User Satisfaction Modeling with Domain Adaptation in Task-oriented Dialogue Systems
Yan Pan, Mingyang Ma, Bernhard Pflugfelder, and Georg Groh. 2022. User Satisfaction Modeling with Domain Adaptation in Task-oriented Dialogue Systems. In Proceedings of the 23rd Annual Meeting of the Special Interest Group on Discourse and Dialogue, pages 630–636, Edinburgh, UK. Association for Computational Linguistics.
©2022 Association for Computational Linguistics
License: Creative Commons Attribution 4.0 International License(CC-BY)
本記事は、原著の内容に基づき筆者がまとめたものです。以下の図は、そこから引用しています。
This article is my summary based on the content of the original publication. The following figures are taken from it.
要点まとめ
ユーザー満足度推定(USE)は、タスク指向の対話システムの品質を測定するのに役立つ重要なものである。しかし、暗黙的な応答の複雑な性質は、ユーザー満足度を推定する上で課題となり、ほとんどのデータセットはサイズが限られているか、ユーザーのプライバシーポリシーにより一般に公開されていない。
しかしながら、タスク指向の対話とは異なり、大規模なアノテーションが施されたチャットでは、動作ラベルが一般に公開されている。そこで、本論文では、この雑談を利用するための新しいユーザ満足度モデル(USMDA)を提案する。本論文では、対話から文脈を読み取るために、対話トランスフォーマーエンコーダーを用いる。そして、対話に関連する不変的な特徴を学習するために、領域の不一致を軽減する。さらに、USMDAは、ユーザ満足度推定により雑談文脈の満足度信号を、対話行動認識によりタスク指向のダイアログにおけるユーザ行動を共同で学習する。
2つのベンチマークを用いた実験の結果、USEタスクのために提案したフレームワークは、既存の教師なしドメイン適応法を凌駕することが示された。本論文は、雑談からタスク指向対話への教師なしドメイン適応を用いたユーザ満足度推定を研究した最初の論文である。
序論
タスク指向対話システムは、バーチャルアシスタントやドメイン知識を持つ情報探索システムなど、様々なビジネスシーンで大きな成果を上げている(Deriuet al., 2021)。しかし、モデル能力に限界がある対話チャットボットは、クエリを正しく理解できず、誤った回答でユーザーを困らせることがある。ユーザー満足度推定(USE: User Satisfaction Estimation)は、ユーザーの満足度を検出し、システムの戦略を調整することを可能にする。Liuら(2021)は、USEがユーザーのネガティブな感情を推定した場合に、マシンからヒューマンエージェントへのスムーズなハンドオフを実現した。さらに、USEがデプロイ環境で良好なユーザーフィードバックを検出した場合、チャットボットはこの情報を利用して継続的に学習し改善することができる(Hancock et al., 2019)。
近年、対話システムにおけるUSEは常に分類タスクで探求されている。先行研究(Sun et al., 2021; Deng et al., 2022)は、事前学習済みモデルが、タスク指向のコーパスから優れた交換レベル表現を学習し、正しいユーザー満足度を予測できることを示している。残念ながら、ほとんどのユーザー満足度データセットは、サイズが非常に限られている(Saha et al., 2020; Shi and Yu, 2018)か、ユーザーのプライバシーポリシーのために一般に利用できない(Wang et al.)。また、実世界のタスク指向アプリケーションにおいて、ユーザーの満足度を評価するための人間による評価実験やクラウドソーシングを行うには、時間とコストがかかる。
そこで、図1に示すように、我々は人間-人間の雑談(chitchat)と人間-機械のタスク指向対話から2つの対話セッションを収集する。 雑談では、人々は一つの話題について話し、その意図を感情で明示的に表現する。 タスク指向対話では、ユーザとシステムは、ユーザが目的を達成するための行動を明示し、システムはその行動に従って背景知識を利用する。しかし、ユーザは暗黙のうちに感情を表し、目標が達成されることに満足する傾向がある。
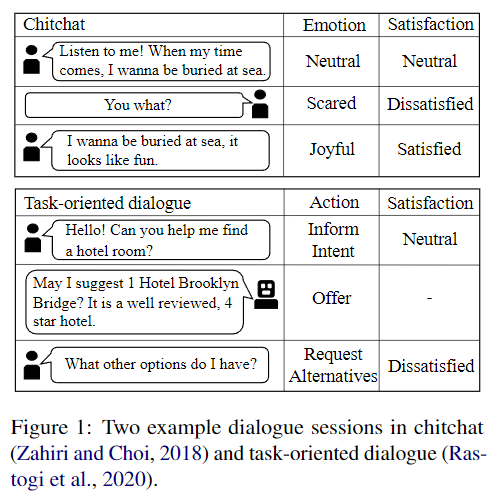
このドメインの違いに対処するため、我々は新しいUSMDAフレームワークを提案し、雑談からタスク指向の対話への教師なしドメイン適応でUSEを実装した。一方では、そのモデルは、チャットとタスク指向の対話データセット間のターン再表現のドメインの不一致を軽減することができる。さらに一方で、このモデルは、雑談の文脈特徴から満足信号(satisfaction signals)を学習し、ダイアログアクト認識(DAR: Dialogue Action Recognition)タスクを追加してタスク指向システムにおけるユーザアクションを学習する。 さらに、このフレームワークは、最も信頼できる予測にラベルを付け、より強力なUSEモデルを構築するために、疑似ラベリングアプローチ(Pseudo-labeling approach)(Lee, 2013)を利用する。我々の知る限り、我々の論文は、雑談からタスク指向の対話へのドメイン適応を伴うUSEを探求する最初の試みである。本研究において、我々は以下の貢献を行う:
その結果、ユーザーアクションや対話に関連する特徴量が、パーベイジングされていないドメイン適応の設定において、USEモデルの性能を向上させることが示された。
2つのデータセットを用いた結果、USEタスクにおける提案フレームワークが、他のドメイン適応アプローチよりも優れた結果を得ることができたことを示す。
問題の定式化
雑談からタスク指向対話にドメイン適応したユーザー満足度推定というタスクを定式化する。雑談とタスク指向の対話セッションのセットが与えられたとき、各セッションは発話
を含む。我々は、
発話を
の交換ターン
に分割する。各交換ターンは、複数のユーザー間、またはユーザーとシステム間のコミュニケーションである。チャットの各交換ターンは、満足度ラベル
で注釈され、タスク指向対話の各交換ターンは、ユーザーアクション
で示される。我々の目標は、ラベル付きチャットデータ
とラベルなしタスク指向対話データ
を用いてUSEモデルを学習し、
の正しい満足度ラベル
を予測することである。
フレームワーク
本節では、教師なしドメイン適応を用いたユーザ満足度モデルの学習方法について紹介する。図2は、我々の提案するフレームワークUSMDAの全体的なアーキテクチャを示し、(1)対話の各交換ターンを表現するための対話トランスフォーマーエンコーダ、(2)USE with DARの共同学習、(3)異なる分布のデータセット間の領域の不一致を軽減、(4)タスク指向対話における疑似ラベルの予測と上位k疑似ラベルを用いたモデルの再トレーニング、の4つの部分から成り立っている。
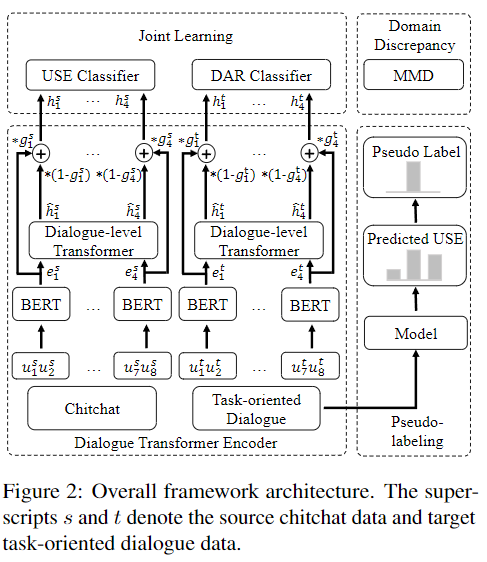
対話トランスフォーマーエンコーダー
雑談とタスク指向の対話サンプルは1つのバッチで混合され、共有バックボーンBERT(Devlin et al, 2019)に供給されて各交換ターン
の交換レベル表現
を抽出する。各
は、交換ターンからの情報を表現する:
共有された対話レベルのトランスフォーマーエンコーダは、2つの対話ウィンドウ内の交換ターンの交換レベル表現をもとに構築される。我々は、会話における文脈情報を捕らえるために、ゲートアテンションメカニズムを持つトランスフォーマーエンコーダを採用する。
ここで、は対話レベル表現、
は2つの異なるレベル表現を結合するための学習済みゲート型注意重み、
は学習可能なマトリックス、
は
の最終的な表現である。
共同学習
このモデルは、USEとDARと共同で学習し、タスク指向のダイアログにおける特定のユーザーアクションを学習する。 USE分類器は、ラベル付けされた満足度クラスとchitchatデータセットの予測値との間の損失を計算する。 DAR分類器は、タスク指向のデータセットにおいて、正しいユーザーアクションを予測することを学習する。共同学習損失は、USE分類器とDAR分類器の損失の合計である:
ここで、はUSEとDARタスクをバランスするハイパーパラメータを示す。
ドメインの不一致
このフレームワークは、最大平均不一致(MMD) (Gretton et al., 2012; Long et al., 2015)を用いて、雑談とタスク指向の対話データセット分布間の距離を測定する。MMDは、ガウスカーネルを用いた2つの対話レベルの表現間の距離、すなわち、を計算するものである。最後に、共同学習損失とMMDを組み合わせて総合損失とする:
ここで、と
は雑談とタスク指向対話の2つの交換レベル表現、
は共同学習損失とMMDをバランスさせるハイパーパラメータ、
は混合バッチ
の大きさである。
疑似ラベリング
ユーザ満足度モデルは、タスク指向の対話から交換ターンのたびに、満足度予測
を行い、ドメインの不一致を低減する。予測値の信頼性は予測スコアで測定する。 図3に示すように、事前予測スコアの高い上位k個のインスタンスは、再学習のための擬似ラベルとして設定される。
実験
データセットと評価指標
我々は、雑談データセットEmoryNLP (Zahiri and Choi, 2018) とMultiWOZ 2.1(MWOZ) (Eric et al., 2020)とSchema Guided Dialogue (SGD) (Rastogi et al., 2020)の二つのタスク指向データセットで提案フレームワークを実施する。さらに、Sun et al. (2021)による5段階の満足度スケールで注釈された、MWOZとSGDの各データセットからサンプリングされた1000個の対話を使用する。雑談の7つの感情とタスク指向の対話データセットの5つの評価スコアは、既存の研究(Deng et al., 2022; Zahiri and Choi, 2018)に従って「不満足/中立/満足」の粗視化ラベルにマッピングされる。DARタスクについては、MWOZデータセットにはEricら(2020)による21アクション、SGDデータセットにはRastogiら(2020)による12アクションのラベルが付与されている。EmoryNLPデータセットをラベル付きソースデータセットとして使用し、タスク指向対話データセットのそれぞれから300の対話文をラベルなしターゲットデータセットとしてランダムに選択する。会話における感情認識に関する多くの既存研究に従い、USEの性能を評価するために、Macro-F1とMicro-F1のスコアを報告する。Macro-F1はクラスごとのF1の平均をとり、Micro-F1はクラスの寄与を集約したF1を算出する。
他のモデル
BERTモデルをベースラインモデルとし、提案手法のバックボーンとして使用し、徹底的な比較を行う。 タスク指向対話の事前学習や異なる教師なしドメイン適応方法を持つ以下の関連モデルが実装されている。
ToD Bert (Wu et al., 2020)は、9つのタスク指向対話データセットでマスクドラングエッジモデリング戦略と応答選択タスクで事前学習する。
WDGRL (Shen et al.,、 2018)は、敵対的戦略で経験的なワッサーシュタイン距離を短縮することにより、ドメイン不変の表現を学習する。
DANN(Ganin et al.、2016)は、ドメイン適応で差別化できない特徴を学習するためにドメイン敵対的訓練を使用している。DANN法は自然言語処理における教師なしドメイン適応タスクに最も広く利用されている。
結果と分析
総合的パフォーマンス
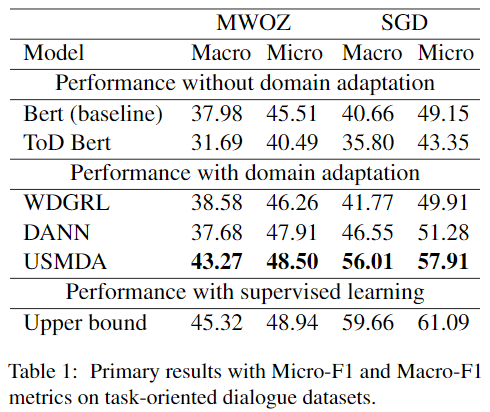
表1は、以下のモデルを含む主要な実験結果を示している:(1)ソース雑談データセットのみを使用したベースラインモデルとToD Bert、(2)ドメイン適応戦略とターゲットデータからユーザーアクションにアクセスする複数のモデル、(3)タスク指向データセットを上限として教師あり学習したBERTベースモデル。
我々は以下の注目すべき見解を得た。
(1) 我々の教師なしドメイン適応戦略はUSEについて2つのタスク指向対話データセットでパフォーマンスを改善するのに効果があった。USMDAは、Macro-F1においてMWOZで5.29%、SGDで15.35%、Micro-F1においてMWOZで2.99%、SGDで8.76%の性能向上を達成した。提案したフレームワークUSMDAは、USEの雑談からタスク指向の対話へのドメインシフト問題を解決することに成功した。USMDAは、タスク指向のデータで満足ラベルを持たない場合、MWOZでMicro-F1 48.50%を達成し、これは教師あり学習による上限モデルに匹敵する。
(2) 我々のフレームワークUSMDAは、2つのデータセットでドメイン適応による最高の性能を達成した。平均して、ドメイン適応を行ったモデルは、ベースラインモデルよりも性能が高い。これは、ドメインに依存しない対話関連の特徴が、ユーザ満足度モデルの性能を向上させることを示唆している。他のドメイン適応アプローチと比較して、USMDAは比較的大きな改善をもたらす。ドメイン不変の対話関連特徴を学習する我々の提案フレームワークUSMDAが、WDGRLやDANNよりも効果的であることが実証された。
(3) ToD-BERTは、9つのタスク指向の対話データセットで事前学習されているにもかかわらず、USEタスクでは、ドメイン適応なしでも満足のいく結果を得ることができなかった。 ToD-BERTは9つのタスク指向対話データセットで事前学習されているにもかかわらず、USEタスクにおいてドメイン適応なしでのパフォーマンスは劣る。ドメイン適応なしの不満足な結果は、タスク指向対話におけるUSEには特定のドメイン特徴が貴重で必要であることを示している。
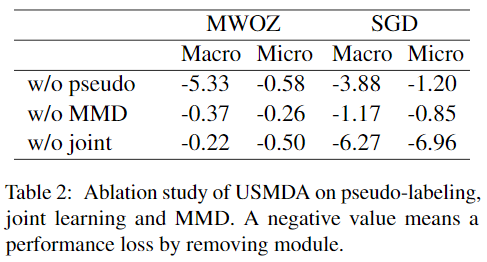
アブレーションスタディ
ドメイン適応戦略における各パーツの影響を理解するために、提案するフレームワークの3つの簡略化されたモジュールについてアブレーション研究を実施した(表2参照)。 その結果、どのモジュールを削除しても、性能が低下することがわかった。 共同学習を削除すると、Micro-F1ではSGDで6.96%という最も大きな損失が発生した。これは、対話中のユーザーの行動がユーザーの満足度を反映し、タスク指向の対話において重要な対話関連の特徴であることを示す。 MMDを落とすと、SGDではMacro-F1が1.17%、Micro-F1が0.85%性能低下するため、MMDを用いた伝達可能特徴の学習は有益である。さらに、擬似ラベルを削除すると、3.9-5.3% Macro-F1、0.6-1.2% Micro-F1の性能が低下し、USEタスクに対するデータ中心アプローチの利点が示された。
考察と今後の課題
カーネル化手法のMMDと比較して、WDGRLとDANNは敵対的な学習ストラテジーであることがわかる。 表1より、WDGRLはモデル性能をわずかに向上させるだけであり、DANNは必ずしも目標のドメイン性能を向上させるものではないことがわかる。 従来の敵対的学習ストラテジーは、事前に学習された言語モデルで効果を得られないことがあるが、単純なMMDはドメイン不変の特徴を効率よく学習することができる。提案するフレームワークは、2つの固定データセットで印象的な結果を達成した。 今後、このフレームワークを実生活の場面で評価する予定である。