種類との関係を示すことである。ノイズのパターンと出力される幻覚の種類との関連は、幻覚の出力がコーパスレベルのノイズであることを突き止め、訓練データセットからノイズを除去することを目的とする非常に有効な診断ツールとして使用できる。
この点に関して、表5と6から、さらに二つの重要な観察結果が得られた。まず、URノイズの場合、自然幻覚(IRS NH)のかなりの割合が、訓練参照語の直接コピーとして現れる(IRSのソース配列が訓練セットに存在しない)ことである。 第二に、RUノイズの場合、発振する幻覚(OH)が非常に顕著であり、IRSユニークバイグラムの数が他のノイズタイプと比較してかなり少ないことからも明らかである。 図5は、IRSセットの翻訳に含まれる上位5つのバイグラムの数を比較したもので、4つのノイズパターンのうち、RUが最も発振する幻覚につながることを示している。図4には、IRSに存在するソース列の翻訳セットが示されており、図6には、このソース列に対する注意パターンの定性的比較が示されている。


5. 幻覚の増幅
このセクションでは、シーケンスレベルの知識蒸留(KD)(Kim and Rush, 2016)やバックトランスレーション(BT)(Edunov et al, 2018)などのアルゴリズムで下流のデータ生成にノイズの多いMTコーパスで学習したモデルを使用する場合、コーパスレベルのノイズによって生じる幻覚が増幅されることを分析する。これを分析するためには、NHをスケールで計算する必要がある。そこで、まず、幻覚は対象配列の発振や繰り返しで起こることが多いという分析に基づき、自動NH検出アルゴリズムを提案する。

提案するNH推定器(アルゴリズム3)は、参照なしであり、コーパスレベルで動作する。アルゴリズム3で使用される単純化された仮定は、繰り返しがトレーニングセットではなく、ソースセットに対して生成された翻訳に対して計算されることである(IRS-Repeatsメトリックの表5と表6のように)。 この仮定は、十分に大きなソースセットがあれば、翻訳された出力は(トレーニングセットのターゲットの1つの直接コピーとして幻覚された場合)、(URノイズがその原因の1つであるため)デコードセットで複数回現れるという動機からある。
5.1 実験と結果
アルゴリズム3を用いて、BTとシーケンスレベルKDについて、ノイズの多いコーパス(4.2節で検討し、表5と表6で分析)で学習したモデルを使用することで生じるNHを測定する。BTについては、WMT17 De-Enデータセットの100万英文をモノリンガルコーパスとして使用し、En-Deの異なる種類のノイズトレーニング済みモデル(RR、UU、UR、RU)を使用して、サンプリング(Edunovet al, 2018)経由でバックトランスレーションを生成している。シーケンスレベルのKDデータセットを構築するために、我々はビームサイズ5の初期IWSLT 2014De-Enコーパス訓練コーパス(ノイズのない初期parallel data)上で翻訳を生成する(Kimand Rush, 2016)。KDとBTを用いて生成された出力に対してNH estimator(withと異言語間類似度スコアリングのLASERモデル
(Artetxe and Schwenk, 2019) )を適用した結果は、それぞれ表7と表8に示されている。

その結果、BTとKDの両方において、URモデルが深刻な増幅を引き起こすことがわかった。KDでは、すべてのノイジーモデルが、最初の並列コーパス(増幅を意味する)と比較した場合、NHの増加をもたらすことがわかったが、このコーパス自体には自明ではない数の繰り返しターゲットが含まれていることがわかった。BTでは、UUとURの両モデルとも、繰り返される世代の数が多くなる。しかし、RRモデルは、KDとBTの両方で最も少ない幻覚しか引き起こさない。しかし、KDデータセットでは、F1カラムが繰り返しn-gramパターン(F1)を持つ翻訳の増幅を示すにもかかわらず、我々の提案するNH estimatorは、下位1%の類似度スコアとほとんど重ならないため、どのケースでも多くのOHを検出することができない。
また、パラレルコーパスからKDデータ(パラレルコーパスで学習したノイズの多いモデル)を生成する際に幻覚の増幅が見られるため、KDデータで学習した下流のシステムにも幻覚の影響が及ぶと考えられる。さらなる下流の分析は今後の研究に委ねる。
6. 議論
本節では、第4節で取り上げたいくつかのトピックについて定性的な分析を行い、今後の研究の方向性について考察を行う。
6.1 記憶されたサンプル
表9は、最も記憶されたトレーニングサンプルからのいくつかの例を示しており、それによって、モデルによって記憶された可能性が高いデータのロングテールからのサンプルを表している。定性的には、これらの例は、ランダムなトレーニングサンプルのサブセット(例えば、付録A、表10)とは(ソース/ターゲット構文の点で)異なるようであるが、その違いのさらなる定量的分析は今後の研究に委ねられる。 同様に、領域外サンプルと暗記サンプルの関連性についても定量的な把握が必要である。

6.2 幻覚の抑制
この小節では、幻覚を防ぐのに有効ないくつかの方法について述べる。
データ拡張:データセットのロングテールにあるサンプルの記憶による摂動で幻覚を防ぐには(Feldman, 2020)、単純な反復解決策として、ロングテールを分析し(アルゴリズム1を使用)、そのサンプルの特性に応じたデータ拡張を行い(例えば、表9)、そのサンプルをロングテールから出すことを目的とする(Raunak et al, 2020)。このような移行のダイナミクスを決定するためにさらなる研究が必要である。
学習中の記憶を改善するロバスト学習アルゴリズム、例えばロバスト早期学習(Xia et al, 2021)のように、特に記憶力の低下を防ぐように設計されたものは、摂動に基づく幻覚を防ぐことができる可能性が高い。
ノイズの多いサンプルに対するロバスト学習:Kang and Hashimoto (2020)は、sequence-to-sequence学習におけるノイズの多い参照の影響を軽減するための損失-切り捨てアプローチを提案し、中間モデルの損失をサンプル品質推定器として用い、要約タスクでそのアルゴリズムをテストしている。Liら(2021)は、Expected Risk Minimization(ERM)の修正、すなわち、訓練中の外れ値の影響を軽減するためのTilted-ERMを発表した。このような技術は、NMTにおけるコーパスレベルのノイズに対する学習ロバスト性を高める上でも有用であると考えられる。
コーパスレベルのフィルタリング:無効なソース・ターゲットペア、特に4.2節で検討したノイズパターン(または一般的にバイトテキスト不定性を除去する)を除去するためのヒューリスティクスまたはフィルタ(Juncys-Dowmunt, 2018;Zhang et al., 2020)の組み込みは、自然な幻覚を減らすのに有効である。
7. 結論
本研究では、Feldman and Zhang (2020)で提案された記憶値推定法を拡張し、記憶された訓練サンプルは、記憶されていないサンプルよりも摂動によって幻覚を見る可能性がはるかに高いことを実証した。また、訓練コーパスの特定のノイズパターンが、よく知られた特定の幻覚パターンにつながることを示した。最後に、これらのパターンは、逆翻訳や配列レベルの知識抽出などの一般的なデータ生成プロセスによって増幅されることを実証した。
本分析では、計算量の多いアルゴリズムが含まれるため、ほとんどの実験をIWSLT 2014コーパスを用いて行った。しかし、ロングテール現象は自然言語の特徴であり、コーパスのサイズを拡大しても、NMTコーパスの単語/トークンの出現率の特徴であるZipfian分布を緩和することはできない。これは、ロングテール理論の中心的な論文(Feldman、2020)によると、記憶(memorization)につながる。 同様に、無効な参照という形のノイズは、ウェブベースのコーパスが収集される規模によるものである。また、摂動下の幻覚と自然幻覚の両方が大規模なNMTシステムで広く報告されていることから、我々の知見は大規模なモデルにも直接適用できるはずである。
今回の研究が、NMTや他のsequence to sequenceモデルにおける幻覚の詳細な理解への有用な一歩となることを期待する。今後の研究の方向性としては、NMTの訓練における記憶やコーパスレベルのノイズパターンの影響を改善するための学習中心の修正方法を模索したいと思います。
今日の論文2023/05/13,14:A Distributional Lens for Multi-Aspect Controllable Text Generation
A Distributional Lens for Multi-Aspect Controllable Text Generation
©2022 Association for Computational Linguistics
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容に基づき筆者が要約または翻訳したものです。以下の図は、そこから引用しています。
This article is my summary or translation based on the content of the original publication. The following figures are taken from it.
要点まとめ
マルチアスペクト制御可能なテキスト生成は、シングルアスペクト制御に比べ、より困難で実用的な課題である。既存の手法は、シングルアスペクトから学習した複数のコントローラを融合させることで複雑なマルチアスペクト制御を実現しているが、これらのコントローラの相互干渉による属性退化に悩まされている。
そこで我々は、分布の観点から属性融合に関する考察を行い、複数の属性分布の共通領域を直接探索し、その組み合わせとして生成することを提案する。本手法では、まずオートエンコーダ構造で属性空間を推定する。その後、異なる属性を表す点への距離を共同で最小化することにより、反復的に共通領域にアプローチする。最後に、プレフィックスチューニングに基づくデコーダーで、属性に関連した文にマッピングする。
センチメント、トピック、デトックスの3つの側面からなる制御タスクの実験により、本方法が属性関連性とテキストの品質においていくつかの強力なベースラインを上回り、SOTAを達成することが明らかになった。また、さらなる分析により、本アプローチの有効性を説明する裏付けを得ることができた。
序論
制御可能なテキスト生成は、所望の属性を持つ流暢なテキストを生成することを目的とする自然言語生成の挑戦的なタスクである。パイロット研究では、条件モデルを直接ファインチューニングすることでシングルアスペクトの制御を試みたり(Ziegler et al., 2019; Keskaret al., 2019)、大規模な事前学習済み言語モデルのコストが高いため(Brownet al., 2020a; Zhang et al., 2022)、言語モデルを固定した手法に転換したり(Dathathri et al., 2020)している。
最近の研究では、より実用的な設定であるマルチアスペクト制御のテキスト生成に焦点が当てられており、既存のアプローチは主に次の3つの技術路線に分かれている:重み付きデコード(Dathathri et al., 2020、Krause et al., 2021)、多目的オプティマイゼーション(Clumar et al, 2021; Mireshghallah et al., 2022)、prefix-tuning(Qian et al., 2022)である。これらのアプローチは、単一のアスペクトから学習したコントローラを組み合わせて、固定された言語モデルに適用する方法を探求しているが、コントローラの相互干渉によって引き起こされる属性退化に苦しんでいる。
我々は、この問題を解決するために、分布的な視点を提供する。 現在のテキスト生成のパラダイムでは、言語モデルは、自然言語分布からのサンプリングに相当する訓練データを用いて、文に対する推定分布を形成する(Pillutla et al., 2021)。シングルアスペクト制御の場合、これらの手法は、属性ごとに分類器やPrefixを独立して学習し、属性に関連する文の分布の中心を評価し、言語モデルの分布がその中心に偏るようにするものと考えられている。 そのため、マルチアスペクト制御を行う場合、これらの融合戦略は、これらの中心の補間や平均を直接求めることになるが、これはあまりに単純である可能性がある。図1に示すように、補間点は確率空間において複数の中心を組み合わせた後に獲得した位置を示している。そして、その共通部分は、複数の属性を同時に満たすオラクル文が存在する位置を示している。図1の左側では、属性の分布が対称的である場合、確かに補間点は共通領域内にある。しかし、補間点と共通部分との間にはミスマッチがある可能性がある。例えば、図1右のように、2つの歪んだ分布が尾部で交わるため、補間点が共通領域から外れてしまい、希望する属性をまとめて表現することができなくなる。

本論文では、補間点を用いて共通領域を近似するのとは異なり、共通領域を直接取得する戦略を提案する。まず、属性に関連する文章を、推定属性空間を構成する潜在的な表現に対応付けるオートエンコーダ構造を導入する。この空間は、特別に設計した制約条件により、属性間の関係をモデル化することができる。 その後、すべての属性の分布の長い尾根を歩き回り、より緊密に結合する場所を反復的に見つけることができる効果的な共通部分探索アルゴリズムを提供する。最後に、探索された共通部分から文章を構成するために、プレフィックスチューニングに基づくデコーダを利用する。
IMDb movie reviews (Maas et al., 2011), AGNews (Zhang et al., 2015), Jigsaw Toxic CommentClassification Challenge Datasetで、それぞれセンチメント面から2属性、トピック面から4属性、解毒から1属性の3側面制御で実験する。各属性の関連性を個別に評価し、その平均値を最終的な関連性の指標として算出する。また、文章の質については、perplexityと、流暢さ(fluency)と多様性(diversity)に関する明確さ(distinctness)を評価する。 その結果、本手法は、多面的な制御において、強力なベースラインモデルを有意に上回ることができることが示された。さらに、解析実験により、直感的な仮定が我々の観測結果とよく一致することを発見した。主な成果は以下の通りである:
より実践的なマルチアスクペクト制御をモデル化する分布の視点を提案する。
属性空間の共通部分を直接探索し、目的の属性を持つ文章を生成する方法を提供する。
本手法は、強力なベースラインと比較して、マルチアスペクト制御の有効性を実験的に明らかにし、SOTAを達成した。
関連研究
変分オートエンコーダーは、初期の研究で制御可能なテキスト生成にしばしば使用され(Hu et al., 2017;Duan et al., 2020;Mai et al., 2020)、彼らはテキストの流暢性を改善するために多くの努力を費やしている。大規模な事前学習済み言語モデルの繁栄(Radford et al., 2019)は、ファインチューニング(Ficler and Goldberg, 2017; Ziegleret et al., 2019;Keskar et al., 2019)などの属性制御に対するより優れた方向を提供している。最近の研究では、シングルアスペクト制御(Krause et al., 021)について喜ばしい進展があり、以下の3つの主要なアプローチを含む、より困難な課題であるマルチアスペクト制御へと徐々に研究が移っている。
Weighted Decoding:言語モデルの規模が急速に拡大する中、重み付け復号化(Dathathri et al., 2020; Krause et al., 2021; Yangand Klein, 2021; Liu et al., 2021a; Gu et al., 2022) はシンプルかつ実用的な選択肢となる。 これは、属性に条件付けられた文の確率を、デコード時に言語モデルとベイズルールによる分類器に直接分解するフレームワークである。マルチアスペクト制御を扱う場合、分類器を相互補間することで容易に一般化できる(Lin and Riedl, 2021)。
Multi-Objective Optimization:制御可能なテキスト生成タスクは、その復号化プロセスを最適化目的とした場合、当然ながら多目的最適化問題となる。 DGC (Khalifa et al., 2020), Mix&Match (Mireshghallah et al., 2022), COLD Decoding (Qin et al., 2022) などのいくつかのアプローチは、複数の目的をブレンドするためにエネルギーベースモデル (LeCun et al., 2006) を採用している。また、MUCOCO(Kumaret al., 2021)は、マルチアスペクト制御の最適化目標を不等式制約に変換し、制約付き最適化問題にラグランジュ乗数法を適用している。
Prefix-Tuning:GPT-3(Brown et al., 2020b)は、プロンプトベース学習(Liu et al., 2021b)という新しいパラダイムを提供し、下流のタスクで数回に分けて学習を行うことができるようにする。 Prefix-Tuning(Li and Liang、2021)は、学習した軽量プロンプトを活用して、言語モデルの条件分岐機能を起動する。Prefix-Tuningをマルチアスペクト制御可能なテキスト生成に適用する(Yu et al., 2021; Qian et al., 2022; Carlssonet al., 2022; Yang et al., 2022)ことは、暗黙的にマルチオブジェクトに最適化するとみなすことができる。
手法
本節では、まず本手法の動機と全体的な流れを紹介し、その後、各モジュールを詳細に説明する。
概要
図2に示すように、本手法は、属性空間の推定、共通部分の検索、共通部分の文へのマッピングなど、主に属性空間を中心に展開される。

まず、サンプリングされた文章から属性空間を構築し、実空間をできるだけ正確に推定することを目指す。推定された属性空間を構成する点を潜在表現とするオートエンコーダ構造を採用する。推定された空間が、属性の確率分布や異なる属性間の関係など、属性を確実にモデル化することを保証するために、表現にさらに3つの制約を加える。(1) Reconstruction Loss は、属性空間上の点と本来の属性関連文とのギャップを埋めることを目的としており、コンテンツに反映された属性を回復することを目的とする。(2) Attribute Classification Loss
は、同じアスペクトから異なるアスペクトのポイントを区別することで、エンコーダーがよりアスペクトを把握することに注力する。(3)Aspect Gap Loss
は、異なるアスペクトのデータソース間のドメインギャップによって引き起こされるアスペクトの不一致を評価する。特徴アライメント(Pan et al, 2010)に触発され、各二つのアスペクトの分布中心間の距離を最小化する。
第2段階は、希望する属性の共通領域を探索することを目的とする。交差領域が存在する場合、その領域内の点は、周囲の小さな領域に現れる近傍点を満たし、必要な属性をすべてカバーするはずである。この近傍思想に触発され、これらの属性がより緊密に結合する領域に反復的に近づくアルゴリズムを設計する。第3のステップは、検索された共通部分をPrefixにマッピングし、言語モデルを活性化させて属性に関連する文章を生成する。言語モデルがわずかな変化に影響されにくくするために、多変量ガウス分布から摂動ベクトルをサンプリングする。
属性空間の推定
与えられた個の観点
がそれぞれ
個の属性
を含んでいるとする。ここで、
は訓練データ中の全ての属性
を持つ文章の識別子を表すインデックス集合である。我々は
、
となるようにする。ここで
は観点
における任意の属性を持つ全ての文章のインデックスであり、
は全訓練データのインデックスである。我々は全ての観点
からの文章
を、統一されたマッピングパラメータ
を使って表現
にエンコードする。ここで
である。
再構築損失:図2の上部に示されているように、再構築損失
は、事前訓練された言語モデル
の自己回帰損失と同じ方法で計算される。
ここで、
である。
ここでのは全訓練データセットからのサンプル文章で、すなわち
である。また、スケーリングファクター
を持つ
は、再構築時の頑健性のために多変量ガウス分布
からサンプルされた摂動ベクトルである。多層パーセプトロン
は摂動した
を言語モデルを活性化させ、望ましい属性を持つテキストを生成することができる
にマップする。我々の主な目標は属性の回復であるため、
はあまりよく収束しないようにしながらもテキストの流暢さを維持することが好ましいということに注意する価値がある。
属性分類損失:我々はエンコーダーが属性に焦点を当てるように、以下の方法で
を強制する。
与えられた文章の表現に対して、はパラメータ
を持つ分類器で、観点
から属性
を区別する。
観点ギャップ損失:我々は、分布中心間の不一致を罰するようにする:
これらは、全ての異なる分布中心間のユークリッド距離である。観点の大規模なスケールへの一般化の際には、モデルが更新されるたびに全データセット上で平均を計算することが比較的高コストとなる。我々はこの損失を実践的にバッチレベルの近似を用いて計算する。各観点にはメモリユニットが割り当てられ、その観点の推定中心の最新の表現を保存する。一つの観点からの文章のバッチを処理するたびに、その表現の平均を中心とみなし、メモリ内の他の観点の中心へのユークリッド距離を合計する。これが推定されたである。次に、この観点のメモリユニットを最新のものに更新する。
訓練段階では、我々の損失関数は次のようになる:
我々はエンコーダ、MLP層、および分類器ヘッドのためのパラメータのみを更新するということに注意する価値がある。
属性の共通部分
あるN個の異なる観点からの属性の共通部分内に共有点が存在すると仮定し、その点を
と表記する。ここで、
は観点
における
番目の属性を表す。我々のアルゴリズム1は、異なる属性からの最近傍を用いて最もバランスの取れた点に反復的に近づくことで、
を近似する。まず、候補
を属性空間でランダムにサンプリングした点で初期化し、それぞれの属性
の最も近い点までの距離を計算する。その後、全ての属性に対する平均距離が最も小さい上位
サンプルを選択する。各イテレーションでは、我々は各属性について
に最も近い上位
の点を選択し、これらの点の重み付き平均を用いて
を更新する。ここで、
は属性をバランス良く扱うため、または特定の属性を優遇するために使用される重みであり、
の負の値は特定の属性から離れることさえ可能であることに注意が必要である。最後に、我々は最後のイテレーション
から最良の候補を選択する。これは、共通領域、すなわち、複数の属性に関連する表現内に存在することが期待される。
共通部分を用いた生成
図2の右下に示されているように、我々は交差領域から得られた表現を直接
を用いてPrefixに変換し、言語モデルに入力
から多属性の文
を生成させる。
一つの属性組み合わせに対して複数の属性関連の文を生成する場合、その共通部分を一度だけ計算すればよい。

実験
ここでは、「感情」「話題」「無害化」の3つの側面から制御することで、本手法の有効性を実証する。
マルチアスペクト制御タスク
使用するデータセットは、GeDi (Krauseet al., 2021) とContrastive Prefix (Qian et al.,2022) と同じである。 全ての属性でデータ規模のバランスを取るために、GeDiが使用するサンプル数より少ない各データセットから10k文をランダムにサンプリングし、各属性がこの量を均等に分割している。 センチメント、トピック、デトックスについては、それぞれIMDb movie reviews (Maaset al., 2011)、AGNews dataset (Zhang et al.,2015) 、Jigsaw Toxic Comment Classifica-tion Challenge Dataset5を使用する。
テキスト生成に用いるプロンプトは、PPLM (Dathathri et al., 2020) で用いたものと同じであり、単語袋実験から20個、識別器実験から15個を用いている。3つのアスペクトの8つの組み合わせと2つの感情×4つのトピック×1つの解毒で実験し、各組み合わせと各プロンプトに対して5つのコンプリートを生成する。 合計で35×2×4×1×5=1400文の文章が生成されることになる。なお、言語モデルに有毒な文章を生成させるようなプロンプトは特に使用していないため、無害化を容易に改善することができる。
異なる側面に対する性能を測定するために、属性の関連性を計算する。Yelp dataset(Zhang et al., 2015)でDeBERTa (He et al., 2021b,a)分類器を感情側面について、トピック分類器を学習中に使われなかった全ての残存データを利用して、ファインチューンを行う。Google Perspective APIで毒性がないことを評価する。モデルの最終的な性能は、上記で紹介した3つの属性関連性スコアの平均値で決定される。また、テキストの品質を測定するために2つの補助的な指標を使用する。一つは、Contrastive Prefix(Qian et al., 2022)に従ってGPT2-largeによって計算されるperplexityである。また、異なるPrefixの変化にモデルが影響されないように、異なるPrefixから生成された文のDistinctness (Li et al., 2016)を計算し、1-gram。2-gram。3-grams distinct scoreを平均してsimplicityとしている。 さらに、異なるモデルshuffledによって生成された文章で人間による評価を行う。 各文章は3人の専門家評価者によって、3つの属性の関連性とテキストの流暢さについて評価される。評価者は各項目を1〜5で評価し、5は属性との関連性が高い、または非常に流暢な文章を表す。
ベースライン
(1) Weighted Decoding: PPLM(Dathathri et al.,2020)は、学習済み分類器からバックプロパゲートされた勾配で言語モデルのバイアスをかける。GeDi(Krause et al., 2021)は、属性に条件付けられたトークン確率で復号化プロセスに影響する。(2) Multi-objective Optimization:MU-COCO(Kumar et al., 2021)は、デコード処理を、言語モデルが目的関数、属性が制約となる最適化問題として捉えている。Mix&Match(Mireshghallah et al., 2022)は、エネルギーベースモデルで属性を制御し、マスキング、サンプリング、補正により文章を生成する。 (3) Prefix–Tuning:Contrastive Prefix(Qian et al., 2022)は、prefixを利用して言語モデルを活性化し、連結や半教師による属性関連文の生成を行う。
結果
表1の自動評価結果に基づき、多面的な設定のもと、手法の種類に基づきモデルを時系列にグループ化した。 また、異なる属性の組み合わせにおけるモデルの安定性を反映する標準偏差を示した。

重み付け復号化において、GeDiはPPLMよりも強力な分類器を用い、属性の関連性、異なる組み合わせに対する安定性、識別性において優れた性能を示すが、その反面、perplexityにおいては劣る。多目的最適化手法では、属性の関連性については良好な結果が得られたが、MUCOCOは、その非自己回帰的なパラダイムがゼロからの生成に適していないため、perplexityについては爆発的に悪化してしまった。半教師付きContrastive Prefixの性能は、多様性の欠如を除いて、GeDiと同様である。
本手法は、属性に関連する平均的な指標において、既存のベースラインと比較して少なくとも7.3%の有意な改善を示し、最高の性能を発揮しした。我々の進歩は主にセンチメントとトピックの側面からもたらされ、それぞれ13.9%と10.3%を下回ることはなかった。我々のモデルは無害化(detoxification)に関してはベストではないが、平均で最も低い標準偏差10.9により、最もバランスが良く安定している。流暢な文章を得意とする言語モデルを直接修正することなく導入するPrefixチューニングベースの手法であるため、perplexityにおいて高い性能を発揮し、多様性においてもその性能を受け継いでいる。
さらに、アスペクトギャップ損失と属性分類損失
を分離して評価する。一方、
がないと、異なる学習データセットの偏りを緩和することができず、交差領域の探索が困難になる。また、属性空間における異なるアスペクトのサンプルポイント間の距離が長くなると、我々のモデルはより疎な領域からマッピングされた文章を生成することになり、流動性についてはわずかに低下し、多様性についてはわずかに増加することになる。一方、
がない場合、属性空間は完全に崩壊する。これは、モデルが同じアスペクトの異なる属性の表現をほとんど区別できず、比較的楽な解毒に集中するためである。さらに悪いことに、明確な表現がないため、モデルは類似の文章から異なる文章を復元する必要があり、学習時に振動が生じ、推論時に完全な文章を生成することができない。
人間による評価結果は表2のとおりで、注釈者内一致度はFleiss'κで0.36であった。GeDi、Contrastive Prefix、および我々の方法を評価した結果、センチメントとトピック関連性において自動評価と一致することが確認された。無害化に関するモデルの性能は高く、比較的類似しているため、自動的な結果は、アノテーターが我々のモデルがベースラインよりも良い仕事をすると信じている手動的な結果とは異なる。perplexityは比較的信頼性が低いため、手動で測定されたGeDiの流暢さはContrastivePrefixの流暢さよりもはるかに優れている。そして、我々の方法は最も優れた流暢性を達成した。

分析
さまざまな属性とその組み合わせの効果
各属性およびその組み合わせの詳細な結果を表3に示す。GeDiとPrefix-tuningはシングルアスペクトコントロールにおいて異なる性能を発揮し、それぞれに長所がある。 例えば、GeDiは93.9%のレリバンスでネガティブに特化しており、Prefix-tuningは90.6%のレリバンスでポジティブを得意としている。マルチパースペクティブコントロールを行う場合、平均関連度はそれぞれ91.1%、79.1%となり、このようなアンバランスな特性を受け継いでいる。また、ベースラインはシングルアスペクトと比較して、各属性の平均関連度が0.7~33.0と、相応に低下している。平均して、我々のモデルは、属性メトリクスにおいて他のベースラインを上回った(表1)。詳細には、我々のモデルは、プレフィックスチューニングに基づく別のモデルであるContrastive Prefixと比較して、ほとんどの属性で競争力のある性能を発揮している。特に、ビジネスや科学技術といった属性において、我々のモデルは、マルチアスペクト制御において、プレフィックスチューニングに基づく別の手法を大幅に改善し、シングルアスペクト制御においては、それを上回ることさえ可能である。

また、属性間の相関は、表3のように大きく変化している。例えば、一般的にポジティブは無毒と相性が良いが、ネガティブは無毒が大きく低下する。これは、人を褒めることと怒らせることは同時にできない、という直感と一致する。また、世界やビジネスのニュースは、戦争、飢餓、インフレなどネガティブに報道されることが多く、ポジティブと組み合わせるのは困難である。属性が密接に相関していない場合、つまり、これらの属性を併せ持つ自然文が少ない場合、本手法はそのような稀な出来事を捉え、その頻度を拡大する可能性が高くなる。ビジネスを例にとると GeDiは75.7、Prefixは93.5と、ビジネスに対するシングルアスペクト制御を行うことで、細かい属性関連性を実現することが容易にできる。しかし、ビジネスに対してポジティブを付与した場合、ベースラインモデルはその相関性の弱さから、GeDiが54.3、Contrastive Prefixが41.7に低下してしまう。これに対し、本手法では、学習文に含まれるこの異常な共起を属性空間から回収することでこの問題を緩和し、単一アスペクト制御に近い91.7という性能を達成することができる。また、比較的よく使われるビジネスとネガティブを組み合わせた場合、ベースラインモデルではまだ若干の低下が見られる。一方、本手法は96.7とシングルアスペクト制御を上回る性能を得ることができる。
推定される属性空間
図3では、センチメントとトピックの側面から、ポジティブ、ネガティブ、スポーツ、科学/技術の4つの属性を推定し、属性空間の一部を示している。 この高次元空間を主成分分析(PCA)により2次元に投影したところ、我々の仮説と同様に、スポーツと科学/技術の分布は非対称であり、共通部分は属性の分布の疎なエッジにあることがわかった。さらに、ベースラインの戦略と我々の戦略で探索された共通部分をそれぞれ投影した。ポジティブ-科学/技術ペア、ネガティブ-科学/技術ペアの場合、組み合わせは比較的タイトであり、共通部分を見つけるのは容易である。しかし、ポジティブ-スポーツペアとネガティブ-スポーツペアの共通部分はかなりまばらである。拡大図に示すように、ベースラインで探索された共通部分は2つの分布中心の中間点であるが、この位置は属性が交差している場所ではない。 逆に、本手法はこのような疎な領域で共通部分を見つけることができ、その周囲のわずかな領域に2つの異なる属性の様々な点を同時に出現させることができる。なお、この投影でpositiveとnegativeが接しているように見えるのは、高次元空間で近いからで、実際には、この2つの属性をA.3に投影しただけでは、共通部分は存在しない。

 の効果
の効果
の変化を共通部分探索アルゴリズムで解析し、その結果を表4に示す。我々のモデルは、
が200のときに臨界点に達し、このとき最適な性能を発揮する。一方、
の値が徐々に増加するにつれて、我々の方法は、サンプルが少ない一方で属性がより緊密に組み合わされる領域に注意を払わなくなり、性能はそれに伴って低下する。
が5kに達したとき、本手法は共通部分を分布中心の中点として扱うプレーンなプレフィックスチューニングモデルに堕落する。その性能は表1のContrastive Prefixの連結版と似ているが若干劣る。 一方、
が小さいと、ノイズの影響が学習データで無視できなくなるため、最適とはいえない性能になる。
が10より小さい場合、モデルは非常に不安定になる。

属性分布
各属性が独立に投影されたPCAにより、サンプルポイントを2次元に投影する。図4に示すように、Worldの散布図を表示し、ガウスカーネル密度推定を行い、確率分布を可視化する。濃い部分は確率が高いことを示し、オラクル文の表現点が多く集まる場所であることがわかる。また、赤い楕円で示された領域が推定された分布の中心である。 プロットのように、Worldの分布は、上部に中心があり、下部は疎な尾を引くように、大きく非対称である。さらに、分布は非凸で、右下隅に孤立したクラスターがある。 この観察結果は、属性の実用的な分布は、ガウス分布のような対称的な分布よりもはるかに複雑であるという我々の仮説を裏付けるものである。さらに、他の属性の分布もA.1.にプロットした。

ディストリビューションレンズに関する議論
DGC (Khalifa et al., 2020)のようなパイロット的な研究は、エネルギーベースのモデルで言語分布を推定し、制約の多様性にアプローチして制約を満たすようにこの分布を最適化する。COLD Decoding (Qin et al., 2022)やMuCoLa (Kumaret al., 2022)のような最近の分布アプローチは、言語と属性分布を同じ空間で捉え、属性関連の文をLangevin Dynamicsでサンプリングするようにしている。画像側の同時進行研究であるPromptGen (Wu et al., 2022)は、深層再生モデルを用いて、ターゲット属性に関連する画像の複雑な分布をシミュレートする。 しかし、多様体学習の常識として、学習済みの言語モデルは、高次元の埋め込み空間に低次元の言語の多様体を推定するため、埋め込み空間内のほとんどの点は言語モデルによって確率的にモデル化されていないことになる。 言語モデルの分布モデル化能力を過信することは、良い選択とは言えないと我々は考えている。 本手法では、属性空間を属性文の離散的なサンプル点で表現し、これらの離散的な点とそのカバー領域を推定分布のサポートセットとすることを試みている。
結論
本研究では、マルチアスペクト制御可能なテキスト生成のための分布的視点を提示し、実験結果により、本モデルの優位性が確認された。 さらに、推定された属性空間の2次元投影を観察した結果、属性空間に関する我々の仮説がより実現可能であることが示された。将来的には、よりきめ細かい制御を行うために、異なる属性の組み合わせの相関関係を調べたり、バイアスを除去または利用するためにデータセットに取り込んだりすることが可能である。
制限事項
本手法は、属性空間を推定する必要があるため、データへの依存性がある。そのため、本手法は数ショット学習ではうまく機能しにくい。しかし、この欠点は、スタイル変換のタスクでは比較的十分なシングルアスペクトのデータしか必要としないため、それほど深刻ではない。 また、本手法のデータ依存性は、データの偏りにやや敏感であることである。学習データの異なるアスペクトの意味的乖離が大きすぎる場合、各アスペクトの分布の距離を縮めることを目的としたアスペクトギャップ損失は、文再構成損失と衝突する。 また、アスペクトギャップ損失は各アスペクトのバッチレベルの推定を利用しているため、計算資源もこのアプローチに影響を与える。したがって、バッチサイズが大きければ大きいほど、より正確な近似推定ができ、属性空間に偏りが少なくなる。バッチサイズが小さい場合の代替戦略は、十分な分布サンプルを蓄積した後に損失をバックプロパゲートすることだが、これはより多くの学習エポックを要する。
今日の論文2023/05/11, 12:AttentionViz: A Global View of Transformer Attention
AttentionViz: A Global View of Transformer Attention
Yeh, Catherine, Yida Chen, Aoyu Wu, Cynthia Chen, Fernanda Viégas, and Martin Wattenberg. "AttentionViz: A Global View of Transformer Attention." arXiv preprint arXiv:2305.03210 (2023).
©2023 The Authors
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容に基づき筆者が要約または翻訳したものです。以下の図は、そこから引用しています。
This article is my summary or translation based on the content of the original publication. The following figures are taken from it.
要点まとめ
トランスフォーマーモデルは、機械学習に革命をもたらしているが、その内部構造は謎に包まれている。本研究では、トランスフォーマーモデルが系列の要素間の豊かで文脈的な関係を学習することを可能にする、トランスフォーマーのセルフアテンションメカニズムを研究者が理解できるように設計された新しい可視化手法を紹介する。本手法の主なアイデアは、トランスフォーマーモデルがアテンションを計算するために使用するクエリベクトルとキーベクトルの結合埋め込みを可視化することである。従来のアテンションの可視化手法とは異なり、本手法は、複数の入力シーケンスにまたがるグローバルなパターンの分析を可能にする。このクエリーとキーの埋め込みに基づくインタラクティブな可視化ツールAttentionViz (demo:http://attentionviz.com) を作成し、言語と視覚の両方の変換器におけるアテンションのメカニズムを研究するために使用する。我々は、いくつかの応用シナリオと専門家のフィードバックを通じて、モデル理解の向上とクエリキー相互作用に関する新しい洞察を提供する上で、我々のアプローチの有用性を実証する。
1. INTRODUCTION
トランスフォーマーニューラルネットワークアーキテクチャ[45]は、自然言語処理(NLP)[11, 35]からコンピュータビジョン[12]までの分野で大きな影響を及ぼしている。実際、トランスフォーマーは現在、数億人が利用する大規模な実世界システムに導入されている(例:Stable Diffusion、ChatGPT、Microsoft Copilotなど)。しかし、この成功の背後にあるメカニズムは、特にモデルの複雑さとサイズが大きくなるにつれて新しい機能が出現し続けるため、いくらか謎のままである[9, 53]。トランスフォーマーのモデルをより深く理解することで、より信頼性の高いシステムを構築し、問題を解決し、改善策を提案することができる。
本研究では、トランスフォーマーの動作をより深く理解することを目的とした新しい可視化技術について説明する。 (第2項では、トランスフォーマーについて簡単に紹介する。私たちの分析対象は、これらのモデルが要素間の豊かな関係を学習し利用することを可能にする、特徴的なトランスフォーマーセルフアテンションメカニズムである。アテンションパターンの研究は盛んに行われているが、従来の技術では、一度に一つの入力シーケンス(例えば、一つの文章や画像)に関連する情報を可視化するのが一般的であった。典型的なアプローチは、与えられた入力シーケンスに対するアテンションの重みを二分割グラフ [44, 46] またはヒートマップ [15, 25] で表現するものである。
本手法は、多くの入力シーケンスのセルフアテンションパターンを一度に見ることができる、より高度な視点を提供する。このアプローチは、Activation Atlas [4]のようなツールの成功からヒントを得ている。このツールでは、研究者は「ズームアウト」してニューラルネットワークの概要を確認し、詳細については深堀することができる。我々は、トランスフォーマーの様々なアテンションヘッドがどのように動作するかを研究者に提供することができる、一種の"attention atlas"を構築することを目指す。主な新技法は、トランスフォーマーが使用するクエリーベクトルとキーベクトルの結合埋め込みを視覚化し、個々のアテンションヘッドのビジュアルサインを作成することである。
この技術を説明するために、言語と視覚の両方のトランスフォーマーを使ってアテンションを探ることができるインタラクティブ可視化ツールであるAttentionVizを実装した。 AttentionVizは、一度にすべてのアテンションヘッドを見ることができるグローバルビューと、単一のアテンションヘッドまたは入力シーケンスの詳細をズームインする機能の両方を提供し、複数の詳細レベルを通じて探索を行うことができる(図1)。

AttentionVizとドメインの専門家へのインタビューによるいくつかの応用シナリオを通じて、本技術の有用性を実証する。 具体的には、広く使われているトランスフォーマーであるBERT [11]、GPT-2 [34]、および ViT [12]について、可視化によって明らかにできることに焦点を当てる。 BERTのアテンションパターンに関連するいくつかの識別可能な「視覚的痕跡」を発見し、ViTの視覚的アテンションメカニズムにおける新しい色相/周波数動作を検出し、GPT-2の異常となりうる動作を発見する。また、ユーザーからのフィードバックにより、本アプローチは、他の埋め込みをスケールアップして可視化することが可能であることが確認された。
要約すると、この研究の貢献は以下の通りである。
共同クエリキー埋め込みに基づくトランスフォーマーモデルの注目度傾向を探る可視化技術。
視覚と言語変換におけるセルフアテンションを研究するための我々の技術を、複数のスケールで応用したインタラクティブツールである、AttentionViz。
Atten-tionVizがトランスフォーマーのアテンションパターンに関する洞察をどのように明らかにするかを示すアプリケーションシナリオと専門家によるフィードバック。
2. BACKGROUND ON TRANSFORMER MODEL
[45]で紹介されたトランスフォーマーは、連続した入力で動作するように設計されたニューラルネットワークアーキテクチャである。トランスフォーマーの完全な説明は本稿の範囲外であるが、いくつかのコンセプトは我々の研究を理解する上で重要である。 まず、トランスフォーマーは、ベクトル(しばしば埋め込みと呼ばれる)の集合を入力として受け取る。埋め込みは、さまざまな入力タイプを表すことができる。テキストベースの変換器では、単語や単語の一部に対応し、ViTでは、ピクセルのパッチをエンコードする。
ネットワークは、これらのベクトルを一連のアテンション層を介して繰り返し変換し、各アテンション層は、埋め込みのペア間で情報を移動させる。「アテンション」という名前は、すべての埋め込みが同じように関連しているわけではなく、特定のペアがより強く相互作用する、つまり、より「注意」し合うことを示唆している。アテンションレイヤーは、どのペアが相互作用し、どのような情報を流すかを決定する。
例えば、“The brown capybara is sleeping now,” という文の単語を対象としたトランスフォーマーでは、 “capybara”と “is,”の埋め込みの間には高い注意(と情報の流れ)が期待できるが、 “brown”と “now.”の埋め込みの間には期待できないかもしれない。このセルフアテンション機構により、トランスフォーマーはシーケンスの要素間の豊富な関係セットを学習して使用することができ、様々なNLPやコンピュータビジョンのタスクにおいて、大幅な性能向上を実現している [11, 12, 34] 。
ペアを埋め込む理由は様々である。例えば、この例文では、"brown "と "capybara "は形容詞-名詞関係で結ばれ、"capybara "と "is "は主語-動詞関係である。このように、複数の関係タイプを許容するために、トランスフォーマーのアテンション層は複数のアテンションヘッドで構成され、それぞれが異なる注意と情報の流れのパターンを表現することができる。
各アテンションヘッドは、クエリ重み行列とキー重み行列
から計算される2つの線形形式を使用して、自身のアテンションパターンを計算する。具体的には、2つの埋め込みベクトル
と
に対して、アテンション
はクエリーベクトル
とキーベクトル
の内積で決定される。
の次元を
とすると、次のようになる。
埋め込みベクトルが与えられたとき,ソフトマックス関数を使って
と他のベクトルの間のアテンションを計算する。
この式は、クエリベクトルとキーベクトルの間の内積が大きいほど、最終的な注目値が高くなることを示しており、この事実を私たちは共同埋込みの可視化で利用している。
トランスフォーマーアーキテクチャには、ここで説明した以上のものがある。特に、我々は埋め込みのペアの間の注目の重み付けを説明しただけで、それらの間を流れる特定の情報については説明していない。(後述するように、これはさらなる研究が必要な分野である)しかし、最後の技術的なポイントは、この論文の後半で画像を解釈するのに役立つので、言及する価値がある。トランスフォーマーに与えられる最初の埋め込みは、通常、その順序(1次元配列の場合)または空間構成(ViTのようなグリッドの場合)のベクトル表現が組み込まれている。シーケンスの場合、これらの位置ベクトルは三角関数を用いて定義され、高次元空間の螺旋状の曲線上に位置する([45]を参照)。
2.1 Models Studied in this Paper
我々は、BERT(言語)、GPT-2(言語)、ViT(視覚)の3つのトランスフォーマーモデルを研究する。BERTは、Bidirectional Encoder Representations from Transformers [11]と呼ばれる多層トランスフォーマーである。 GPT-2 (Generative Pre-trainedTransformer 2) [35]は、多層トランスフォーマーデコーダーである。ViT(ヴィジョントランスフォーマー)[12]は、画像を「パッチ」に分割し、それらを文中のトークンに見立てたセルフアテンションベースのトランスフォーマーアーキテクチャを採用するものである。 BERTと同様に、ViTは多層で二重構造のトランスフォーマーエンコーダである。この研究では、16x16(ViT-16)と32x32(ViT-32)のパッチサイズにおけるViTの性能について調べる。
3. RELATED WORK
多くの研究者が、トランスフォーマーの内部動作を調査することを試みている。 [7, 29]は、学習された言語表現を探求することで、トランスフォーマーベースの言語モデルによる性能向上を理解しようとしている。また[42]では、BERT が品詞タグ付けから関係分類に至る自然言語解析の古典的なステップを再現していることが確認されている。トランスフォーマーのバックボーンであるアテンションもまた、集中的に研究されている。例えば、アテンションは、自然言語処理システムの構文構造 [8, 50] やViTのゲシュタルト的なグループ化 [28] と関連しているようである。また、ViTの視覚的アテンション機構を畳み込みフィルタと比較したところ、アテンションは、画像の隠蔽、破損、高周波ノイズに対してより頑健であることがわかった[30, 33]。関連研究の議論では、トランスフォーマーのアテンションを研究するための視覚的アプローチに焦点を当てる。
3.1 Visualizing Attention in a Single Input Sequence
アテンションパターンは、言語と視覚の両方のトランスフォーマーにおいて、自然に視覚化されます[10, 16, 26, 32]。 これらの可視化は、二分木グラフ([25,40,44,46]など)やヒートマップ([1, 15, 17, 20, 25, 36]など)を用いて、単一の入力シーケンスのクエリとキートークン間のアテンションを可視化することに主に焦点を当てている。
複数のモデルやレイヤーを横断して比較できるような可視化もいくつか提案されている。例えば、Attention Flows [10]は、BERTの層内および層間のアテンションの比較や、1つの文章を与えられたアテンションヘッド間の比較をサポートする。Dodrio [52]は、単一の入力に適用されるグリッドビューを使用しており、アテンションヘッドの直接比較を可能にする。 また、VisQA [16]では、言語セルフアテンション、視覚セルフアテンション、言語-視覚クロスアテンションのヒートマップを表示することにより、視覚質問応答タスクの異なるヘッドにおけるアテンションを可視化している。しかし、これらのモデル比較システムにおいても、分析者は、与えられたアテンションヘッドに対するパターンを特定し検証するために、一度に異なる入力を見る必要がある。
3.2 Beyond Single Inputs: Visualizing Embeddings andActivation Maximization
複数の入力にまたがって保持されるパターンを求めるのは自然なことである。この目的のために有効であることが証明された技術の1つは、複数の入力シーケンスからの埋め込みベクトルの集合を可視化することである [3, 14, 39, 51].例えば、[36]は、多くの異なる文脈で使用される同じ単語のBERT埋め込みを視覚化し、語義に対応するクラスターを発見した。 また、構文処理の研究において、[7]は、BERT埋め込みを可視化した。 多言語BERTモデルからの埋め込みは、解釈の助けとなる有意義なクラスターを再び発見した。LMFingerprints[38]は、異なる言語モデル間で埋め込みベクトルを比較するために、ツリーベースの放射状レイアウトを使用している。
もう一つの手法は、[13, 54]でViTに用いられているもので、特定のユニットの活性度を最大化する画像を見つけることを目的としている。埋め込みベクトルに適用した場合、この手法は明確に解釈可能な結果を得ることができる。しかし、著者らは、クエリベクトルやキーベクトルに適用した場合、このテクニックは有用な結果をもたらさないようだと述べている。
3.3 Gaps in the Literature
既存の文献には3つのギャップがあり、それが私たちの研究の動機となっている。
一つ目に、埋め込みベクトルの可視化は、複数の入力にまたがるパターンを分析するための効果的な手法であることが示されているが、トランスフォーマーモデルにおけるクエリとキーの埋め込みを可視化するための体系的な試みは知られていない。また、[5]は、クエリやキーのようなセルフアテンションの中間成果物が未解明であると論じている。これらの観察から、我々のクエリキー埋め込み技術の動機付けがなされた。
第二に、複数の埋め込みを比較する可視化技術が提案されているが(例えば、[2, 3, 21])、これらの方法はしばしばいくつかの埋め込みに限定され、異なるトランスフォーマーヘッドやレイヤーでの埋め込みを比較するという我々のニーズに対応できない。そこで、クエリキー埋め込みを大規模に可視化するために、グローバルマトリクスビューをデザインした。
最後に、二部グラフ表現は、NLPベースのトランスフォーマーの分析に役立つことが証明されているが、視覚タスクに適用されるのを見たことがない。 我々は、ViTにおける画像のアテンションパターンを研究するために、二部式グラフの可視化を作成することで、この方向を探る。
4. GOALS & TASKS
本研究の包括的な目的は、トランスフォーマーモデルにおけるグローバルなアテンションの傾向を探索することができる新しい可視化技術を設計することである。このアイデアに関する初期フィードバックを収集し、ユーザーのニーズについてより詳しく知るために、モデルの解釈可能性に関心を持つ5人の機械学習(ML)研究者(4人の博士課程学生、1人の教授)と話をした。この個別インタビューの中で、専門家に、トランスフォーマーを扱う際の現在の実践と課題、およびアテンションの可視化が研究目的の助けとなる方法について説明してもった。これらの専門家をE1-5と呼ぶことにする。
全体として、専門家は、アテンション探索における使いやすさと簡便性の必要性を強調している。E2が要約したように、「既存の可視化ツールの多くは、学習して使用するには大変すぎる」。E5は、トランスフォーマーのアテンションを調査するためにカスタムコードを書かなければならないことが多く、これは困難で時間のかかる作業であると述べている。
4.1 Goals
最終的に、専門家の方々との対話の中で、3つの大きな目標を得ることができた。
G1 セルフアテンションがどのようにモデルの振る舞いに反映されるかを理解する。全体として、5人の専門家全員が、異なるアテンションヘッドの挙動や、トランスフォーマーモデルがその特徴的なセルフアテンションメカニズムを通じて何を学んでいるのかをよりよく理解したいと考えていました。そのため、「アテンションパターンを素早く簡単に探せるようにしたい」という要望がありました。E2は、「アテンションはまだかなりクローズドボックスで、謎が多い」と説明し、トランスフォーマーのアテンションパターンを深く理解することで、例えば「大規模言語モデルが推論タスクや数学で失敗する理由」についての洞察を得ることができると述べた。
G2 4.2 アテンションヘッドを比較・対照する。E5は、アテンションヘッドの違いを視覚化することで、研究プロセスの最初のステップである仮説生成に役立つと述べている: 「視覚化することで、検証すべき仮説を立てたり、トランスフォーマーが何をしているのか直感的に理解することができる」。さらに、3人の専門家(E1、E2、E5)は、アテンションヘッドの比較は、モデルの刈り込み(pruning)や編集の目的で有用であると指摘した。 つまり、2つのアテンションヘッドが似たような動きをするように見える場合、モデルの性能に大きな影響を与えることなく、1つを削除することができるかもしれない。E1の言葉を借りれば、アテンションヘッドを比較することで、"実際に有用なモデルの部分を見つける "ことができるかもしれない。
G3 アテンションの異常を特定する。4人の研究者(E2-5)は、アテンションパターンの探索を通じて、トランスフォーマーの不規則性や潜在的な行動上の問題を特定することを目的としていた。この情報は、モデルのデバッグに利用することができる。例えば、E4は「アテンションを可視化することで、たとえ結果が正しくても、モデルが間違ったものを見ていることに気づくことができる。」と述べている。E3はこれに同意し、特にモデルトレーニングの文脈におけるデバッグの重要性を繰り返し述べている。「トレーニングはしばしば失敗して死ぬが、なぜ失敗したり予想外の動作をしたりするのかを理解するのは難しい」。
4.2 Tasks
これらの目標に基づき、我々は次のようなデザイン課題を設定した。
T1 アテンションヘッドをスケールで可視化する。モデル行動を素早く探索し[G1]、アテンションパターンを簡単に比較対照できるようにする[G2]ため、本ツールはトランスフォーマー層間のセルフアテンションヘッドを同時に可視化する。
T2 クエリキーのインタラクションを探索する。 E1とE4は、トランスフォーマーのセルるアテンションの理解を深めるために、クエリーとキーのペアリング情報をより理解したいという要望を述べている。 そこで、本ツールでは、クエリキーの相互作用を可視化することで、アテンションパターンの比較[G2]と異常の検出[G3]をさらにサポートする。
T3 複数のレベルでアテンションを探る本ツールは、文・画像、ヘッド、モデルのレベルで可視化を行うことにより、アテンションの局所および全体的な比較[G2]を可能にする。また、1つのインターフェースで複数のビューを切り替えられる柔軟性は、知識発見[G1]を促進し、ユーザーがモデルの不規則性を識別するのに役立つ[G3]。
T4 モデルとデータ入力のカスタマイズAttentionVizは新しいトランスフォーマーやデータセットに簡単に拡張でき、異なるモデルやモダリティ(言語と視覚)間でアテンションパターンを素早く視覚的に比較し[G2]統合する[G1]ことが可能である。
5. QUERY/KEY EMBEDDINGS & DESIGN OF ATTENTION VIZ
このような目標や課題に対処するために、我々はAttentionVizと呼ばれるツールを構築した。このツールで使用される主な技術は、各アテンションヘッドに対するクエリーベクトルとキーベクトルの結合埋め込みを視覚化することである。 このセクションでは、まず、このテクニックの基礎となる動機と数学について説明し、次に、完全なアプリケーションの設計について説明する。
5.1 Visualizing Query/Key Embeddings
AttentionVizの背後にある技術は比較的簡単ですが、以下に説明するように、効果的であるために2つの数学的トリックを必要とする。各トランスフォーマーアテンションヘッドは、行列と
をそれぞれ適用することによって、入力埋め込みをクエリーベクトルとキーベクトルに変換することを思い出してほしい(第2項)。これらの行列は、元のベクトル埋め込みを低次元空間に投影し、本質的に高次元のベクトル埋め込みから特定の種類の情報を選択する。したがって、クエリベクトルとキーベクトルを検査することで、
と
によって選択される情報を学習することが期待できる。
アテンション係数はクエリとキーの間のドット積に依存するため、クエリベクトルとキーベクトルの相対的な位置が、どのようにアテンションが分配されるかを知る手がかりになるというのが、中心的な観察である。なぜかというと、クエリーベクトルとキーベクトルが常に同じノルムを持つという仮想的な状況を考えてみる。そうすると、距離が近いほどアテンション係数が高くなることに直結する。しかし、実際には、クエリベクトルとキーベクトルのノルムは様々であり、ドットプロダクトと距離の関係は正確ではない。しかし、次のセクションで説明するように、この関係を驚くほど近くなるようにアレンジすることが可能である。
図2は、言語トランスフォーマーにおける1つのアテンションヘッドという合成例で、この手法を説明する。共同埋め込みを作成するために、まず、与えられた文の各トークンのクエリとキーベクトル表現を取得する(第2項)。次に、t-SNE[43]、UMAP[27]、PCA[19]の3つの次元削減法のいずれかを用いて、これらの高次元ベクトルを共通の低次元部分空間上に投影する。これらの次元削減アルゴリズムの出力は、2D/3D散布図であり、各ポイントは1つのクエリまたはキートークンを表します。同じプロセスを用いて、ViTのアテンションヘッドの共同埋め込みを作成することができ、各トークンは画像パッチとなる。デフォルトでは、クエリは緑色、キーはピンク色で可視化される。しかし、ユーザーが選択できる他の色エンコーディングもある(5.2節参照)。

5.1.1 Vector Normalization
AttentionVizを設計する際に、情報を失うことなく変化させることができる2つの「フリーパラメータ」に注目した。これらのパラメータを調整することで、埋め込み距離とアテンションウェイトの関係をより密接にし、可視化の可読性を大幅に向上させることができます。次元削減の前に正規化を行う(図2)。
Keyの移動:図3左のように、クエリベクトルとキーベクトルが分離している場合がある。この分離は、クエリとキーの埋め込みを直接比較することを難しくしている。しかし、簡単な数学的トリックにより、任意の入力シーケンスに対するアテンション計算に影響を与えることなく、これらの埋め込みをより近くに移動させることができる。特に、ソフトマックスファンクションは翻訳不変であることに注意されたい。すなわち、任意の定数に対して、
とする。 ここで、クエリーベクトル
とキーベクトル
を考えてみる。任意のベクトル
について、次のようになる:
ここで、第二式は翻訳不変性によって従う。これは、与えられた入力のアテンションパターンを変えることなく、すべてのキーベクトルを、各アテンションヘッドのクエリ分布とキー分布が同一の中心を持つように変換できることを意味する。これにより、クエリとキーの比較が非常に容易になる(図3右)。

クエリーとキーのスケーリング:GPT-2のようないくつかのトランスフォーマーでは、平均クエリノルムが平均キーノルムと大きく異なるケースが観察された。この差は、キーとクエリの関係の解釈を難しくしている。数学的には、内積と距離の関係が悪いことを示し、視覚的には、クエリが小さなクラスタであり、キーの緩い雲に囲まれていることを意味する。
幸運なことに、スケールはシステムのもう一つの「自由なパラメータ」である。アテンションレベルは、クエリベクトルとキーベクトルの内積にのみ依存するため、すべてのクエリベクトルを、すべてのキーベクトルを
の係数でスケールしても、アテンションは変化しない。 これにより、図4aに示すように、注目度の高いクエリーとキーのペアは、共同視覚化でより近くに配置されるようになる。 (曖昧な点:スケーリングだけではコサイン距離は変割らないが、翻訳正規化と組み合わせると、自明ではない効果がある。)

の最適値を決定するために、ジョイント可視化では近くのクエリとキーに最も注意を払うので、距離が小さいクエリとキーのペアに重きを置く加重相関メトリックを定義することができる。したがって、クエリ-キーの内積と距離の間の重み付け相関が最大になるようなスケールファクター
を選択することができる。 このスケーリング方法により、ジョイント埋め込み空間における距離が、クエリとキーの間の実際のアテンションバリューを最も正確に表現することができる。
5.1.2 Distance as a Proxy for Attention
上記で説明したように、理想的には、クエリキーペアの内積が大きく正であれば(最終的な注目値が高いことに対応)、埋め込み空間においてより近くに配置されるはずであり、逆もまた同様である(図4a)。したがって、我々の共同クエリキー埋め込みにおいて距離はアテンションは逆相関すると考えられる。そこで、BERT、GPT-2、ViTの各注目ヘッドについて、コサイン距離とドット積のスピアマン順位相関を計算し、この潜在的な関連性を検討した。また、クエリとキーのSNE投影とUMAP投影を作成する際に、ユークリッド距離を距離指標として使用する実験も行ったが、一般に距離とドット積の相関は弱くなった。
複数のデータセットとモデルにおいて、ディスタンスとアテンションの関係はかなり良好である。 例えば、Wiki-Autodata [18]では、クエリ-キーの距離とドットプロダクトの平均相関は、BERTで0.938、GPTで0.792である。BERTの結果の一例を図4bに示す。使用したCOCO画像セット[23]では、平均相関はViT-32で0.873、ViT-16で0.884である。
5.2 Color Encodings
AttentionVizでは、クエリやキーのさまざまな特性を視覚化するために、さまざまなカラーエンコーディングを用意している。デフォルトのオプションは、クエリまたはキーといったトークンのタイプによってポイントを着色する。ViTでは、イメージパッチローやカラムで色付けし、位置パターンを視覚化することができる(図10)。画像はそれ自身の色情報を持つため、スタイリング要素を追加せずに元のパッチを表示することも可能である(図8)。


言語トランスフォーマ0では、正規化および離散の2つの位置の配色をサポートしている。正規化された位置を計算するために、文中の各トークンの位置を文の長さで割って、連続的なカラースケールを作成する。明るい色調は文頭に近いトークンを表す(図5b)。 このため、1番目と6番目のトークンは同じ色、2番目と7番目のトークンは同じ色、といった具合に、それぞれのトークンの位置を5で割った余りを求める離散位置符号化を行う。同じ5色を使って、異なる位置にあるクエリとキーを符号化し、前者には暗い色相を使用する。図11(左)のようなジョイントエンベッディングでは、位置のわずかなずれに基づく関係(例えば、クエリが一歩先のキーに注目する)を見るために、離散的な色付けが有効である。また、クエリ/キー規範による色付けも可能である(図12a)。



5.3 Views
AttentionVizは、マトリックスビュー、シングルビュー、センテンス/イメージビューの3つの主要なインタラクティブビューを提供し、アテンションを探索する。
5.3.1 Matrix View
AttentionVizの初期ビューはMatrix Viewで、小さな倍数を使用してトランスフォーマーのすべてのアテンションヘッドを一度に可視化し(図5a)、[T1]と[T3]に直接対応する。各行はモデル層に対応し、インターフェイスの上部にある以前の層から下部にある後の層へと移動する。 この「グローバル」な視点により、ユーザーは、シングルプロット(例:[46])やインスタンスレベル可視化(例:[3, 39])と比較して、異なるトランスフォーマー層やヘッドのパターンをより容易にスキャンすることができる。本研究で使用したモデルはすべて同じアーキテクチャであった。
マトリックスビューでは、t-SNE、UMAP、PCAで作成されたクエリとキーの結合埋め込みを見ることができる。また、モデルタイプ(BERT、GPT-2、ViT-16/32)やデータセット[T4]を切り替え、さまざまな配色を検討し、結果のプロットを2Dまたは3Dで見ることができる。Matrix Viewは、グローバル検索機能(図6a)をサポートしており、異なるヘッド間のトークン位置のパターンを強調することができ、スケールでアテンションを分析するもう一つの方法(第7節参照)を提供している。

5.3.2 Single View
マトリックスビューの任意のプロットをクリックすると、シングルビュー(図5b)にズームすることができ、1つの注目ヘッドをより詳細に探索することができる[T3]。 マトリックスビューと同様に、ユーザーはシングルビューでカラーリング、寸法、投影モード、データセット、モデルを切り替えることができる[T4]。比較を容易にするために、すべてのグラフィックの変更はビュー間で同期する。また、クエリとキーのトークンを結ぶ散布図に注目線を投影するオプションもある(図5c)。読みやすくするために、各トークンの注目度上位2つだけを表示す。この注目線機能は[T2]をサポートし、変換器の注目パターンをヘッドレベルで可視化する新しい方法を提供する。シングルビューでは、ユーザーはトークンを検索し、[39]と同様に、データ内の意味パターンを明らかにするためのラベル機能を使用することもできる。 例えば、図6bでは、検索によって、このBERTヘッドの結合埋め込みにおいて、類似した意味を持つクエリ/キートークンが一緒に配置されており、それらの間の強いアテンションを示していることがわかる(Sec. 5.1.2)。
5.3.3 Sentence/Image View
Sentence/Image Viewは、1つの文章や画像内の細かなアテンションパターンを探索することができる[T2、T3]。 両ビューはシングルビューで同期され、各クエリ/キーの散布図に重なるアテンションラインと一致し、スムーズなユーザー体験を提供する。
Sentence View :BERT または GPT-2 を使用する場合、ユーザーは Single View のポイントをクリックすると、左サイドバーに Sentence View が表示され、クリックしたトークンが強調された文レベルのアテンションの BertViz に触発された可視化 [46] が表示される(図 5c)。ヒートマップによる視覚化(例:[32])も検討したが、長い文章では、2分割グラフのアプローチの方が読みやすさとパターン探索のしやすさに優れていると思われた。左の列のクエリートークンと右の列のキートークンを結ぶ線の不透明度は、対応する注目の強さを示している。トークンにカーソルを合わせると、トークン固有の注目線が強調される。 BERTの分類トークンやセパレータ、GPT-2の最初のトークン(Sec.7)からのノイズを減らすために、ユーザーはこれらの特別なトークンの注目線を非表示にすることができる。 また、各アテンションヘッドのアテンションパターンを表示することも可能で、別のレイヤーで比較することができる(図11a)。
Image View:ViTの画像ベースの入力では、画像パッチをクリックすると、サイドパネルに対応するオリジナル画像が表示され、クリックしたトークンが色付きの枠で強調される(図7a)。 また、画像に注目度ヒートマップを重ねて表示し、クリックした画像パッチと画像の他の領域との間の注目度を透明度で示す(図7b)。イメージビューでは、単一のトークンの注目度を可視化するだけでなく、異なる画像パッチ間に矢印付きの注目線を表示して画像内の全体の注目パターンを探索することができる。1つ目のオプションは、元の画像パッチの上に矢印を重ね、それぞれの矢印が、開始画像パッチと目的パッチ間の最も強いアテンションのつながりを表している(図7c)。これにより、簡略化された2分割のアテンショングラフが作成され、ユーザーは特定のヘッド内の最も重要なパターンを特徴付けることができる。2番目のオプションは、すべての強いアテンションの接続(すなわち、attn(xi,xj)>0.1)を元の画像の横に表示し、アテンションをより包括的に見ることができる(図7d)。この可視化では、不透明度と線の太さの両方がアテンションの強さを表現するために用いられている。また、[46]をより忠実に再現するために、クエリとキーの間のすべての重みを可視化することも試みたが、この場合、過密で不可解な結果が生じることが多い。
6. SYSTEM IMPLEMENTATIO
モデルの入力を処理し、アテンション情報を計算するために、Hugging Face TransformersライブラリとPyTorchを使用している。BERT、GPT-2(小)、ViT-16/32の訓練済み実装を、GoogleとOpenAIのモデルウェイトで使用する。各NLPデータセットについて、ランダムに200文(クエリとキーの両方を含む、アテンションヘッドあたり約10kトークン)をサンプリングする。画像アテンションデータは計算量が増えるため、ViT-32では1ヘッドあたり10画像(1000トークン)、ViT-16では1ヘッドあたり4画像(1576トークン)を表示した。ViTの画像パッチの意味ラベル(例えば、「犬」や「背景」)を生成するために、DeepLabv3のセグメンテーションモデル[6]を使用する。
AttentionVizの最終プロトタイプは、VueとTypeScriptで書かれたフロントエンドと通信するPython / Flaskバックエンドで構成されている。デモシステムは:http://attentionviz.com。 データサイズが大きく、ブラウザのメモリ制約があるため、計算済みのアテンション/投影情報をJSONファイル経由でバックエンドにロードしている。ViTでは、バックエンドが画像処理(パッチハイライトや透明度調整など)を行い、フロントエンドに表示する。Deck.glを使用して、クエリとキーの共同埋め込みの結果を視覚化することができる。 AttentionVizは非常に拡張性が高く、モデルを問わないため、ユーザーは新しいトランスフォーマーやデータセットをシステムに追加することができる。
7. FINDINGS & EVALUATION
AttentionVizの有用性は、3つのアプリケーションシナリオとドメインエキスパートからのフィードバックによって説明される。AttentionVizのシナリオは、第4章の目標を達成するものであり、視覚と言語変換の世界的なセルフアテンションの傾向について、AttentionVizがどのような洞察を提供できるかを示している。
データ:BERT/GPT-2では、様々なNLPデータセットを用いて実験を行いましたが、今回の応用シナリオでは、2つのデータセットに焦点を当てた。Wiki-Auto[18]をベースラインとして一般的な入力文をサンプリングし、Super-GLUE AXb[49]をテキストテイルメントに対するタスク固有のアテンションパターンを探索するために使用する。 ViTについては、ImageNet Large ScaleVisual Recognition Challenge [37] とMicrosoft COCO: CommonObjects in Context [23] から画像を抽出し、合成画像データも用いた。
ユーザーインタビュー:E2およびE3を招き、第2ラウンドのインタビューに加え、E6(通訳研究者)とE7(視覚科学の博士課程学生)の新しい専門家を加えた。第4章と同様に、すべての専門家は個別にインタビューを受けた。 まず、私たちのツールの簡単なデモを行い、私たち自身の発見をいくつか共有し、何か考えや洞察があれば共有してもらうようにした(7.1-7.3)。次に、AttentionVizの主な長所、短所、新規性について、より一般的なフィードバックを求めた(Sec.7.4)。また、埋め込みをスケールで可視化するためのこの手法の拡張や応用の可能性についても専門家に質問した。
7.1 Goal: Understanding Machine Visual Attention
AttentionVizは、画像パッチデータが本質的に視覚的であるため、視覚変換器のアテンションに関する洞察を明らかにするのに特に役立つ[G1].
視覚的注意における色相・明度の特殊化.私たちは、視覚的な注意力が色と明るさのどちらかに特化したものであるかどうかを知りたいと考えた。そこで、ViT-32の学習済みモデルに合成色と明るさのグラデーション画像を与え(図8)、その結果得られたクエリとキートークンをAttentionVizに読み込ませた。
マトリックスビューでグローバルパターンをブラウジングすると、色と無色の視覚に類似した2つのアテンションヘッドを確認できた。1つは白黒画像のトークンを明るさに基づいて整列させ、もう1つはカラフルなパッチを色相に基づいて整列させるように見える。このデータセットには、あらゆる方向の色と明るさのグラデーション画像が含まれており、元画像の位置に関係なく、類似したパッチが共同埋込み空間内で集まっていることがわかる。E7はこの結果に興味を持ち、以前、畳み込みニューラルネットワーク(CNN)の色潜在空間を研究したことがあり、CNNとViTの動作の違いをさらに探求するために我々のツールを使用することに興味を示していた。
周波数フィルタリングと角度検出。周波数と角度は、画像データの低レベルの特性である。周波数と角度の異なる正弦波信号の画像を作成し、学習済みのViT-32モデルで処理することで、VisionTransformerにこれらの特徴に基づく視覚パターンを関連付けるアテンションヘッドがあるかどうかを調べた。 その結果、クエリとキー埋め込みをMatrix Viewで見ると、空間パターンの周波数(x軸)と角度(y軸)に基づいてイメージトークンを分離するアテンションヘッドが確認された(図9)。 E7は、この結果は興味深いが、我々の色相・輝度に関する知見からすればそれほど驚くことではないとし、この「類似したパッチに注目する」行動を示さないヘッドについて、より興味を持ったと述べている。例えば、2つの画像(例:シマウマと傘)において、同じ画像パッチ(例:縦縞)が異なる文脈で出現した場合、独自のアテンションパターンが見られるのだろうか?
モデル層間のアテンション距離の増加:[12]で述べたように、ViTの深い層では、セルフアテンションが画像間でより広範囲に注意することが分かっている。ViT-32の第1層と第2層では、トークンを左、右、上、下という空間的に最も近いものとグループ化する4つのアテンションヘッドを見つけるために、Matrix Viewを使って、画像の「行」と「列」でパッチを色付けした。 このことは、正方形のフィルターを使って画像を処理するCNNとは異なり、トランスフォーマーのセルフアテンション機構は、細長いフィルターに類似した、行ごと、列ごとの画像を処理することが多いことを示唆している。

7.2 Goal: Finding Global Attention Traces
言語トランスフォーマー[G2]の異なるヘッド間でセルフアテンションパターンがどのように変化するかを理解するために、AttentionVizを使ってBERTを探索した。
位置アテンションの痕跡:例えば、層3の渦巻き状のプロット(図5a)のように、ユニークな形状のアテンションヘッドがいくつか観察された。 例えば、レイヤー3のヘッド9をSingle Viewで正規化ポシションで色付けすると、トークンの位置が螺旋の外側から内側に向かうにつれて増加していることがわかる(図5b)。SentenceViewでこのパターンをより詳細に調べると(図5c)、位置的な「次のトークン」へのアテンションパターンがあることが確認された。また、この「スパイラル」は、トランスフォーマーに与えられた最初の順序ベクトルを反映している(第2項)。
さらに、マトリックスビューで識別可能な他の「痕跡」に注目したところ、小さな「塊」があるプロットにも位置パターンがあることがわかり(図11左)、それを離散の位置色分けで検証した。 スパイラル」と「塊」の違いは、トークンが1つ離れた位置の他者に選択的に注目するか、複数の異なる位置に注目するかの違いにあるようだ(図5c)。同様に、クエリーとキーの重なりが大きい頭では、トークンは自分自身と同じトークンの他のインスタンスに注目し、「自己を見る」パターンを示すことがわかった。これらのヘッドを拡大すると、図6bに示すように、近接したクエリキーペアの意味的なクラスターが明確に見られ、この観察がさらに裏付けられている。
[24]によると、初期のトランスフォーマー層は線形語順に関する情報を最も多く持っており、我々の発見や[8, 46]などの過去の研究結果と一致している。 インタビュー中、E2、E6、E7は、これらの興味深い幾何学的形状、特にスパイラルにすぐに気づき、観察された構造のどれだけが純粋に位置によるものなのかについて好奇心を抱いた。例えば、トランスフォーマーモデルの位置埋め込みを操作したり削除したりして、クエリキーの可視化がどのように変化するかを見るなど、専門家からいくつかのフォローアップ実験のアイデアが出された。
タスク固有の痕跡:AttentionVizで複数のデータセットを可視化した結果、共同埋め込みの形状は、異なるNLPタスクで非常に一貫していることがわかった。しかし、SuperGLUEAXbdataを用いたBERTのいくつかの後の層でのみ生じる視覚的トレースを確認した(図11右)。このようなヘッド(レイヤー8ヘッド9)をクリックして位置で色分けすると、クエリ・キーの「サンドイッチ」が観察され、テキストの先頭のキーとクエリが上に積み重なり、テキストの終わりのクエリとキーが逆の順序で続く。センテンスビューでは、テキストの先頭、中間、終わりが最も注目されていることが分かる。 全体的なプロットの形と注目のパターンから、これらの頭はテキストの「中間点」を識別し、文の区別ができることが示唆される。これは、含意タスクで2つの文を比較して、同じ意味を持つかどうかを確認する方法を反映している。また、クエリは主に同じ文のキーに注目する。[20,47]は、同期戦術とタスク固有の情報がモデル中盤から後半にかけて最も顕著であることを示し、おそらくこのトレースのユニークさを説明するものである。
グローバルな検索パターン:また、MatrixViewの集計検索機能を使えば、ヘッド間のアテンションの傾向を素早くスキャンして比較することができる[G2]。我々は、検索結果のパターンが、以前に特定した視覚的なアテンションの痕跡を反映していることを発見した(図6a)。例えば、渦巻き型や小さなクエリ/キーの塊があるヘッドは、検索結果がより分散しており、その根底にある位置的アテンションのパターンを示している。 一方、「自己を見る」アテンションパターンを持つヘッドは、検索結果のクラスタが1つしかなく、同じトークンのクエリとキーの間の強い相互作用を強調している。クエリとキーの共同埋め込みが明確な形状を持たない場合でも、検索結果のクラスタがいくつかある場合、ヘッドはより意味的な振る舞いを見せる可能性があり、それ以外の場合は、おそらく位置的アテンションパターンがあることが分かる。[41]は、意味情報がBERTのレイヤーに広がっていることを指摘しており、我々はAttentionVizでこれを確認した。我々の専門家の全員が、我々のツールのこの機能とアテンションパターンの比較を促進する能力に特に興奮していた。
7.3 Goal: Identifying Anomalies and Unexpected Behavior
Attention-Vizのクエリとキーの結合埋め込みを操作することで、いくつかの不規則なモデルの挙動を発見した[G3]。
ノーム不均衡とヌルアテンション:GPT-2 をMatrix View で観察していると、初期のモデル層では、キー変換を行った後でも、クエリとキーのクラスタがうまく分離していることが確認された(5.1.1 節)。ノルム(ノルムスケーリングステップの前に測定されたもの)で色付けすると、多くのヘッドで、クエリベクトルとキーベクトルのノルムに大きな格差があることがわかる(図12a)。 クエリのノルムが小さい場合(薄緑色)、キーのノルムは大きくなる傾向があり(濃いピンク色)、その逆もまた然りである。GPT-2とBERTのクエリとキーの平均ノルム差を計算すると、前者ではアテンションヘッド全体で平均クエリノルム-キーノルム=4.59であるのに対し、後者では平均差は0.41に過ぎないことがわかりました。 この結果を説明できる専門家はいませんでした: 「なぜクエリとキーで規範が異なるのか、意味がわからない」(E6)。興味深いことに、私たちがこの観察を行った後に発表された論文[9]では、制御不能なクエリとキーの規範が深刻な学習不安定の原因であると指摘しており、この現象はさらに研究する価値があることが示されています。この観察は、5.1.1節のスケーリングアプローチにも影響を与えました。
また、多くのGPT-2ヘッドでは、特に後期において、ほとんどのアテンションが最初のトークンに向けられている(図12b)ことに気づいた。 [47]は、GPT-2において、最初のトークンが、"減衰ヘッドによって捉えられた言語的特性が入力テキストに現れない場合"、アテンションを受け取るためのヌルポジションとして扱われることを簡単に説明している。しかし、この現象は未解明であり、検討すべき別のオープンな解釈可能性の問いを提示している。E2およびE6は、我々のツールでこの異常な動作に自ら気づき、我々の専門家は皆、このインディングに驚いている。 [48]は、トランスフォーマー内の大部分のアテンションヘッドを刈り込んでも、モデルの性能に大きな影響を与えない可能性があることを示しており、おそらくこの支配的なヌルアテンションパターンに部分的に起因している可能性があります。しかし、AttentionVizは、最初のトークンに支払われたアテンションをフィルタリングし、隠れたクエリとキーの相互作用を明らかにすることができます。
"自分を見つめる "アテンションヘッド:AttentionVizは、ビジョントランスフォーマーの驚くべきアテンションパターンを明らかにすることもできます。Matrix Viewでは、ViT-32の初期層で、キーとクエリのクラスタが非常に拡散しているヘッドをいくつか確認した(図13a)。 そのような注目ヘッド(レイヤー0のヘッド8)を見ると、同じトークンのクエリーとキーの埋め込みが小さいながらも密集したクラスターを形成しており、それぞれのクエリーとキーのペアが他からよく分離していることがわかった(図13b)。イメージビューの透明ヒートマップから、パッチは自分自身にのみ注意を向けていることがわかる(図13c)。矢印のついたアテンション線に切り替えると、この画像の全体的なアテンションパターンは「自分を見る」であり、この頭の中では画像トークン間に情報が流れていないことがわかる。
この不規則なアテンションパターンを特定した後、学習したクエリマトリクスとキーマトリクスのパラメータを相関テストによって確認した。 その結果、強い類似性(線形相関=0.94)が認められ、このViTヘッドのクエリー層とキー層は、確かに冗長な投影を学習していることがわかりました(図13d)。E3は、この知見をモデルの刈り込み実験に活用できると指摘しました。
7.4 Takeaways from User Feedback
マトリクスビューのメリット:複数の専門家が、Matrix Viewが提供する「グローバル」な視点は、AttentionVizの最も斬新で価値のある部分であると述べている。E6は、「複数のエンベッディングを一度に可視化したいときに、ハイパーパラメータの調整から解放され、素早く比較できるのが素晴らしい」と述べている。またE7は、Matrix Viewが有用である理由として「小さな可視化なら自分でコーディングすればいいが、規模やデータ量が増えるとかなり大変だ」とも述べている。 これらのコメントから、エンベディングをスケーラブルに可視化し比較するという考え方は、他のMLの場面でも有益であることが示唆された。
共同クエリキー埋め込みへの応用:専門家は、私たちの可視化手法の様々な使用例や拡張を提案し、その適用範囲の広さを証明した。例えば、E2は、未訓練または破損したトランスフォーマーのパターンを可視化することを提案し、E3およびE7は、自分自身のモデルについて訓練中のアテンションの変化を可視化することを希望し、我々の当初の目標(第4項)に合致している。 同様に、E3は「2つのアテンションパターンが異なるヘッドでどのようにつながるか」を調べることに興味を示し、これは確かに誘導ヘッドペアの視覚化に適用できるだろう。E2は「2つのヘッド間の類似性を定量化する」方法を追加することが有用であると指摘し、E6はモデル刈り込みを目的とした「ヘッドのランダム性の測定または視覚化」を提案した。
プロジェクションの組み込み - 信頼すべきか、信頼すべきでないか?: E3は、投影法を用いることの難しさを強調しました。私たちが発見した幾何学的なパターン(スパイラルなど)を高く評価する一方で、t-SNEやUMAPなどの技術による歪みがあるため、これらの可視化の解釈には懐疑的な意見もありました: 「自分が見たものを信用できるかどうか、どうやって判断すればいいのか。」 これは、視覚的な洞察を実行可能な介入に結びつけることの重要性を強調するもので、おそらく、探索に加えて仮説検証をサポートするために我々のツールを拡張したのでしょう。
柔軟性と使い勝手のトレードオフ:E2は、AttentionVizが「非常に使いやすく、カスタマイズできる」と述べ、既存の可視化ツールに対する以前の懸念を払拭した(第4項)。しかし、E6のような専門家の中には、「すべての機能やヘッドを表示すると、圧倒されるかもしれない...」という懸念を抱いている人もいた。「情報を要約する方法はないのか?」また、E7は、「ヘッドにラベルをつけるのに、もっと手軽で良い方法はないだろうか?」と、特徴量の視覚化に近いアプローチを提案している[31]。私たちは、AttentionVizを柔軟なツールにするために設計した(例えば、異なるトランスフォーマーや異なる粒度でアテンションを分析することができる)が、私たちの設計の柔軟性と使用性のトレードオフ [22] はまだ改善できるようである。
インタラクションモードの追加:例えば、オンザフライ推論(E3)や、クエリやキーの丸で囲まれたクラスターをさらに次元削減して追加情報を明らかにし、きめ細かい分析を行う(E2)など、インタラクションモードを追加することを提案した専門家もいました。E7は、ユーザーが新しいデータセットを直接システムにアップロードできるようにすることの重要性を強調した。「このツールはさらに強力になり、人々は自分の画像を追加するなど、より多くのことを探求したくなるはずだ。」
8. CONCLUSIONS & FUTURE WORK
本論文では、クエリーとキーの結合埋め込み空間に基づく、トランスフォーマーのセルフアテンションを可視化する新しい手法を紹介する。適切な正規化により、この空間における距離が、アテンションの重みを数学的に適切に近似できることを示す。 複数の入力に対するクエリとキーのコレクションを可視化することで、既存の可視化手法では困難であった、異なるアテンションヘッドにおける特徴的なパターンを見ることが可能になる。また、VisionTransformerのために、1つの画像に対するアテンションパターンを理解するのに役立つシンプルな2Dグラフ可視化を作成し、2分割アテンション表現のアイデアを画像ドメインに拡張した。
この技術を応用して、アテンションパターンをスケールで探索するインタラクティブ可視化ツール、AttentionViz (demo:http://attentionviz.com) を作成した。複数の応用シナリオと専門家へのインタビューを通じて、我々の手法が、異なるレベルでのクエリキー相互作用を探ることで、言語と視覚変換の両方におけるアテンションについての洞察を明らかにできることを示す。専門家のフィードバックは、この手法の有用性を証明するとともに、今後の課題としていくつかの道を指し示している。例えば、複数の埋め込み型可視化の複雑さを管理し、ユーザーを興味のある特徴に集中させる方法を見つけることは、確かに有用である。また、ユーザーがその場で新しい入力を追加できるようにすることも、実りあるものになるかもしれない。
将来の研究のもう一つの自然な方向性は、各アテンションヘッドにヴァリューベクトルの情報を組み込む方法を探ることである[45]。 適切な可視化アプローチを見つけることで、アテンションヘッドがどのように機能するのかがより明らかになるかもしれない。最後に、AttentionVizは探索的なツールであるが、仮説検証や因果関係の追跡のために適応することで、実用的なモデルのデバッグを支援することができるかもしれない。
今日の論文2023/05/9,10:CIKQA: Learning Commonsense Inference with a Unified Knowledge-in-the-loop QA Paradigm
CIKQA: Learning Commonsense Inference with a Unified Knowledge-in-the-loop QA Paradigm
©2022 Association for Computational Linguistics
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容に基づき筆者が翻訳したものです。以下の図は、そこから引用しています。
This article is my translation based on the content of the original publication. The following figures are taken from it.
要点まとめ
我々は、(1)知識が質問に答えるのに十分かどうかを予測することによって、モデルが知識の質を区別できるかどうかを評価する、(2)モデルがタスクを越えて一般化できる常識的推論能力を得ることができるかどうかを評価する、という二つの観点から常識的推論の進歩を動機付ける新しいベンチマークを提案する。
まず、各質問に対してサポート知識を抽出し、自動抽出された知識が質問に答えるのに十分かどうかを人間にアノテートしてもらう。その後、モデルの汎化能力を評価するために、異なるタスクを統一された質問応答形式に変換する。このベンチマークをCommonsense Inference with Knowledge-in-the-loop Question Answering (CIKQA)と名付けた。
実験の結果、我々の学習パラダイムを用いると、モデルは有望な汎化能力を発揮することがわかった。同時に、現在の常識的推論モデルでは、知識の質を区別することが依然として困難であることもわかった。
1. 序論
人間の言語を理解するためには、文法や意味論などの言語知識と、事実と常識に分けられる世界知識の両方が必要である(Katz and Fodor, 1963)。近年、機械が言語や事実の知識を習得し、応用できるようにすることが、社会的に大きな成果を上げている。しかし、どのようにすれば機械が常識を獲得し、推論できるようになるかは、まだ不明である。この疑問に答えるため、多くの常識的推論データセット(Roemmele et al, 2011; Sak-aguchi et al, 2020; Talmor et al, 2019; Zellers et al., 2019; Lin et al., 2020)が提案されている。これらは、異なる知識の種類、モダリティ、形式を対象としているが、多くの場合、学習データを用いて機械が特定のタスクを解決することを目的とした、標準的な教師あり学習設定に準拠している。しかし、この学習パラダイムの2つの限界により、常識的推論システムの開発は制限されてきた。
第一に、知識と推論の間に明確な境界がないこと。Elazaret al. (2021)で議論されているように、一般的な現象は、より大きな学習データがより良いパフォーマンスにつながるというもので、これは主に、より豊かな知識がカバーされるためである。しかし、常識的な知識の規模が大きいため、各タスクに対して十分な量の訓練セットをアノテーションすることは不可能であり、訓練データの役目は、常識的な知識を獲得することよりも、推論の方法をモデルに教えることであるべきである。最近の研究では、常識的推論タスクに構造化知識を用いることが検討されている(Lin et al, 2019; Lv et al., 2020; Pual and Frank, 2020)。しかし、これらの研究では、構造化された知識(知識グラフ(KG))のカバー率を明確に分析していないため、知識カバー率の向上や推論能力の向上など、その性能が何を意味するかはまだ不明である。この学習プロセスの背後にあるものを調べるために、我々は、質問に自動抽出された知識を装備し、その知識が質問に答えるのに十分であるかどうかを人間にアノテーションしてもらうことを提案する。これにより、モデルが提供された知識の良し悪しを知ることができるか、また提供された知識に対してどの程度の推論を行い課題を解決できるかを評価することができるのである。
第二に、教師あり学習は、普遍的な推論モデルではなく、訓練データの分布をモデルに学習させる可能性がある。その結果,モデルは同じ分布に従うテストセットでは良好な性能を示すが、汎化に失敗することがある(Kejriwal and Shen, 2020)。 従来は、タスクの形式が異なるため、常識的な推論モデルの汎化能力を評価することが困難であった。 異なるタスクに対して統一されたフォーマット(質問応答)を使用する傾向(Khashabi et al, 2020)に従い、学習した常識的推論モデルの一般化能力を容易かつ公平に評価できるように、様々な常識的推論のタスクを統一されたQAフォーマットに変換することを提案する。
この2つの取り組みを組み合わせて、新しい常識的推論ベンチマークCommonsense Inference with Knowledge-in-the-loop QA (CIKQA)を提唱する。その一例を図1に示す。 我々はまず、いくつかの一般的な常識的推論タスクを統一されたQAフォーマットに変換し、既存の常識的知識グラフから関連知識を装備する。人間のアノテーションを活用し、提供された知識が正しいかどうか、質問に答えるのに十分かどうかをラベル付けする。CIKQAベンチマークは、次の2つの質問に答える動機付けとなる。 (1)現在のモデルは、知識がゴールド(推論に必要十分な知識)かそうでないかを区別できるかどうか。(2)現在の常識的推論モデルは、異なる常識的推論タスクで一般化できるかどうか。最近の知識ベースの常識的推論モデルを用いた実験によると、現在のディープモデルは、真の知識が提供された場合、いくつかの例で訓練した後、単純な推論を行うことを学習できたとしても、真の知識のエッジを区別することはまだうまく学習できないことがわかった。さらに、現在のモデルは、我々が検討した3つのタスクにおいて、有望な汎化能力を示しているが、複雑な推論(例えば、仮説推論)にはまだ苦労している。 このベンチマークが、将来、より高度な常識的推論手法の動機付けとなることを期待している。
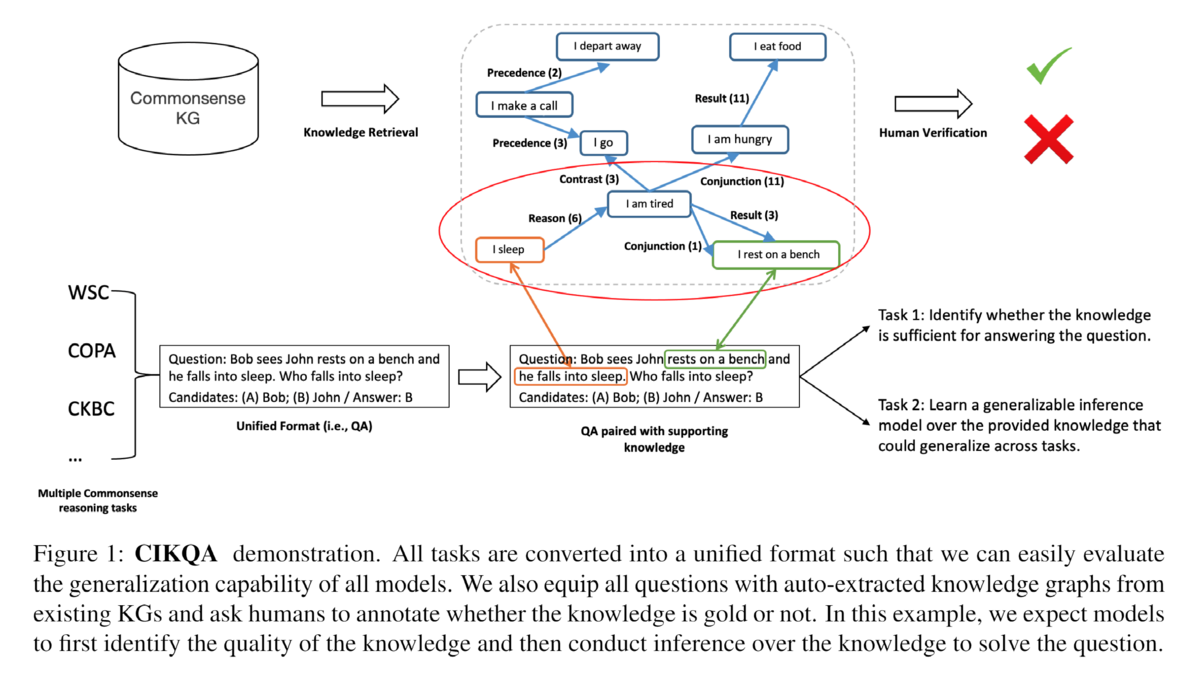
2. データセットの構築
CIKQAでは、一般化可能な常識的推論モデルを奨励するため、先行研究(Khashabi et al, 2020; Cohen et al, 2020; Wu et al, 2020; Du and Cardie, 2020)に従って、すべての選択タスクを二値質問回答問題として統一し、各質問に既存の常識KGから取得したサポート知識グラフを装備する。我々は、クラウドソーシングワーカーを活用し、その知識が質問に答えるためのゴールド(正確で十分)かどうかを注釈する。これにより、モデルがゴールドと知識を区別する方法を知っているかどうか、また、知識の助けを借りて一般化可能な推論を学習できるかどうかを評価することができる。CIKQAには、4種類の常識的推論タスクからなる1万5千個のインスタンスが収録されている。タスクの選択、フォーマットの統一、知識の抽出、アノテーションの詳細については、以下の通りである。
2.1 タスク選択
CIKQAでは、一般的な推論タスクとして、以下の4つを選定している。
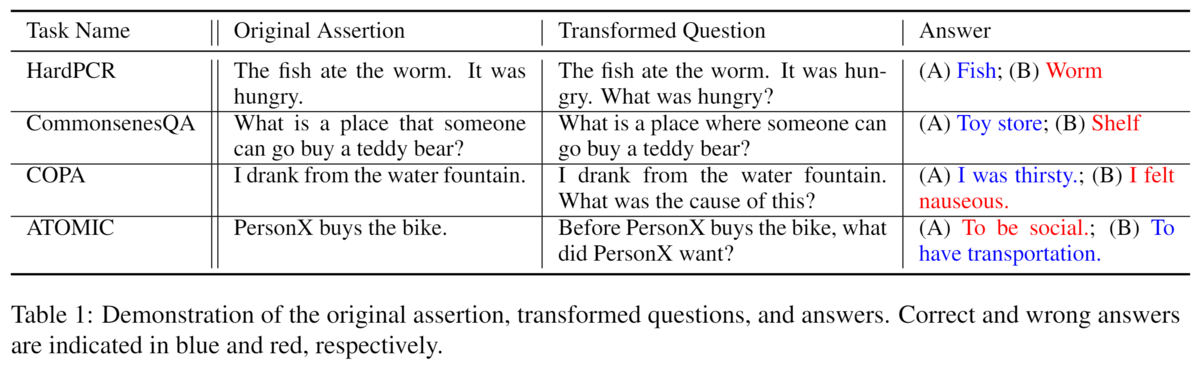
HardPCR (Zhang et al., 2021)は、最も有名な常識的推論タスクの1つで、代名詞の共参照解決タスクである。各問題には、対象となる代名詞と候補となる2つの言及が用意されており、代名詞が指す言及を正しく選択することが課題となっている。 単純な言語ルールの影響を排除するために、専門家による丁寧なアノテーションを行い、常識的な推論で問題を解決することが求められている。我々は、WSC(Levesque et al., 2012)、DPR (Rahman and Ng, 2012)、WinoGrande (Sakaguchi et al., 2020)のインスタンスを含めた。対象の代名詞に関する質問を作成するに、まず対象代名詞を含む文章を探し、参加代名詞が人を指しているのか、物を指しているのかを判別する。
CommonsenseQA (Talmor et al., 2019)は、多肢選択式の質問回答データセットである。各質問と回答のペアに対して、4つの関連するが間違った概念が他の候補として使用され、モデルは5つの候補から正しいものを選択することが要求される。 CIKQAでは、否定的な答えをランダムにサンプリングして二者択一のタスクにしており、これは他のデータセットと一致している。
COPA(Roemmele et al., 2011)は、イベントの因果関係の理解を評価することに重点を置いている。対象イベントに対して2つのフォローアップイベントが提供され、モデルは対象イベントの原因や理由を予測するよう求められる。
ATOMIC (Sap et al., 2019)は、常識的な知識グラフであり、我々はこれを補完問題に変換する。ヘッド概念(例:「食べ物を食べる」)と関係(例:「原因」)が与えられた場合、ATOMICのエッジを予測することに焦点を当て、テイル概念を予測したい。
COPAやATOMICでは、2つの事象や状態(例えば、「PersonXが食べる」-「PersonXが満腹になる」)の関係を予測することが課題となっており、各トリプレットについて、ネガティブテールとして別の事象や状態をランダムに抽出し、モデルに正しい方を選択するよう依頼する。タスクを難しくし、無関係なイベントや状態をサンプリングしないようにするため、サンプリングされた負のイベントや状態は、別のトリプレットのヘッドと接続するように制限する(例えば、"PersonX eats"-CausedBy-"PersonX is hungry "のトリプレットから "PersonX is hungry")。それぞれの関係に対して、質問を生成するためのパターンを記述する。 例えば、「原因」関係では、「イベント『PersonXが食べる』によって引き起こされるものは何か」と問う。 元のデータセットに含まれるインスタンスとその変換された質問と回答候補の例を、表1に示す。
2.2 サポート知識の抽出
セクション1で述べたように、既存の常識的推論ベンチマークの限界は、知識と推論の間に明確な境界が存在しないことである。そのため、学習データから何を学ぶのか、知識を学ぶのか、推論を行うのか、あるいはその両方を組み合わせるのかが不明である。私たちは、この問題に対処するために、各質問にサポートする知識を装備し、モデルがトレーニングデータから知識ではなく、推論を学習することを奨励することを提案する。その質問に答えるための裏付けとなる知識が見つかれば、その質問はデータセットの一部として選択される。 なお、この手順は、純粋な教師あり学習よりも改善された評価セットアップとして機能し、常識的な推論を解決するものではないことに注意されたい。本節では、選択された常識知識グラフを紹介し、各質問に対応する常識知識を抽出する方法を紹介する。
2.2.1 コモンセンスKGの選択
ConceptNet(Liu and Singh, 2004)、ATOMIC(Sap et al, 2019)、GLUCOSE (Mostafazadeh et al, 2020)、そしてASER (Zhang et al, 2020a)など、機械の常識的推論能力を高めるために多くの常識的知識グラフが開発された。 このうち、ConceptNet、ATOMIC、GLUCOSEはクラウドソーシングで構築され、ASERは情報抽出技術により自動構築された。タスクの1つであるATOMICの他に、知識資源として他のKBを使用している。
2.2.2 サポートグラフの抽出
ここでは、外部の常識的な知識エッジベースから支持知識を抽出する方法を紹介する。 各質問について、サポート知識グラフから、質問に関する関連する常識的な知識を含むサブグラフを得る必要がある。サブグラフ抽出のプロセスは、以下の3つのステップからなる。(1) 前処理を行う: 各質問をいくつかのキーセンテンスに変換する。(2)マッチング:KG内の文と文のマッチング。(3)抽出:KG全体から、重要なサブグラフを抽出する。以下では、それぞれのステップの詳細を説明する。
データの前処理:各質問とそれに関連する回答候補について、まず質問語(例えば "What")を2つの回答候補に置き換え、2つの宣言文とする。 例えば、「魚は虫を食べました。それはお腹が空いていました。お腹が空いているのは誰ですか?"という質問で、候補が "Fish "と "Worm "だった場合、質問を宣言文に変換し、「魚はお腹が空いている」「虫はお腹が空いている」とする。その結果、この問題では3つの文が得られる: 「魚は虫を食べた」、「魚はお腹が空いている」、「虫はお腹が空いている」。
KGマッチング:質問とその回答を含む宣言文を取得した後、それらを知識グラフのノードにマッピングし、関連する知識を抽出する。各文章には複数の単語が含まれることがあり、完全に一致するものを見つけるのは困難な場合が多いため、埋め込みベースのファジィマッチング技術を採用している。KGの各文とノードを文として扱い、SimCSE (Gao et al., 2021)で対応する表現を得る。SimCSEは各入力文に対して、その文をベクトルに符号化する。 2つのベクトル間の距離が近いほど、2つの文が互いに類似していることを示す。得られた表現に対してコサイン類似度を用いて、2つの文の類似度を測定する。GLUCOSEは2億8700万ノード、ASERは1億9400万ノードなので、文のコサイン類似度を一対一で計算することは計算上不可能である。したがって、近似値を使用する。抽出された文に対して、まず、KGの上位N個のノードを見つける際のマッチング効率を高めるために、すべてのKGノードをベクトル空間でクラスタリングする大規模な類似性ベースのマッチングアルゴリズムであるFaiss (Johnsonet al, 2017) を適用する。グラフのすべてのノードをエンコードし、Faiss (Johnson et al., 2017)を用いてインデックスを作成する。そして、各クエリ文の最も類似したノードを高速で検索することができる。 その後、コサイン類似度に基づいてノードをソートし、上位K個の類似したノードを見つけることができる。NとKはそれぞれ60と1に設定した。 平均して、各質問に対して関連するノードを検索するのに25秒かかる。
グラフ抽出:次に、すべての関連ノードを含むサブグラフを抽出する。 抽出された個のノードを
とし、それぞれについて、KGから
個の類似ノードを見つける。結果として得られるマッチしたノード集合を
と表記する。 ノード
と
の任意のペアについて、KGに
と
間のパスが存在する場合、そのパスを保持することになる。すべてのパスを足し合わせると、最終的なサブグラフが得られる。1問あたりのグラフ作成にかかる時間は、平均して2秒以下である。
知識品質アノテーション: この抽出方法は自動で行われるため、一部のサブグラフは無関係であったり、質問の振り分けに不十分であったりすることがある。クラウドソーシングを利用して、抽出された知識がゴールド(正確で十分)かどうかを、1例につき5つずつアノテーションしている。注釈者間平均一致度(Cohenのkappastatistic)は0.83であり、本アノテーションの品質の高さを示している。最終的には、厳格な基準(5人中4人以上のアノテーターがゴールドに投票する必要がある)を適用して、ゴールド知識を選定している。
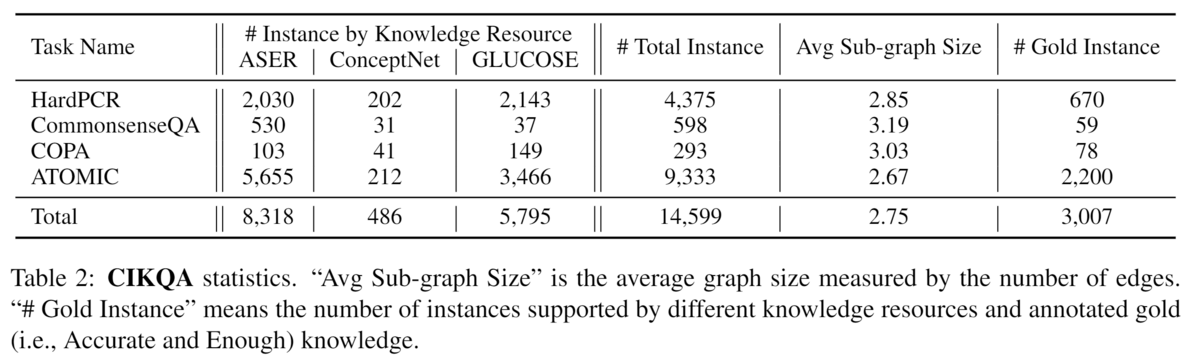
2.3 CIKQAの統計量
表2にデータセットの統計情報を報告する。CIKQAには合計で14,599個のインスタンスがあり、このうちHard PCRとATOMICは元データセットが他よりはるかに大きいため、最も多くの問題を提供している。アノテーションによると、20.59%のインスタンスにゴールド知識が含まれている。私たちの分析によると、アノテーターはゴールドナレッジを選択する際に非常に厳しい基準を設けている。データセットを8:1:1の標準的な分割方法で、各タスクのトレーニングセット、開発セット、テストセットにランダムに分割した。その結果、11,678個のトレーニング、1,459個の開発、1,462個のテストのインスタンスが得られた。
3. 実験設定
CIKQAにおける以下のような常識的推論モデルの性能を紹介する:
(1) Vanilla LM:言語モデル(LM)ベースの多肢選択式(MC)モデルを基本ベースラインとしている。 それぞれの回答候補について、質問と連結し、モデルに供給する。文の表現を得た後、線形レイヤーを使ってスコアを求め、cross-entropy lossで学習する。
(2) KagNet:KagNet(Linら,2019)は、構造化知識を常識的推論タスクの解決に活用した先駆的な研究の1つとして、まずグラフ畳み込みネットワークを用いて知識グラフを符号化し、LSTMベースの階層的アテンションメカニズムを適用して、質問に対応するノードから始まり、答えに対応するノードで終わる知識経路を符号化している。同時に、KagNetは質問と回答を事前に訓練されたLMで符号化する。 最終的には、すべての表現を連結して最終的な予測を行う。
(3) Graph-Based Reasoning (GBR):GBR (Lvet al., 2020)では、質問ノードから始まり回答ノードで終わるパスだけを符号化するのではなく、知識グラフに対して深さ優先アルゴリズムを実行し、サポートする知識パスとして一連のパスを生成することを提案している。
(4) Multi-Head Knowledge Attention (MHKA):MHKA (Pauland Frank, 2020) は、知識をさらに活用するために、質問ノードと回答ノードからの経路をモデル化する変換ネットワークを使用し、最終的な予測のために知識とコンテキスト表現を連結する。
(5) Graph-to-Text (G2T): また、構造化された知識と言語モデルを組み合わせるという、シンプルかつ効果的なアプローチも評価している。Graph-to-Text (Bian et al., 2021)は、まず知識を文に言語化し、次に知識文とターゲット質問を一緒に連結させる。その上で、Transformerベースのモデルを使って入力文を符号化し、最終的な予測を行う。
実装の詳細 すべての実験をHuggingface (Wolf et al., 2019)で実装している。すべてのモデルのbase言語モデルとしてBERT-base(Devlin et al, 2019)を選択する。バッチサイズは16に設定されている。すべてのモデルを10,000ステップで学習させ、devセットで最も性能の良いチェックポイントを評価する。このモデルでは、ランダムウォークの経路数と歩幅をともに5とした。 自動抽出された知識にはノイズや不確かな知識が含まれる可能性があることを考慮し、すべてのモデルに対して、ゴールドの知識エッジを持つ例のみを訓練とテストに使用する「ゴールド知識」設定を追加し、モデルの上限値として使用する。その他のハイパーパラメーターは、基本言語モデルと同じである。すべてのモデルはGTX2080で学習され、平均実行時間は12時間である。
4. 結果の分析
まず、提供された知識が既存のモデルにどの程度役立つかを評価するために、解析実験を行う。 各モデルについて、異なる数の訓練インスタンスで訓練し、5回の試行の平均性能と標準偏差を報告する。全インスタンスと、CIKQAのゴールドサブセット(ゴールドの知識を持つインスタンスのみを学習とテストに使用)の実験結果をそれぞれ図2、図3に示す。この結果から、次のような考察ができる。まず、知識を明示的に含めると、すべての推論モデルが、知識をサポートしないベースラインモデルを上回り、特にG2Tが上回った。自動抽出されたゴールド知識が提供された場合、G2TはベースラインのVanilla LMモデルに対して、それぞれ4.17、15.34の精度で上回った。これは、限られた学習データからすべての知識を学習することは困難であり、外部の構造化された知識が役立つという我々の仮説を支持するものである。 同時に、自動抽出された知識とゴールド知識との間に大きなギャップがあることにも気づいた。 例えば、ゴールド知識があれば、モデルはわずかな例で質問に答えることを学ぶことができる。これは、知識の質がモデルのパフォーマンスに大きく影響することを示しており、知識がゴールドかそうでないかを自動的に区別することの重要性をさらに示している。これは、現在の大規模LMの助けを借りて、質問と知識を別々に獲得するよりも、共同で符号化する方が効率的であり、より効果的な戦略であることを示している。G2Tはシンプルで効率的なため、残りの解析実験もG2Tで行う予定である。

4.1 ゴールド知識の判別
人間は、自分の知識では答えられないと判断したとき、「わからない」と言うことができる。現在のディープモデルが同様の能力を持つかどうかを調べるために、G2Tを例にして、これらのディープモデルがゴールド知識を識別できるかどうかをテストする。各(質問、回答、知識)トリプレットについて、注釈付き知識品質ラベルを用いてG2Tを訓練し、テストする。不均衡な分布の問題に対処するため、「Gold」と同数の「NotGold」例をランダムに選択し、データセットのバランスを整える。図4の結果から、G2Tの性能は学習データの増加により若干向上することがわかる。しかし、何千ものサンプルを見た後でも、2値分類問題で0.65の精度を達成するのがやっとである。これは、「わからない」と言うタイミングを知ることが、現在のディープモデルにとってまだ困難な課題であることを示しており、これは、ディープモデルが質問に答えるために使用した理由や知識を理解できないという過去の文献の見解と一致している(Zhanget al., 2020b; Sanh et al., 2022)。CIKQAが、この重要な研究課題に対する今後の研究の動機付けになればと思っている。

4.2 汎化能力
CIKQAの統一的な問題設計の背景にある重要な仮定と動機は、常識が膨大であっても、常識的知識に対する推論ルールは限定的であり得るということである。 その結果、限られた訓練データからすべての常識を学ぶことはできなくても、いくつかのタスクで推論を行う方法を学び、他のタスクに一般化することができる。本節では、「知識なし」と「知識あり」の両モデルを用いた実験を行い、我々の統一的な定式化により、異なるタスク間でこのような汎化能力を獲得できることを示す。 次の2つのセットで実験を行った:(1)フルセット:全データセットでモデルの訓練とテストを行う。(2)ゴールドサブセット: サポートグラフがゴールドと注釈された質問に対してのみモデルを訓練し、テストする。特定のタスクの質問でモデルを学習させ、すべてのタスクでテストする。その結果を表3に示す。
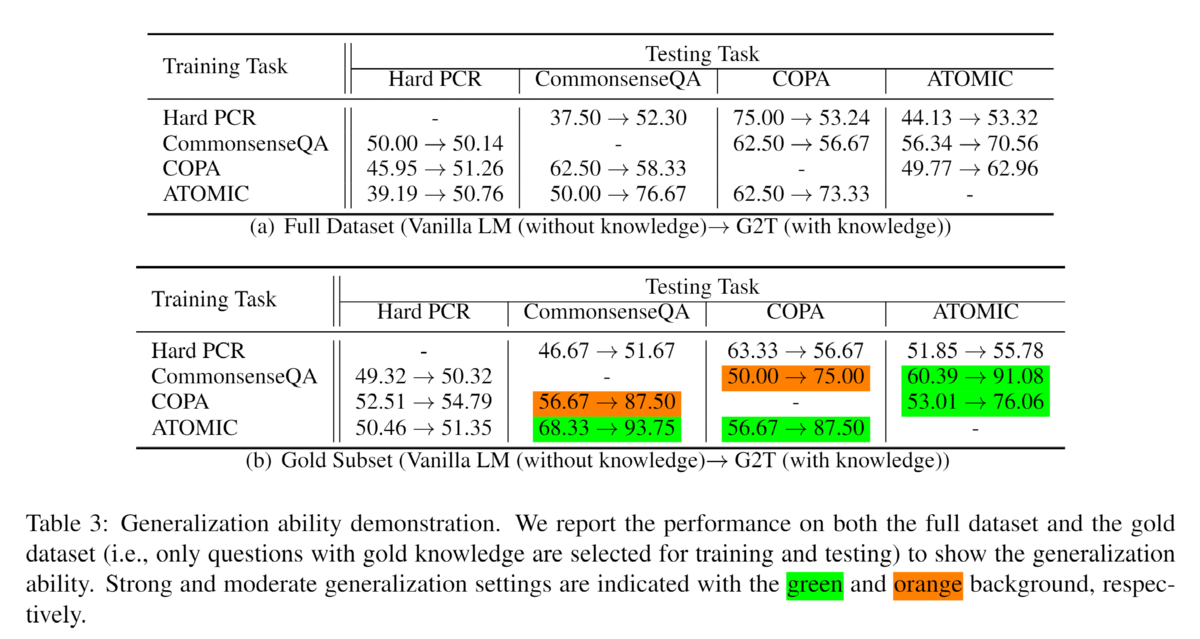
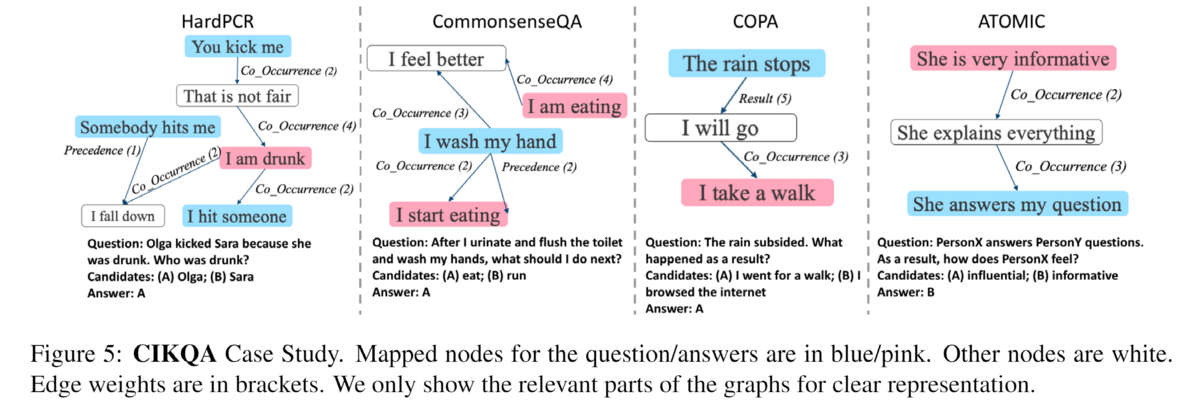
この結果から、知識はCommonsenseQA、COPA、ATOMICの間でモデルをうまく汎化するのに役立つことがわかる。唯一の例外はHardPCRである。これは主に、HardPCRを解くために必要な推論が他のタスクよりも複雑であるためで、関連する知識を見つけるだけでなく、対象の代名詞を提供された知識内のエンティティに置き換える必要がある。 図5に示すように、(1)"I am drunk"→Co_Occurrence→"I hit someone"、(2)"I am drunk"→Co_Occurence→"That is not fair"→Co_Occurence→"You kick me"、の2つの経路が質問に関連していることがわかる。 正しい推論を行うためには、いつ衝突が発生するかを知る必要があるが、2ホップの追加ノードが余分なノイズをもたらす可能性があるため、1ホップの推論をより信頼すべきである。その点、他のタスクでは、関連するパスを見つけることが主な推論であり、これは比較的簡単である。 このような複雑な推論を行うことを学習できるモデルをどのようにトレーニングするかは、今後の課題である。
一般に、CIKQAで良いモデルを学習することができれば、推論の種類が限られているという仮定に基づいて、必要な推論の種類がCIKQAによってカバーされている限り、どんな常識的な推論課題も解決できる可能性があるため、観察された一般化能力は有望である。同時に、ゴールド知識エッジが提供された場合、モデルがよりよく生成されることもわかり、ゴールド知識識別タスクの重要性がさらに証明された。
5. 関連研究
機械が常識を理解するために、クラウドソーシング(ConceptNet (Liu and Singh,2004) やATOMIC (Sap et al., 2019) など)や情報抽出技術(ASER (Zhanget al., 2020a) など)を用いて常識的知識ベースを構築することに大きな力を注いでいる。一般的に、クラウドソーシングの知識ベースはより高品質であり、自動構築されたものはより広い範囲をカバーすることができる。常識的知識の習得に加え、モデルの常識的推論能力を訓練・テストするために、コミュニティは多くの常識的推論データセットを開発した。 これらのデータセットは,形式(例えば,Winogrande(Sakaguchi et al, 2020)のスロットフィッティングやCommonsenseQA(Talmor et al, 2019)の質問応答),知識タイプ(例えば,COPA(Roemmele et al, 2011)の因果コモンセンスやNumerSense(Lin et al, 2020)の数値的コモンセンス))、またはモダリティ(例えば、VCRの視覚的コモンセンス(Zellers et al., 2019)や他の多くのテキスト的コモンセンス)が異なる場合があるが、標準的な教師あり学習設定に従い、機械が特定の常識課題をエンドツーエンドで解決できるようになることを目指している。このような環境では、トレーニングで何を学んだのかがわからないことが多い。常識的な知識を得るためなのか、常識的な推論を行うことを学ぶためなのか、あるいはその両方なのか。このような曖昧さは、常識的な推論の課題を解決する上で、私たちの進歩を制限するものである。本研究では、常識的推論ベンチマークCIKQAを作成することで、常識の獲得と推論に関する取り組みを結びつけ、モデルがゴールド知識を識別するための学習と、それを支える常識的知識に対する推論を行うことに焦点を当てる。
知識ベース(KB)に基づく自然言語の質問に答えることは、NLPコミュニティにおける成熟した研究テーマであり、KBQA問題としても知られている(Clark et al., 1999; Yihet al., 2015, 2016; Usbeck et al., 2017; Cui et al.,2017)。 これまでの研究では、主にトリプレット形式で保存される事実知識に焦点が当てられている。主な課題は、質問を解析し、推論を行うために大規模なKB上の正しいパスを正確かつ効果的に特定することである。事実知識に対する推論と比較して、常識知識に対する推論は以下のようなユニークな課題がある。 (1) 常識とは、固定した知識ではなく、一種の嗜好である。 そのため、理想的な常識的推論プロセスには、複数の候補を比較することが含まれうる。例えば、「コーヒーを飲む」と「熊を飲む」はどちらも朝に起こりうるが、普通の人は「コーヒーを飲む」を好むだろう。(2) 名前付きエンティティだけでなく、日常的なエンティティやイベントも対象となるため、質問にマッチするノードをコモンセンスKBから正確に見つけることが難しく、部分一致(抽出されたノードは関連するが同一ではない)に基づく推論が必要となる場合がある。
6. 結論
本論文では、統一的なコムナンセンス推論ベンチマークであるCIKQAを紹介する。 具体的には、まず、いくつかの一般的なコモンセンスタスクを統一されたQAフォーマットに変換し、次に、各クエスチョンにサポートするコモンセンス知識グラフを装備している。また、自動抽出された知識の品質をアノテーションするために、人間を活用している。実験によると、モデルが少数の例で常識的な推論を行う方法をよりよく学習し、データが乏しい環境において構造化知識を使用しない基本的な方法を大幅に上回ったとしても、ゴールド知識エッジを特定することは依然として困難な問題であることが示された。さらに興味深いことに、我々の統一的な定式化により、モデルはタスク間の汎化能力を発揮することができるようになった。フォーマット統一とグラフ抽出のサポートが自動化されているため、将来的に他の常識的推論タスクに容易に拡張することが可能である。
今日の論文2023/05/07,8:Human Evaluation of Conversations is an Open Problem: comparing the sensitivity of various methods for evaluating dialogue agents
Human Evaluation of Conversations is an Open Problem: comparing the sensitivity of various methods for evaluating dialogue agents
Eric Smith, Orion Hsu, Rebecca Qian, Stephen Roller, Y-Lan Boureau, and Jason Weston. 2022. Human Evaluation of Conversations is an Open Problem: comparing the sensitivity of various methods for evaluating dialogue agents. In Proceedings of the 4th Workshop on NLP for Conversational AI, pages 77–97, Dublin, Ireland. Association for Computational Linguistics.
©2022 Association for Computational Linguistics
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容に基づき筆者が要約または翻訳したものです。以下の図は、そこから引用しています。
This article is my summary or translation based on the content of the original publication. The following figures are taken from it.
要点まとめ
会話型AIの改良の中心は、会話をどのように評価するかという未解決の問題である。 自動評価基準の問題はよく知られており(Liu et al., 2016)、人間による評価が依然としてゴールドスタンダードと考えられている。
残念ながら、人間による評価をどのように行うかも未解決の問題である。データ収集方法が異なれば、人間の同意や統計的感度のレベルも異なり、その結果、人間のアノテーションにかかる時間や人件費も異なる。
この研究では、5種類のクラウドワーカーベースの人間評価方法を比較し、比較するモデルの種類によって最適な方法が異なり、全体として明確な勝者はいないことを発見した。この分野の未解決の問題を明らかにする一方で、我々の分析は、いつどの方法を使うべきか、将来の可能な方向性へのアドバイスにつながっている。
序論
オープンドメインの会話モデルの性能に関する包括的な分析には、人手による評価が含まれる必要がある。自動指標はモデル性能のある側面を捉えるが、モデルが現実的で興味深い会話にどの程度長けているかを人間の評価者が判断することに代わるものではない(Deriu et al., 2021; Liu et al., 2016; Dinan et al., 2019b)。残念なことに、人手評価というものは、良い会話士に求められるすべての側面を捉えるために、慎重に構築されなければならないのである。どのような評価手法であっても、繰り返したり矛盾したりするような新たな欠点を発見するためには、何度も会話を繰り返して評価する必要があり、一方、会話の最後に1回だけ評価する手法では、会話期間中のモデル性能の変化を考慮できない可能性がある。さらに、モデルの性能をリッカート尺度で評価する技術では、異なるモデルの評価間で主観的な数値評価の矛盾が生じる可能性がある(Liet al, 2019)。また、様々な人手評価手法を比較検討した結果、それぞれに成功例と失敗例があり、人手評価はまだまだ未解決の問題であるとの結論に至った。
本研究では、代表的な人間による評価技術を分析する。まず、モデルの応答ごとに評価を行うターンごとの評価と、会話の最後だけ評価を行うダイアログごとの評価を比較する。ターンごとの評価では、より細かい設定が可能で、注釈者が小さな違いに注目しやすいという利点がある。しかし、会話の質はその部分の総和以上のものであり、グローバルなダイアログごとの評価はこれをよりよくとらえることができる。次に、2つのモデルをアノテーターが直接比較するペアワイズ方式と、アノテーターが一度に1つのモデルだけを見て評価するシングルモデル方式を検討する。どちらのアプローチも、ターンごと、ダイアログごとのいずれかを選択することができる。 例えば、ペアワイズのターンごとの評価では、クラウドワーカーが対話エージェントとチャットし、それぞれのワーカーのメッセージの後に、エージェントからの応答として、2つの異なるモデルからそれぞれ1つずつ、二つの可能な応答を選択しなければならない。ペアワイズアプローチは、回答を比較することでわかる微妙な違いを見つけることができ、絶対評価で発生する分布のずれの問題を軽減することができる。しかし、単一モデルのアプローチは、直接比較することが重要でない場合に有効である。
このように、対話モデルを評価するためのさまざまな手法を、3つの異なる設定で比較し、それぞれの長所を対比している。
ペアワイズのターンごとの評価は、会話中のモデル性能の変化を測定するのに適している。この手法は、例えば、異なるデータセットで学習させた2つのモデルを比較する場合など、2つのモデルのペアが、前の対話の文脈の中でどの程度適切な応答をしているかが明らかに異なる場合にうまく機能する傾向がある。
モデル間の差異が非常に微妙な場合など、数回の会話で初めて明らかになる場合や、応答の平均長さなど、会話全体でグローバルに現れる応答のパターンに注目する場合、ペアワイズによる対話ごとの評価が最適となる傾向がある。
単一モデルの評価は、会話ごとに行われる場合と会話の最後に行われる場合の両方で、先に述べた2つの設定ではあまりうまくいかない傾向があるが、例えば、パラメータの数が異なる2つのモデルなど、品質がわずかに異なるだけでそれ以外は似ているモデルを比較する場合には、うまくいく。
これらの結果は、人間による評価の難しさを浮き彫りにすると同時に、これらの異なる状況下でどのような手法を用いるのが最適か、また、今後の課題についても指針を与えてくれる。特に、ペアワイズとシングルモデル、ターンごととダイアログごとの利点を一つの手法に統合する最善の方法を調査することは、実りある方向性となりうる。また、人間が書いた説明文を収集する際に、これらのアプローチの解釈可能性を分析する。これらの評価手法のコードをParlAIフレームワークで公開している。
先行研究
この研究は、質問応答や目的指向の会話など、より制限された領域とは異なり、正確な目標を持たないオープンドメインの対話の評価に関するものであり、そのための広く受け入れられた評価手法は現在のところ存在しない(Deriu et al., 2021; Huang et al., 2020; Roller et al.2020)。自動評価指標は比較的速く、効率的で、再現性が高いが、その多くは「人間の判断との相関が非常に弱い」ことが示されており(Liu et al., 2016, Dinan et al.(2019b)も参照)、信頼できる自動評価指標を作る最善の方法はまだ議論されている(De-riu et al., 2021)。この研究では、人間による評価、特にクラウドワーカーの活用に焦点を当てている。これは、訓練された専門家(Deriu et al., 2021)や配置(Gabriel et al., 2020; Shuster et al., 2020)を利用するよりも、評価者のプールを増やすことができ、研究目標との整合性を確保することができるという利点がそれぞれある。しかし、クラウドワーカーの利用自体にも避けるべき落とし穴がある(Huynh et al, 2021)。
クラウドワーカーへの特定の指示文言の選択は、会話の質と結果の評価に大きな影響を与える(Huynh et al., 2021)。例えば、一般的な「お互いを知る」雑談(Zhang et al., 2018)、ボットに安全でない発言を生成させる(Xu et al., 2020)、クラウドワーカーに敵対するかしないかを指示する(Dinanet al., 2019a)、などの特定の面を評価するようにワーカーに指示することができる。また、クラウドワーカーに会話の内容を尋ねる際に、関心度、意味、流暢さ(See et al, 2019)、感性、特異性(Adiwardana et al, 2020)、毒性、バイアス(Xu et al, 2020)など様々な特定の質問を選ぶことができ、これらの質問の正確な言い回しは感度に大きな影響を与えることがある(Li et al, 2019)。標準的な評価プロトコルでは、1人の人間が同じタスクでモデルと会話し、その会話を評価するが、他の方法では、評価者が人間とモデルの間の既存の会話、または2つのモデルの間の会話を評価する(Li et al., 2019; Deriuet al., 2020)。これらの後者の手法は、既存の会話データを効率的に再利用することができ、実験的に有用であることが示されている(Li et al., 2019; Roller et al., 2021)が、評価者が自分が関与していない会話を評価することは難しいかもしれない。
評価プロトコール設計時のもう一つの選択は、会話を個別に、例えばリッカートスコア評価で評価するか(Ashwin et al., 2017;Venkatesh et al., 2018、詳細は付録Aを参照)、モデルを比較してペアワイズで評価するか(Li et al., 2019;Liang et al., 2020, など)である。リカートスコアリングは、注釈者ごとのバイアス(Kulikov et al., 2019)や時間経過による誤差の分布のドリフト(See et al., 2019)などの弱点を抱えているが、新しいモデルの評価を古いモデルの評価と比較できるため、古いモデルの評価を再度収集する必要がなく、ペアワイズ比較よりも効率が良い。
最後に、評価技術は、会話のターンごとに評価を集めるのか(Adiwardana et al, 2020; Komeili et al, 2021)、またはAcute-Eval(Li et al, 2019)のように会話の最後だけ評価を集めるのかで異なる。 会話全体の技術というのは、会話の質がその部分の和以上のものであると想定される場合には有効であるが、評価セッションの開始時と終了時に提示された情報にそれぞれ重みがある場合に現れる、プライマシー効果やリテンシー効果のために苦しむ可能性がある(Asch, 1946; Anderson, 1965; Murdock Jr, 1962; Postman and Phillips, 1965)。
関連研究のより詳細な評価については、付録Aを参照。
方法
評価技術
既存の研究で議論されているさまざまな方法の横断的な範囲にまたがる、いくつかの人間評価技術を調査する。

シングルモデル vs. ペアワイズ、そしてターンごと vs. ダイアログごとの評価方法のバリエーションを比較するとともに、セルフチャットの方法を従来の人間-ロボット会話評価と比較した。図1に各手法の概要を示す。これらの評価を行う際に使用した品質チェックの詳細については、付録B.3に示す。
会話設定
人間とロボットの評価は、一連の会話で構成されている。会話は、Amazon Mechanical Turkからクラウドソーシングされた人間(「Human Speaker」)と、変換モデル(「Bot Speaker」)で構成されている。 会話は、スピーカーが自然に話し、会話開始時に渡される2つのペルソナ文を使って、ある人物になりきってロールプレイングを行う。図2(左)に例を示す。

会話におけるHuman Speakerの最初のメッセージは、Adiwardana et al.(2020)の慣例に従い、"Hi!"に固定される。 Rollerら(2021)のBlenderBotの評価に使われた会話の長さとほぼ同じになるように、Human SpeakerとBot Speakerがそれぞれ6ターン話した後に会話が終了する。ここでは、「好み」「人間らしさ」「面白さ」という3つの評価指標を検証している。
ペアワイズのターンごとの評価
PW-Turn(Pairwise Per-Turn evaluation)技術では、メッセージの送信ごとにクラウドワーカーにペアのモデル回答から選択させることで、会話のターンごとにアノテーションをする。したがって、この設定では、Human SpeakersはBot Speakerに話しかけ、後者は実際に比較される2つのモデルを表している。人間のスピーカーは、会話の中で自然に話すことができる。ボットスピーカーが発言する順番が回ってくるたびに、クラウドワーカーにはまず、可能な限り2つの選択肢が提示される。それぞれの応答は、Clark and Smith (2021)と同様に、比較される2つのモデルのどちらか一方から得られる。これらのモデル回答の順序をランダム化する。作業者は、与えられた評価指標に対して、より良い回答を選択しなければならない。3つのメトリクスに使用する語句は、Li et al.(2019)から引用している。
好み(Preference)「長い会話の中で、相手の次の反応はどれがいい?」
人間らしさ(Humanness)「次の相手の反応は、どちらが人間らしく聞こえますか?」
面白さ(Interestingness)「これらの回答のうち、1つは興味深く、1つはつまらないものだとしたら、どちらがより興味深いと思いますか?」
作業者は、選択した回答について、自由記述で正当な理由を述べなければならない。そして、その応答がボット・スピーカーの実際の応答となり、そこから会話が続いていく。図2は、UIの画面例である。この評価手法のためにワーカーをオンボーディングする際に行われた品質チェックの説明は、付録B.2に記載されている。実験では、単純にターン数を平均した勝率と、ダイアログ全体のターン数結果の非線形な組み合わせ(勝者総取り投票など)を考慮し、その影響を測定している。
ペアワイズのダイアログごとの評価
今回紹介するPW-Dialog(Pairwise Per-Dialogue Evaluation)は、評価者に2つのモデルの対立軸を提示し、どちらかを選んでもらう手法である。 私たちが採用した手法はAcute-Eval法(Li et al, 2019)と同じだが、他の手法の名称との整合性のために、ここではPW-Dialog評価と呼ぶことにした。モデルペアと評価指標ごとに、(1)クラウドワーカーとモデルエージェントの会話、(2)同じモデルの会話エージェント同士の自己チャット(自己チャットバリアント)の評価を収集している。私たちが使用する質問(Li et al(2019)より)は、PW-Turnとほぼ同じであるが、ターンごとの場合ではなく、ダイアログごとの場合の言い回しになっている。
好み(Preference)「長話をしたい相手は?」
人間らしさ(Humanness)「どちらのスピーカーがより人間らしく聞こえるか?」
面白さ(Interestingness)「このスピーカーのうち、一人は面白く、一人はつまらないと言われたら、どちらの方が面白いと思いますか?」
図3にUIのスクリーンショット例を示す。

シングルモデル評価
単一モデルの評価実験では、ターンごととダイアログごとを同じUIに統合した(スクリーンショットは図4参照)。クラウドワーカーは、1つのモデルによる会話エージェントとチャットし、そのモデルの各レスポンスについて、それが魅力的か、人間的か、興味深いかを、スクリーンショットに記載された文言で注釈する必要がある。1人のスピーカーにつき6メッセージで構成されるコンバーションが終わると、ワーカーは、セクション3.1.2に記載されている3つの評価指標それぞれについて、1~5のリッカート尺度でパートナーを評価しなければならない。このタスクで得られたモデル応答のターンごとの注釈をSingle-Model Per-Turn evaluations (SM-Turn) と呼び、会話終了時のリッカートスコアをSingle-Model Per-Dialogue evaluations (SM-Dialog) と呼ぶ。

経験的に、SM-Turnの成功率やSM-Dialogのリッカートスコアは、評価を収集した特定の日に大きく依存することがわかった。これは、おそらくクラウドワーカーのプールの日ごとの変動に起因している。これを打ち消すために、本研究(セクション3.2)で議論した4つのモデルすべてについて、同時に評価を実施した。
モデル
Rollerら(2021)の4種類の対話モデルについて、SM-Turn、SM-Dialog、PW-Turn、PW-Dialog、PW-Dialogself-chatという5つの人間評価手法の相対性能を分析する。
BlenderBot3B:BlenderBotの一種で、27億のパラメータを持ち、既存のRedditデータセット(第三者によって抽出・取得され、pushshift.ioで利用可能(Baumgartner et al., 2020))で事前学習を行い、その後いくつかの目的別の対話データセットでファインチューンを行った。
BlenderBot3B-M0: BlenderBot3Bは、比較的長く、興味深い応答を保証するために、20トークンの最小生成長を使用している。また、全く同じモデルで、最小世代長を持たないモデル(M0を付けてと表記)とも比較している。
BlenderBot90M: BlenderBot3Bの一種で、9000万個のパラメータを持ち、同じデータセットで学習している。
Reddit3B: BlenderBot3Bだが、サードパーティのRedditダンプで事前学習しただけで、対話データセットでファインチューニングはしていない。
すべてのモデルについて、M0適応を除けば、Rollerら(2021)と同じ生成設定を使用する。評価技術にとって、どれがベストかを見分けるのは難しい課題として、実験ではこれらの比較的似たモデルを選びましたが、Rollerら(2021)の過去のAcute-Eval(PW-Dialog)による自己チャット測定から、BlenderBot3Bは他の3モデルと同等かそれ以上に性能が高いのではないかと先験的に予想している。 3つのペアワイズ評価手法では、具体的には、特徴的な違いがある3つのモデルのペア間の比較を行う。
長さの比較: Blender-Bot3BとBlenderBot3B-M0を比較すると、これらのモデルの違いは生成文の長さのみである。
サイズ比較: パラメータ数の異なる2つのモデル、Blender-Bot3BとBlenderBot90Mを比較する。
ファインチューニングの比較: ファインチューニングしたBlenderBot3Bと事前学習のみのReddit3Bを比較(どちらも同じパラメータ数)。
結果
ペアワイズのターンごとの評価からモデルの勝率

ペアワイズ評価技術PW-Turnについて、BlenderBot3Bの他モデルに対する勝率を表1に計算した。Blender-Bot3Bの方が優れていると思われるので、100%に近い値がより好ましいと判断される。 4種類のバリアントの勝率を表示する。ボットスピーカーの6回の会話ターンをすべて含み、ボットスピーカーの最初のターンを評価から除外し、ターンの非線形関数を計算する。 会話ごとに2乗または勝率を計算し、そのスコアをすべての会話で平均化する。付録C.2で詳しく説明するように、Bot Speakerの1ターン目を落とすとPW-Turnの勝率が高くなることが一般的に分かっている。クラウドワーカーがどのモデルの回答を選択するかというターンごとの変動が少なくなるため、勝率は通常、勝者総取り方式で会話に集約され、さらに高くなる。
一般に、Blender-Bot3Bの勝率は、作業者に1つのモデル回答を選択させる際に使用する評価質問の関数としてあまり変化しないことが分かった。これは、作業者が解釈する際のこれらの質問・指標の正確な定義が曖昧なためなのか、ある指標と他の指標でモデルの性能が相関しているのか、あるいは他の理由なのか、先験的には不明である。
シングルモデル評価によるモデルスコア

表2は、全モデルのターンごとの成功率(SM-Turn)と会話終了時のリッカートスコア(SM-Dialog)を示している。 セクション4.1やRollerら(2021)のペアワイズ評価と同様に、BlenderBot3BはSM-TurnやSM-Dialogメソッドを用いた他のモデルよりも概して優れている。表5(付録)は、SM-Turn技法による成功率を、(集計ではなく)会話の順番の関数として示したものである。BlenderBot3Bのスコアは、会話ターンによって概ね安定しているが、Bot Speakerの最初の2ターンでわずかに低くなっており、付録C.2のPW-Turnと同様の結果が得られていることを反映している。そこで、BlenderBot3Bの性能を他のモデルに比べて最大化するために、最初の2ターンからSM-Turnスコアを削除することも検討した。 PW-Turnと同様に、ダイアログごとの勝敗スコアを計算することで、BlenderBot3Bと他のモデルとの性能差がさらに大きくなることがわかる。 PW-Turnは3つの評価指標で勝率がほぼ同じであるのに対し(4.1項)、「面白さ」の評価指標での単一モデルの成功率は他の2つの評価指標よりも低く、特にSM-Turnでは顕著であった。SM-TurnとSM-DialogのクラウドワーカータスクのUIに、3つの評価項目を並べて表示することで、ワークワーカーが3つの評価項目を区別してモデルを評価するのに役立つのではないかと考えている(図4)。

ワーカーの最終的なリッカート尺度による評価に、どのような会話の展開が最も強く寄与しているかについては、付録 C.4 を参照されたい。
すべての評価手法の直接比較
このセクションでは、すべてのペアワイズおよびシングルモデル評価技術を直接比較し、その相対的な強さを見分ける。 技術ごとの評価実施回数、クラウドワーカーの活動時間の詳細については、付録C.1を参照されたい。
すべての技法における勝率を計算する
SM-TurnとSM-Dialogの性能をペア技と直接比較するために、異なるモデルの評価のサンプルをブートストラップし、あるモデルのSM-Turn成功率とSM-Dialogのリッカートスコアが他のモデルより高い頻度を計算することによって、2つのシングルモデルの技法の有効勝率を計算する。 4.1節と4.2節のベストパフォーマンス手法の分析に続き、異なるモデルのパフォーマンスを区別するために、これらの手法の能力を最大にするために、PW-TurnではBot Speakerの第2ターンから第6ターン、SM-Turnでは第3ターンから第6ターンをWinner-takes-all(WTA)モードでのみ検討する。
表3は、全ての評価技術によって生み出される勝率を比較したものである。 全体として、3つのモデルの比較では、それぞれ異なる手法が最適であることがわかった。

長さ比較 PW-DialogとPW-Turnのペアワイズ評価手法は、単一モデルの評価手法よりもはるかに優れた性能を発揮する。BlenderBot3Bの応答は、BlenderBot3B-M0の応答よりも平均して多くの単語を含む傾向があり、この技術間の感度の違いは、両モデルの応答を並べて見ることで、特にPW-Dialogのように2つの会話中の会話を比較する場合に、両者の長さの違いがより明確になることによるものではないかと推測している。このように、クラウドワーカーが平均的に長い回答を好む傾向がある場合、モデルの回答を並べて比較することで、BlenderBot3B-M0よりもBlenderBot3Bの回答を選ぶことができるようになるかもしれない。
サイズ比較ここでの技術間の差は、長さの比較よりも小さく、完全対話技術のPW-DialogとSM-Dialogは、パーターンの技術よりもわずかに優れている。 Rollerら(2021)が示したように、BlenderBot3BとBlenderBot90Mは、自己チャット会話におけるAcute-Evals(すなわちPW-Dialog)において、統計的に有意な差のあるパフォーマンスを示さない。したがって、これらのモデル間の性能のわずかな差は、会話全体のレベルではより明白であることが理解できるかもしれない。
ファインチューニング比較この比較では、PW-Turnがすべての手法の中で最も良い結果を出している。 Reddit3Bのモデルは会話データセットで微調整されていないため、パートナーに対する反応はBlenderBot3Bの反応よりも文脈的に意味をなさないことが一般的である。PW-Turn評価において、Bot Speakerと会話している最中のワーカーには、このような無意味な回答が非常にわかりやすいのだろうと推測している。しかし、PW-Dialog評価で会話全体を読む作業者はモデルと直接対話したことがないため、また、SM-TurnやSM-Dialog評価では、Reddit3Bと対話でファインチューンされたモデルの応答を直接比較できないため、これらの応答はあまりわからないかもしれない。
実験における説明可能性:クラウドワーカーによる理由の分析クラウドワークスの評価作業では、クラウドワーカーが判断した理由も聞いている。これらの理由は、結果に解釈の幅を持たせることができる。完全な分析は付録C.5に記載されている。例えば、長さの比較では、「情報」や「詳細」といったキーワードがよく出てくる。ファインチューニングの比較では、「flow」「personal」「contradicts」といったキーワードが多く、Persona-Chatのようなファインチューニング会話データセットが、よりパーソナルで矛盾が少なく、流れるように会話することを意味している。
実験の再現性付録C.6では、各評価技術におけるモデル勝率の経年変化について分析を行っている。全体として、PW-Turn、PW-Dialog、SM-Turnの3つはチャンク体験の中で最も変化が少なく、SM-Dialogはより変化が大きいことがわかった。このため、SM-Dialogの使用は説得力に欠ける。
全体を通した発見
これら3つのモデルの比較結果から、パートナーに発見されやすい方法で賢明な返答をする能力に差があるモデルのペア(BlenderBot3BとReddit3Bなど)にはターンごとの評価手法が適しているかもしれないが、モデル間の差がより敏感な場合には会話全体の手法が望ましいかもしれないことが示唆された。しかし、このような広範な仮説を十分に裏付けるには、もっと多くのペアのモデルで評価する必要がある。また、モデルの生成文が平均的な長さで異なる場合を除き、シングルモデル手法はペアワイズ手法と比較して競合することがわかった。この場合、両者の反応を並べて見ることで、別々に見るよりも両者の違いがより明確になるかもしれまない。
技法の組み合わせまた、異なる評価手法の感度がモデルのペアによって大きく異なることから、複数の手法の結果を組み合わせることで、すべてのケースで合理的な性能を発揮するコンプロマイズ手法が可能かどうかも検討した。そこで、PW-TurnとPW-Dialogの評価を1:5の割合で一緒にサンプリングした場合の勝率(「PWコンボ」)を表3に含めている。 このサンプリングは、PW-DialogがBlender-Bot3BとBlenderBot3B-M0、BlenderBot90Mを素早く比較する能力(長さとサイズの比較)をほとんど維持し、PW-TurnがBlenderBot3BとRed-dit3Bの性能を測定する優れた能力(微調整の比較)も維持する。
一方、SM-TurnとSM-Dialogという2つの単一モデルの技法のレーティングは同時に収集されるため、ある会話に対する両方の技法のレーティングを平均化することで、それぞれの技法が個別に行うよりもわずかに細かい感度を実現することができる。図11、図12、図13に示すように、適切な重み付けをすれば、平均化によって、SM-Dialogだけよりも少し速く、SM-Turnだけよりも劇的に速く、モデル間で統計的に有意な差が出ることがわかる(付録C.8)。
勝率だけでなく、様々な評価手法の有用性を直接比較するもう一つの方法は、統計的に有意な結果を得るためにクラウドワーカーが評価に費やさなければならない工数を推定することである。これらの結果(図8、図9、図10)は、勝率(第4.3.1項)のパターンにほぼ沿ったものであった。これらの時間推定を行う際の仮定については、付録C.7を参照のこと。
結論
本研究では、異なる評価手法が対話モデル間の性能差をどの程度測定できるかを比較し、ターン単位の手法と対話単位の手法、ペアワイズの手法とシングルモデルの手法で性能差が生じる例を示す。各技術が最も適しているケースを完全に網羅的に分析するには、今回調査した3つのモデルよりも多くのペアで測定する必要があり、クラウドワーカーの労働力を飛躍的に向上させる必要があると思われる。
しかし、この結果は、比較対象がどのモデルであっても、1つの評価手法が他の手法よりも優れていると断言することの難しさを示しており、モデル間の差異を最適に測定するためには、複数の手法を組み合わせる、あるいは全く別の手法が必要であることを示している。より普遍的で理想的な手法としては、1回の回答で最も明確に現れる性能の要素を捉えるために、ターンごとのモデル性能を調査しつつも、コンバージェンス全体でモデルの品質を総合的に判断できるようにする必要があると思われる。ターンごととダイアログごとの評価スコアを組み合わせることで、両者の性能差のギャップを埋めることができることを示したが、少なくとも組み合わせた方法では、すべてのケースでどちらかの個別技術を上回ることはできない。
将来的には、BlenderBot3BとBlenderBot90Mのようなわずかな性能差しかないモデルの弱い信号を増幅する別の方法を模索したり、個人的な興味に訴えるコンテンツではなく、会話の質の一般的な尺度に基づいて回答を選択するように作業員を訓練することで、改善できるかもしれない。このようなほぼ等価なモデルの感度を向上させることで、より性能差の小さいモデルの比較も可能になるはずである。
この研究は、区別可能性(モデル間の区別が可能)と効率性(アノテーターに時間をかけない)を可能にする技術の評価に集中してきたが、他の望ましい性質もある。特に、会話の多様性(Hashimoto et al, 2019)、実験の再現性、結果の説明可能性(Deriu et al, 2021)などがあげられる。私たちの実験では、後者2つのトピックについていくつかの議論がなされているが、これらのトピックは、ここで提供されるよりももっと徹底した分析に十分に値するものである。
今日の論文2023/05/04,05:Long-term Control for Dialogue Generation: Methods and Evaluation
Long-term Control for Dialogue Generation: Methods and Evaluation
Ramya Ramakrishnan, Hashan Narangodage, Mauro Schilman, Kilian Weinberger, and Ryan McDonald. 2022. Long-term Control for Dialogue Generation: Methods and Evaluation. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 738–753, Seattle, United States. Association for Computational Linguistics.
©2022 Association for Computational Linguistics
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容に基づき筆者が翻訳したものです。以下の図は、そこから引用しています。
This article is my translation based on the content of the original publication. The following figures are taken from it.
要点まとめ
現在の対話応答生成制御のアプローチは、主にスタイル、センチメント、トピックなどの高レベルの属性に焦点を当てている。 本研究では、よりきめ細かい制御を必要とし、生成された応答に現れる制御語のセットを必要とする、制約された長期対話生成に焦点を当てる。この設定では、制御語の発生を直近の文脈で考慮するだけでなく、(もしかしたら遠い)将来のある時点で制御語の発生を促すような発話を生成するモデルが必要である。
我々は、対話生成のための制約された長期制御の問題を定義し、現在の評価方法のギャップを明らかにし、長期制御をより良く測定する新しいメトリクスを提案する。また、ロジット修正技術により長期制御生成の性能を向上させる、検索を利用する手法(retrieve-augmented method)も提案する。我々は、3つのタスク指向の対話データセットでの実験を通して、我々のメトリクスが現在の選択肢と比較して対話制御をより良く評価し、我々の方法がSoTAの制約付き生成ベースラインを上回ることを示す。
序論
対話システムにおける最近の進歩(Ser-ban et al., 2016; Ham et al., 2020)にもかかわらず、対話生成の制御(controlling)は依然として大きな課題である。対話における応答生成は、異なるトピックやスタイルに向けて(Madotto et al., 2020)、あるいは一連のハードな制約(すなわち、語彙的な制御語が生成テキストに現れる必要がある)に向けて制御できる(Sha, 2020)。我々は、よりきめ細かいダイアログの制御方法を提供する、制約付き生成(constrained generation)として知られるハードな制約に焦点を当てる。
例えば、顧客サービスのユースケース(図1)を考えよう。ここでは、エージェントがある問題について顧客と会話する。目標は、一方の話者(エージェントまたは顧客)の応答において、与えられた制御語のセットを生成することである。ナイーブ制約付き生成アプローチ(Pascual et al.,2020; Miao et al., 2019)は、ビームサーチやストキャスティックサーチのような方法を用いて、制御語が単一のユータンスやフレーズに出現する必要がある短期制御のためにこれらの制御語の生成を強制する。将来のことを考慮していないため、これらのアプローチでは、1回の応答で一気に単語を生成したり、会話の中の自然な場所で単語を生成しないことがある(図1左)。

上記の例は、既存の制約付き生成メソッドを長期対話生成に適用することの課題を強調している。まず、対話には他の話者が参加しているため、モデルは生成されるテキストを完全に制御することはできず、モデルは間接的にしかダイアログを制御することができない。第二に、対話は長くなりうるため、数タイムステップ先の発話を制御することは、非自明である。そこで、本研究では、長期的な対話制御の問題を提案する。この問題では、対話の多くの発言に対して制御語のセットを生成することを目標とし、制御語の生成タイミングを適切に調整する必要がある(図1右)。我々の知る限り、語彙的な制御語によって長期的な対話の生成を制約する研究は、我々が初めてである。
まず、この問題の評価に関する課題を明らかにする。対話の長期的な制御を成功させることは、測定が困難な場合がある。 我々は、制約付きテキスト生成のための現在の評価指標を定義し、これらの指標は、会話の初期にすべてまたは多くの制御語を生成することによって、危険にさらされる可能性があることを示す。この問題を解決し、制御がどの程度自然であるかを測定するために、我々は指標として、長期成功率(会話のロールアウトのシミュレーションにおける制御語の割合を測定する)とprecision、recall、F1スコア(生成された応答における制御語と過去のデータセットからの参照応答におけるそれらを比較する)を提案する。これら2つ目の指標は、制御語が適切なタイミングで生成されているかどうかを把握するためのものである。
次に、長期的な制御を明示的に扱う新しい方法を提案する。 先行する手法では、可能な未来のシーケンスの数が指数関数的であるため、このタスクを処理することは不可能である。この問題を解決するために、我々はトレーニングから類似の会話を取り出し、生成時にそれを条件とする。まず、kNNベースのアプローチを用いて類似近傍を特定し、次に、plug-and-play手法(Madotto et al., 2021; Dathathri et al., 2019; Pascual et al., 2020)に触発されて、言語モデルを類似の応答を生成するように誘導する。 これは、検索された会話から、より自然なタイミングで制御語を生成するようモデルを誘導するためである。
我々は、複数のタスク指向の対話データセットで実験を行い、我々の方法が、自動評価指標と人手評価において、いくつかの制約付きテキスト生成ベースラインを凌駕することを明らかにする。具体的には、人間による評価で流暢さを維持しながら、長期的な成功率でベースラインと比較して30-40%多くの制御語を生成することができた(5点満点中4.3点以上)。
関連研究
制御可能なテキスト生成:先行研究により、制御可能なテキスト生成のための多くの方法が開発されている。これらのアプローチは、3つの一般的な領域に分類することができる。1つ目は、デコーディング戦略を変更すること(Grover et al., 2019; Deng et al., 2020)で、サンプリング分布を変更したり(Ghazvininejad et al., 2017; Baheti et al., 2018)、モデル内の隠れた状態を変更したり(Gu et al., 2017)する。 第二の領域は、テキスト生成をガイドするプロンプトを含んでおり(Ribeiroet al., 2018; Jiang et al., 2020; Li and Liang, 2021)、例えばユニバーサルトリガートークンによる(Wal-lace et al., 2019; Shin et al., 2020)を用いる。最後に、ファインチューンは、潜在変数の使用(Fan et al., 2018; Peng et al., 2018)やCTRLコード(Keskaret al., 2019)を通じて言語モデル出力を導くために使用することができる。我々の研究は、1)我々は、語彙的制御語を介して、よりきめ細かい生成を再要求し、2)我々は、別の話者も会話の流れを変更することができる対話の設定に焦点を当てている、という点で制御可能な言語生成の広い領域とは異なっている。
制約付きテキスト生成:制約付きテキスト生成と制御可能なテキスト生成の主要な違いは、ソフトではなくハードな制約に焦点を当てていることである。一般的に、制約付き生成には、ビームサーチ(Hokamp and Liu, 2017; Post and Vilar,2018; Pascual et al, 2020)とストキャスティックサーチ(Miao et al, 2019; Sha, 2020)という2つの生成方法がある。直接的ビームサーチ(DBS:Directed Beam Search)(Pascual et al., 2020)は、言語モデルのロジットを変更し、指定された「ガイド語」または制御語のセットを生成することを促す。ストキャスティックサーチに基づく方法(Miao et al, 2019)は、キーワードの包含を制約条件としてMetropolis-Hastingsを使用する。これらのアプローチは、これらの制約が将来の多くの発話に対して保持される必要がある対話設定には適用されない。
対話応答生成:多くの研究が制約のない応答生成のための方法を開発しているが(Budzianowski and Vuli ́c, 2019; Penget al., 2020; Cao et al., 2020; Hosseini-Asl et al.,2020; Yavuz et al, 2019)、応答生成の制御に焦点を当てた我々の問題により関連した研究がある。Lippeら(2020)は、テンプレート化された応答を言い換えることによって発話を生成している。これは、プロトタイプを介するのではなく、制御語のセットに基づいて生成をガイドしたいため、我々の設定とは異なる。 ある研究(Xu et al., 2019)は、応答の望ましい属性(例えば、応答の長さや特異性)を含むメタワードを通じて応答生成を制御している。また、訓練に誘導的なバイアスを加えて生成を誘導し、制御語によって応答生成を制御する研究もある(Wu et al., 2020)。しかし、この研究は、単一の応答に対してのみ生成を制御するものであり、複数の応答を将来にわたって制御することはできない。我々の研究に最も近いのは、ターゲットとなる題目に対する長期制御という類似の問題を提案する(Tang et al., 2019)による研究である。セットアップは似ているが、我々は、ターゲット属性ではなく、制御語のセットを与えられた対話応答を制約することについて考え、これはまた、異なるアプローチをもたらす。
検索を利用した生成:また、検索を利用した言語生成(retrieval-augmented language generation)も注目されており、検索を利用した対話生成の制御というアプローチにインスピレーションを得ている。REALM (Guu et al., 2020)は、関連文書を特定するために潜在知識検索を用い、この検索ステップをバックプロパゲートする。別の研究(Fan et al, 2020)では、対話の生成を導くために、外部の知識ベースから関連情報を取得する。Khandelwalらによるいくつかの研究は、追加の訓練なしで性能を向上させるために最近傍アプローチを活用している(Khandelwal et al., 2019, 2020)。これらの研究は、制御されていない生成のための検索を条件としているが、我々は、対話における制御のために特別にこのスペースからアイデアを活用する。
問題定義
まず、長期的な制約付き対話生成の問題を定義する。会話は、我々が制御しようとしているシステム
と我々が明確に制御していないユーザ
という2人の話者によって生成される発話のリストとして定義する。
は会話中の総ターン数である。会話
の現在の文脈と、制御語
のセットが与えられた時、我々のゴールは、制御語
が将来生成される応答に現れるように、会話の残りの応答
を生み出すことである。我々は、誰かが会話に含めるべき制御語のセットを、その順序を仮定することなく提供するシナリオを考える。
さらに、会話の履歴データセット ]と、このデータセットに対してファインチューニングされた言語モデル
へのアクセスを仮定する。将来の応答
を制御するために、これらの入力を活用できる。 我々は、plug-and-play設定(Pascual et al, 2020)に焦点を当て、このアプローチでは、追加の再トレーニングなしで、与えられた言語モデル
を制御語の生成に導くだけである。
評価のためのメトリクスの提案
生成された回答を先行する評価手法で直接評価すると、誤った結果を導く可能性がある。制約付きテキスト生成に関する先行研究(Pascual et al., 2020)では、流暢さを測定するためにperplexity、生成された制御語の割合を測定するために成功率のようなメトリクスを使用している。しかし、これらの指標は、会話全体に制御語が自然に分布するような設定でゲーム化することができるため、短期間の生成に適している。図1の左側に示すように、最初の応答で数個の単語が強制されると、会話は望ましい展開から離れ、制御語の生成は不適切なタイミングになる可能性がある。モデルが適切なタイミングで適切な単語を生成する能力をより良く評価するために、我々は以下の新しいメトリクスを提案する。
最初の指標は、長期的な成功率で、ユーザー言語モデルとの会話をシミュレートし、シミュレートしたロールアウトのシステム応答において、生成された制御語の割合を計算するものである。先行研究(Gandeharioun et al., 2019)は、セルフプレイを評価に使用しているが、彼らは対話制御を測定するための手法としてロールアウトを提案していない。
長期成功率:我々の修正成功率メトリックは、会話の完全なシミュレーションロールアウトで発生した制御語の割合として計算される。は将来のシステム応答
の全てに現れる制御語の数であるとして計算される。
長期成功率の限界は、会話における制御語のタイミングを測定していないことである。そこで、次に、会話中の適切なタイミングで制御語を生成する方法を評価したい。 そのために、制御語のPrecision、Recall、F1スコアの計算を提案する。この評価は、シミュレーションでは行わない。その代わりに、評価データセットの真のシステム応答を分離して考え、その時点までの会話履歴を考慮した応答をそれぞれ生成する。 生成された制御語のうち、正しく予測された制御語の数を、同じ時間ステップのground truthの応答の制御語と比較して計算する。
例えば、図1の右側で、2番目の顧客の応答を生成する場合(それまでの真の会話履歴がある)、「シャツ」という単語を含む応答(応答内のどの位置でも)は、その時間ステップのground truth応答に現れる制御単語であるので、P/R/F1の「正しい」予測にカウントされるであろう。 確かに、制御語は会話の後半に現れることもあるが、この設定はすでに長期的な成功率で評価されている模擬ロールアウトである。各レスポンスについて、正しく予測された制御語の数を個別にカウントした後、すべてのレスポンスについて集計する。
Precision:Precisionは、コーパスレベルで、予測された制御語の総数に対する正しく予測された制御語の数として計算される()。
Recall:Recallはコーパスレベルで同様に、実際の制御語の総数に対する正しく予測された制御語の数として計算される()。
F1-score:最後に、F1-scoreはPrecisionとRecallを1つの指標に統合する( )。
これらの指標は、全ての制御語を1つの回答に集約するモデルにはペナルティを与えない。しかし、我々は制御語が関連するときに自然に生成されるようにすることを望んでいる。これらの指標は、制御語が会話中の適切な位置で生成されるかどうかを評価するものである。 柔軟性を持たせるために、ground truthの位置からN回以内の発話に制御語が出現するかどうかに基づいて発話を評価するソフトバージョンのprecision、recall、F1スコアを計算することもできる。
最後に、生成された応答がどれほど現実的で適切かを評価するために人間評価を使用する。具体的には、会話の流暢さ、制御語の生成の一貫性、関連性、コヒーレンス、多様性を評価する。
検索ベースの制御
本論文では、対話生成に制約を与えるアプローチを提案する。検索を利用する生成(retrieval-augmented generation)(Guu et al., 2020;Fan et al., 2020)の研究に触発され、我々は現在の文脈に基づいて類似の過去を検索し、その未来を使って対話応答生成を制御する。ここで重要なのは、人々が過去に類似の会話でこれらの制御語をどのように使用したかを調べることで、より自然な対話にモデルを偏らせることができるという点である。つまり、過去の会話から現在の応答生成の指針を得るのである。この問題で検索を使うことをより動機づけるために、図1の会話例を考えてみる。エージェントは、顧客がどの商品を返品したいかを尋ね、多くの可能な答えがある(例えば、"I want my pant refund.", "I want to return gloves I bought yesterday." など)。 キーワードベースの検索では、制御語であるシャツに関する応答が表示され、モデルはそのワードで自然な応答を生成するように促す。例えば、 “It’s a Nike shirt I bought a week ago."など。
我々は、検索にヒントを得たFutures of the Past (FOP)アプローチの2つのバリエーションを紹介する。1)FOP-retrieval:歴史的データから望ましい未来を検索し、検索された発話を生成された応答として単純に使用する。2)FOP-guided:FOP-retrievalからの発話を参照文として、モデルを同様の応答に誘導する。

我々のアプローチの単純な型であるFOP-retrievalを図2に示す。FOP-retrievalは、将来的に制御語を導き出すために、モデルが今何を言うべきかを特定することに重点を置いている。今、何を言うべきかを特定する必要があるのは、この問題の制御語が長い会話に分散しているためである。 現在の応答を生成する方法として、会話のロールアウトを何度も行い、制御語の数が最も多くなる応答を選択することが考えられる。しかし、この総当たり的なアプローチは計算量が多く、豊かで多様な会話には有効ではない。そこで、過去の会話データを活用し、現在の文脈と制御語から、最も関連性の高い未来を特定する。このようにして得られた未来は、望ましい未来に導くために今何を言うべきか、モデルを導くことができる。図3に示す誘導型は、検索された発話に類似した応答を生成するように言語モデルを誘導するものである。

我々が提案するアプローチは、対話生成のための長期制御の課題のいくつかを解決する。第一に、別の話者が会話の流れを変える可能性があるため、各時間ステップで類似した過去の文脈を新たに取得し、現在の文脈に再整列させることができる。 第二に、何段階も先の応答を制御するために、希望する未来(制御語の割合が高い)を持つ過去の会話を検索し、その方向に会話を誘導することで、現在の発話だけでなく、会話の未来も制御することができる。
過去の未来の検索(FOP-retriveal)
検索コンポーネントでは、制御語に基づいて、関連する過去の文脈を持つ未来と、希望する未来を選択することを目標とする。このために、多段階のアプローチを採用する。まず、履歴データセット中の各会話[tex x^{(i)}]を、過去と未来の会話ペア
のセットに分割する。 言語モデル
を用いて、現在の文脈
と過去の会話
を符号化する。次に、高速最近傍検索ライブラリFAISS(Johnson et al., 2019)に基づくkNNsearchを用いて、現在のコンテキスト
と密接に一致する
個の類似した過去を履歴データから特定する。次に、これらの過去の会話の未来は、制御語の割合が最も高いものに基づいてフィルタリングする。
上式において、count関数は未来に含まれる制御語
の数を数える。参照応答
は単に検索された未来の最初の発話である。
ガイドされた過去の未来(FOP-guided)
参照応答の候補ができたので、同様の応答を生成するよう言語モデルを誘導することができる。そのために、制御語や類似語の生成を促すように、言語モデルからロジットを修正する。我々は
の最初の単語
から始め、DBS(Pascualet al., 2020)に似た方法で、GloVeベクトル埋込みの類似性を利用してロジットをアップウェイトする。
ここで、はGloVe埋め込みを表し、
は言語モデルの語彙
の
番目のトークン、
は現在の参照単語、
は
に類似する単語の生成にどれだけの重みを置くかを指定するハイパーパラメータである。
この方法では、モデルが最初の単語で止まってしまい、それ以降の単語に移らないことがあることが確認された。より柔軟な制御を可能にするために、次の単語に移る前にすべての単語を生成することを要求する代わりに、サイズのウィンドウを含み、ウィンドウ内の各単語の対数を
の減衰倍率で増加させる。ウィンドウ内の単語が生成されたものであれば、ウィンドウは生成された単語から同じウィンドウサイズ
でシフトされる。この作業を、全レスポンスが生成されるまで繰り返す。
この減衰倍率は、モデルが参考回答の早い単語を生成するように促し、可能性が高い場合を除き単語をスキップしないようにするために使用される。この方法で個の回答を生成し、最適なものを選択するために追加のランキングステップを含む。 まず、生成されたレスポンスに含まれる制御語の単語の数でソートする。複数の回答が最も多くの制御語を生成した場合、モデルからの損失でソートし、最も低い損失
を持つ回答を選択する。
ここでは、ロジット
でモデル化して
個生成した応答のセットである。最終的に生成されたレスポンサート
は、2段階のランク付けプロセスに基づいて選択される。他のアプローチでは、このランキングの要素は含まれていない。
実験のセットアップ
タスク指向対話のデータセット
この問題とアプローチは、一般的な対話制御の設定に適用可能である。我々の実験では、タスク指向の対話で顧客を制御した。これは、現実の顧客を模倣する顧客ロボットを構築するのに有効である。顧客シミュレータを制御することにより(例えば、制御語により)、様々な多様な状況での接客を指導するためのトレーニング環境を開発することができる。すべてのデータセットにおいて、tf-idfに基づいて上位位以内にランクされた単語を選択することにより、顧客の発話から制御語を選択する。実際のアプリケーションでは、制御語をデザイナーが手動で選択することもあります。
MultiWoz 2.3:最初のデータセットとして、対話コミュニティで広く利用されているMultiWoz 2.3(Han et al., 2020)を用いて評価した。このデータセットには、10K以上の対話と5つのドメインがある。
TaskMaster-3:2つ目は、もう一つのよく使われるタスク指向の対話データセットTaskMaster-3 (Byrne et al., 2019)。 このデータセットには、映画チケットのドメインにおける23,757の対話がある。
Action-Based Conversations Dataset(ABCD):最後のデータセット(Chen et al., 2021)は、顧客の問題を解決することに焦点を当てたエージェントと顧客の会話セットである。このデータセットには10k以上の対話が含まれ、また1つのドメインに焦点を合わせている。
ベースライン
:最初のベースラインは、会話の最初の応答ですべての制御語を出力し、その後は何も出力しないナイーブなアプローチであり、単語の出現タイミングが適切に制御されていないことを意味している。
Fine-tuned:このアプローチは、ファインチューンされた言語モデルを使用して応答を生成するだけである。
Prompt:この方法は、promptアプローチ(Li and Liang, 2021; Ribeiro et al, 2018;Jiang et al, 2020; Madotto et al, 2021)に基づいている。 今回はplug-and-playの設定に重点を置いているため、制御語をコンテキストの先頭に追加し、この変更された入力を使って生成します。
Directed Beam Search(DBS):これは制約付きテキスト生成アプローチであり(Pascual et al.,2020)、ロジット修正とビームサーチを使用してキーワードを生成するものである。長期的な制御には最適化されておらず、制御語の順序に大きく依存する。
Metropolis-Hastingsサンプリングによる制約付き文の生成(CGMH):この方法(Miao et al., 2019)は、文中の単語を挿入、削除、置換するストキャスティックサーチに基づいており、制御語が存在する必要があることを要件としている。制御語の長期的な生成や前方生成には最適化されておらず、特に1回の応答で全ての制御語を積極的に生成することに弱くなる。また、元々はキーワードからフレーズを生成するタスクに適用されていたため、言語モデルを対話文脈でプロンプトすることでダイアログ生成に適応し、双方向RNNモデルを我々のトランスフォーマーベースのモデルに置き換えた。
結果
集約結果
各評価指標は、性能の異なる側面を捉えているため、まず、主なベースラインと手法のトップレベルの概要を紹介することにする。表1には、表2、3、図4の主な結果について、タスク、パラメータ、メトリクスごとに平均化されたスコアが示されている。これには、我々が提案した長期成功率と制御語F1スコアの2つの自動測定基準と、人間による品質測定基準の結果が含まれている。次節以降では、これらの結果について、より詳細に検討する。

これらの結果を総合すると、FOPベースの手法は、各指標において常に最高のパフォーマンスを発揮するわけではないが、一貫して最も信頼性の高いシステムであるということがわかる。具体的には、CGMHは成功率が高いが、F1と人手評価のスコアが低い。一方、Promptは、人間による評価スコアは最も高いが、成功率は最も悪い。結局のところ、修正されていない言語モデルなので、人間が見たときに流暢でトピックに沿ったものであるべきである。。しかし、成功率が極端に低いため、長文制御の生成には使えない。一方、FOPベースの手法は、すべての統計データで上位1位か2位を占めている。
長期成功率
最初の分析では、生成されたシミュレーションロールアウトに含まれる制御語の割合を示す長期成功率について、すべての手法を比較する。このために、トレーニングデータセットで別のユーザーモデルをトレーニングする。10個のシステム応答と10個のユーザー応答が生成されたロールアウトのテスト例を実行し、生成されたシステム応答に含まれる制御語の割合を計算する。生成された単語の数を数えるときは、単語ステムを比較する。
図4は、制御語の数を変化させたときの全アプローチの性能を示している。我々のアプローチのバリエーション(FOP-retrievalとFOP-guided)はいずれも、PromptとDBSよりも高い成功率を示している。Promptは最も性能が低い手法であるが、これは、再トレーニングを行わずに制御語を最初に含めると、制御語を生成するのに十分な情報をモデルに提供できないためである。DBSは、制御語の数が少ないときはうまくいくが、制御語の数が増えると苦戦する。これは、DBSが現在の時間ステップで無関係な単語をフィルタリングすることができず、代わりに単語を1つずつ生成しようとするためである。また、この方法では、単語が正確な順序で表示されていない場合に対応することができない。
FOP-retrievalは、場合によってはFOP-guidedよりも、検索されたレスポンスに含まれるすべてのキーワードを正しく取得することができるので、パーフォーマンスが高くなることがある。FOP-guidedは、LMの指示により、これらのキーワードを無視することができる。 そのため、FOP-guidedに比べ、FOP-retrievalはこの指標でより良い結果を出すと予想される。また、付録A.1.1では、FOP-guidedのスライディングウィンドウを移動させた場合の効果を分析するために、アブレーション実験も行っている。CGMHは長期的な成功率では優れているように見えるが、人手による評価の結果、生成された回答はあまり流暢でないことがわかった。この方法は、1つの発話に多くのまたはすべての制御語を凝縮する傾向があるため、以前の評価指標をゲーム化することができる方法である。したがって、これらの手法は、次の評価指標であるPrecision、Recall、F1スコアによって評価するのがよい。
制御語のP/R/F1
次に、Precision、Recall、F1スコアを用いて、各アプローチがどの程度適切なタイミングで制御語を生成できたかを測定する。表2は、すべてのデータセットでこれらの指標を比較したものである。すべてのデータセットで平均すると、FOP-guidedはベースライン手法と比較して高いF1スコアを獲得していることがわかる。これは、類似した未来を検索することで、会話中の適切なタイミングで制御語を生成するよう、言語モデルを誘導することができるためである。FOP-guidedは、MultiWozでは、より多くのドメインを含むデータセットであり、会話のバリエーションが豊富であるため、より悪い結果となった。この多様性により、検索ベースの手法では、生成のガイドとなる類似の会話をうまく見つけることが難しくなる。

ナイーブなアプローチであるは、最初の発話で制御語を出力するだけなので、低いRecallとPrecisionとなる。 CGMHは、
と同様に、自然なタイミングではなく、会話の初期に多くの制御語を生成するため、F1スコアが低くなっている。また、DBSは制御語の順序に大きく影響されるため、これらの評価指標では良い結果を得られなかったが、本手法は類似の未来を検索して現在の時間ステップで適切な語を生成することが可能である。最後に、Promptは、制御語を生成するように明示的に誘導されていないため、Precisionでは良好であるが、Recallでは良好ではない。
人手評価
最後に、すべての手法を人手で評価する。我々は、テキスト生成アプローチの優れた評価方法に関する最近の研究(Karpinska et al, 2021)に従っている。詳細は付録A.4.に示す。
Fluency: 応答は流暢で文法的か?
制御の一貫性:応答に制御語が現れる場合、それらは適切に使用されているか?
関連性:その応答は、会話の中の前の発話に対する自然な返答か?
一貫性:会話中のすべてのシステム応答は、互いに対して首尾一貫しているか?
多様性:システム応答の多様性はあるか?
2人の評価者が各例にアノテーションを行い、5つのメトリクスごとにKrippendorffのalphaを用いて同意度を測定した(0.84, 0.74, 0.82, 0.76, 0.67 )。5つのアプローチすべてと、ground truthの会話について、結果を表3に示す。DBS、CGMH、FOPの3つの手法の比較に焦点を当てる。これらの手法は、コントロールメトリクスで比較可能なパフォーマンス(長期成功率で少なくとも40%)を示したため、長期制御のベースラインとして妥当なものであった。
DBSと比較すると、FOP-guidedは、流暢さ、関連性、一貫性ではほぼ同じであるが、制御一貫性と多様性でははるかに優れている。これは、検索が会話を通して自然に何を言うべきかを決めるのに役立つためと考えられる。FOP-guidedは、関連性、一貫性、多様性についてはFOP-retrievalと同等であり、流暢性と制御一貫性についてはわずかに悪い。これは、FOP-guidedが文脈と検索された文を用いて応答を生成するのに対し、FOP-retrievalは既に流暢な過去の応答を選択するためであると考えられる。全体として、人間による評価結果は、我々の提案する方法がどちらも現実的で首尾一貫したテキストを生成し、同時に高い割合の制御語を生成することを強く示している。
結論
本論文では、制約付き対話生成の問題を提案する。この問題は、会話の将来のある時点で制御語のセットが現れるように、対話応答を制御することを含む。本論文では、将来生成される応答を制御するために、関連する会話の検索を活用する新しい方法と、新しいメトリクスのセットを提案する。我々は3つのデータセットにおいて、我々の方法が定量的な指標と人間による評価において、いくつかの制約付きテキスト生成ベースラインを凌駕することを示す。我々の知る限り、これは対話生成のための長期制御の問題を扱った最初の研究である。